

[!] この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
クラウド環境で使われるストレージ
AWS・GCP・Azureといったクラウドサービスでは、用途に応じて様々なタイプの仮想化されたストレージが提供されています。クラウド環境から仮想ストレージを利用する場合、主な選択肢としては以下の3つが挙げられます。
| 種別 | メリット | デメリット | 主な用途 | 代表例 |
|---|---|---|---|---|
| Fileストレージ | - OSの標準機能で読み書きが可能 - 複数クライアントから同時に利用可能 | - OSのインストール先として使えない - 拡張に制約が多い | - ネットワーク共有ディスク | Amazon EFS |
| Blockストレージ | - 細かいデータの頻繁な読み書きが得意 | - 導入・運用のコストが高い | - データベース用データ領域 - 仮想ディスクボリューム | Amazon EBS |
| Objectストレージ | - 拡張が容易 - 複数クライアントから同時に利用可能 | - 書き込んだデータを後から変更できない(一度削除するしかない) | - ファイルアップローダー | Amazon S3 |
このうち、クラウドでの利用例が多いのは拡張性に優れたBlockストレージとObjectストレージですが、特にクラウドで動作する仮想マシンのディスクドライブ用途としては、Blockストレージから一定容量のボリュームを切り出して利用する方式が多く取られます。
このとき、仮想マシンの収容数の増加に伴ってボリュームを提供するBlockストレージの使用量も増えるため、ストレージの拡張が必要となります。
この記事では、Cinder+CephというOpenStackで構築したクラウド環境における典型的構成のBlockストレージについて、実際のサーバー単位でのスケールアウト事例を通して拡張の手順や構成の解説を、数回にわけて行っていきます。
初回は、増設のための前提知識として、Cephにより構築されたBlockストレージの基本的な仕組みについて説明します。
Blockストレージの概要
Blockストレージは、ハードディスクなどと同様に、書き込まれたデータを一定サイズの「ブロック」単位で格納・管理する仕組みを持つことが名前の由来です。
言い換えれば、Blockストレージとは複数のサーバーやディスクを組み合わせて巨大なハードディスクをエミュレーションする仕組みということもできます。
Blockストレージの実体は、データ保存用のサーバーをネットワークで相互に接続したクラスターです。それぞれのサーバー上では、以下のサービスが動作しています。
| サービス | 役割 | 代表例 |
|---|---|---|
| ボリュームサービス | ストレージからボリュームを切り出し、仮想マシンに提供する | Cinder |
| ストレージサービス | 複数のディスクをまとめてストレージとして管理し、データの読み書きを制御する | Ceph |
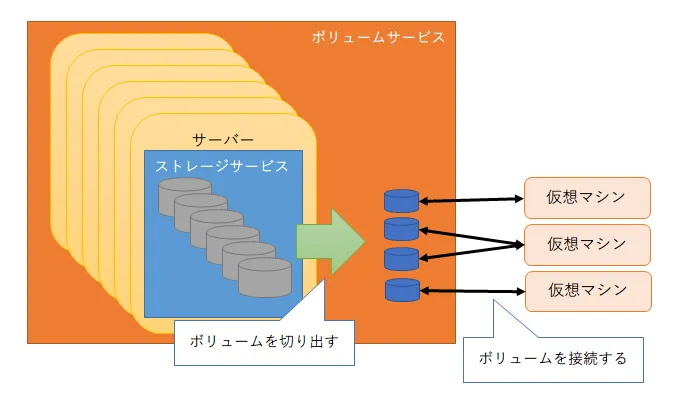
ボリュームサービスが提供するボリュームは、仮想マシンからはディスクドライブと同等に扱えます。USBハードディスクのようにデータ保存領域として利用するほか、システムドライブとしてOSをインストールすることも可能です。
Blockストレージ上のボリュームに仮想マシンのOSをインストールすると、以下のメリットが生まれます。
- ホストサーバーの内蔵ディスクと違って容易に拡張できるため、多くの仮想マシンを収容しやすい
- 仮想マシン同士で簡単に繋ぎ替えができるため、可搬性や耐故障性が向上する
- 仮想マシンの移設時、ホストサーバー同士で仮想ディスクのファイルをコピーする必要がない
- 仮想マシンのホストサーバが故障しても、別の健在なサーバーに仮想マシンをコピーしてボリュームを繋ぎ替えれば復旧できる
一方で、ネットワークを介してディスクにアクセスするため、読み書きの速度はホストサーバー内蔵のディスクを利用する場合(特にホストの内蔵ディスクがストライピング型のRAIDを組んでいる場合)に比べて遅くなる傾向があります。
ストレージサービス「Ceph」の概要
OpenStackで構築されたクラウド環境では、ストレージサービスとしてオープンソースのCeph(セフ)がよく用いられます。
Cephは、Blockストレージに保存されたデータを「オブジェクト」というデータ単位(前述の「ブロック」相当)に分割し、それぞれを複数のディスクに分散・複製して格納します。
ソフトウェアとしてのCephの実体は、MON(Monitor)およびOSD(Object Storage Device)と呼ばれる2種類のサービスのデーモンがそれぞれ複数集まって形成したクラスターです。
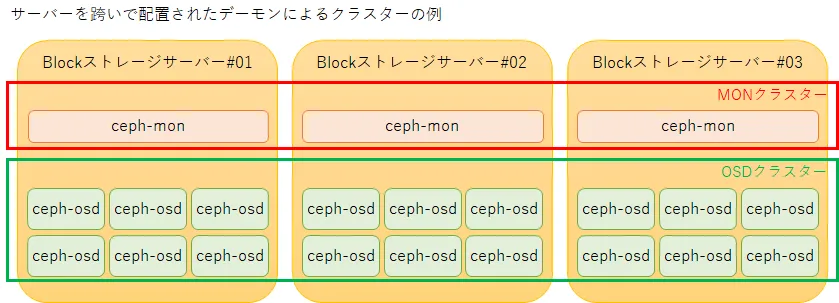
動作やデータの健全性をモニターする「MONデーモン」
MONデーモンは、Cephストレージ全体の動作状態・データ状態の健全性を監視する役割を持ちます。
また、Cephストレージへのデータの読み書きがリクエストされた際に、対象のデータがOSDクラスター上のどの位置にあるか(どの位置に書き込むべきか)を管理・案内します。
この目的のためにMONデーモンは、OSDクラスターの設計図である「CRUSHマップ」と呼ばれる情報を保持し、クラスター内のデーモン同士で共有しています。

CRUSHマップは、OSDクラスターを構成するメンバーを階層構造で一覧し、書き込まれるデータの分散の仕方をコントロールします。
ストレージデバイスを管理する「OSDデーモン」
OSDデーモンは、それぞれ1つのOSD(ディスクドライブまたはボリューム)の管理を担当し、実際のデータ読み取り・書き込み処理を行ったり、他のOSDに対する相互死活監視やデータ整合性チェックを行います。
分散したデバイスをまとめる「PG」
Cephのデータ管理の仕組みとして、書き込まれたデータを一定サイズ(通常は最大4MB)ごとに「オブジェクト」に分割し、それぞれ複数個のレプリカ(複製)を作成した上で、別々のOSDに分散して格納します。
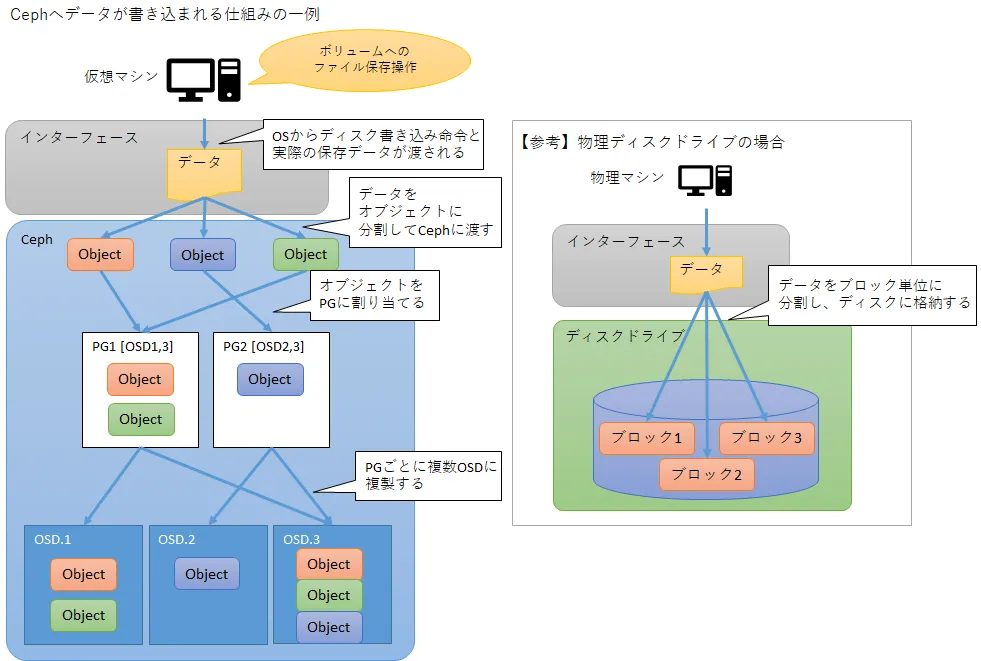
このレプリカ同士を分散格納するOSDの組み合わせのことを、PG(Placement Group)と呼びます。
PGはCephクラスターを作成した時点で、予め指定した数が用意されています(ストレージの拡張に合わせて後から追加することも可能です)。Cephストレージにデータを書き込む際、書き込まれるオブジェクトには格納先のPGが割り当てられ、そのPGを構成するOSDに対してオブジェクトとそのレプリカが書き込まれます。
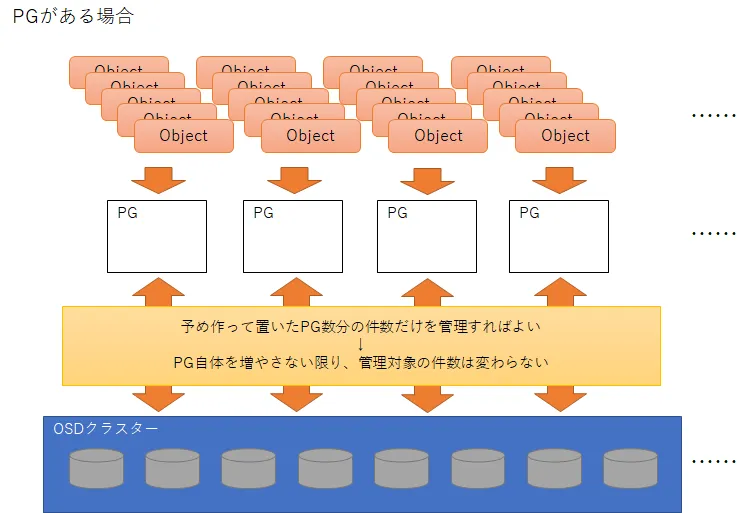
PGはオブジェクトとOSDの間を仲立ちして、オブジェクトをある程度の固まりに集約することにより、オブジェクトの管理を大幅に簡略化する役割を持ちます。
もしPGがないと、OSDが管理すべきデータ(オブジェクト)の分量は、格納されたオブジェクトが増えれば増えるほど膨れ上がっていきます。

これに対し、PGの単位でオブジェクトを集約すると、データ増大がある一定限度(OSD増設に伴ってPGの追加が必要となるタイミング)に達するまでは、予め決められたPG数の件数だけデータを管理すればよいことになります。
なお、データの耐障害性を担保するために、CRUSHマップ上で同じホストに属するOSD同士ではPGを作成しないようになっています。
次回予告
ここまで、Blockストレージの概要およびCephの基本的な仕組みについて説明してきました。Blockストレージのサーバー増設にあたっては、今回の説明に登場した各種の要素(サービス、デーモンなど)を新しいサーバーに設定し、それらを既存のクラスターに参加させるのが主な作業内容となります。
次回は、Cephクラスターを用いた既存のBlockストレージに、サーバーを増設してスケールアウトする際の計画や手順の考え方を、今回説明したCephの仕組みと照らし合わせて解説していきます。
