

[!] この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
サーバーやネットワーク機器が出力するシステムログには、様々な情報が記録されています。一般的な設定だと、ローカルディスクに書き出されて、容量等の都合で古いものから消えていきます。そこで、ログに記録された情報を長いスパンで扱えるように、ログをクラウドに集約する仕組み(ログ管理システム)を構築しました。
概要
主な要件と重視したポイント
ログ管理システムを構築するにあたって、以下の点を重視しました。
- Linuxサーバーのログだけでなく、Windows Serverのイベントログやネットワーク機器のログも保管したい。
- 当面の収集対象機器は100台規模だが、将来的にはクラウド上の仮想サーバーの利用拡大が想定され、拡張しやすくしたい。
- システムログには機微な情報が含まれている可能性もあるため、インターネット経由よりはVPN経由で送りたい。
- ログをリアルタイムで確認する使い方は想定されない。ホスト単位で一定期間を指定して検索する使い方が多いと考えられる。
こうした点を踏まえて、ハイスペックなログ管理サーバーを構築せずに、サーバーレスアーキテクチャで構築することにしました。
全体構成
ログ保管システムは、大きく分けて3つのブロックで構成されています。
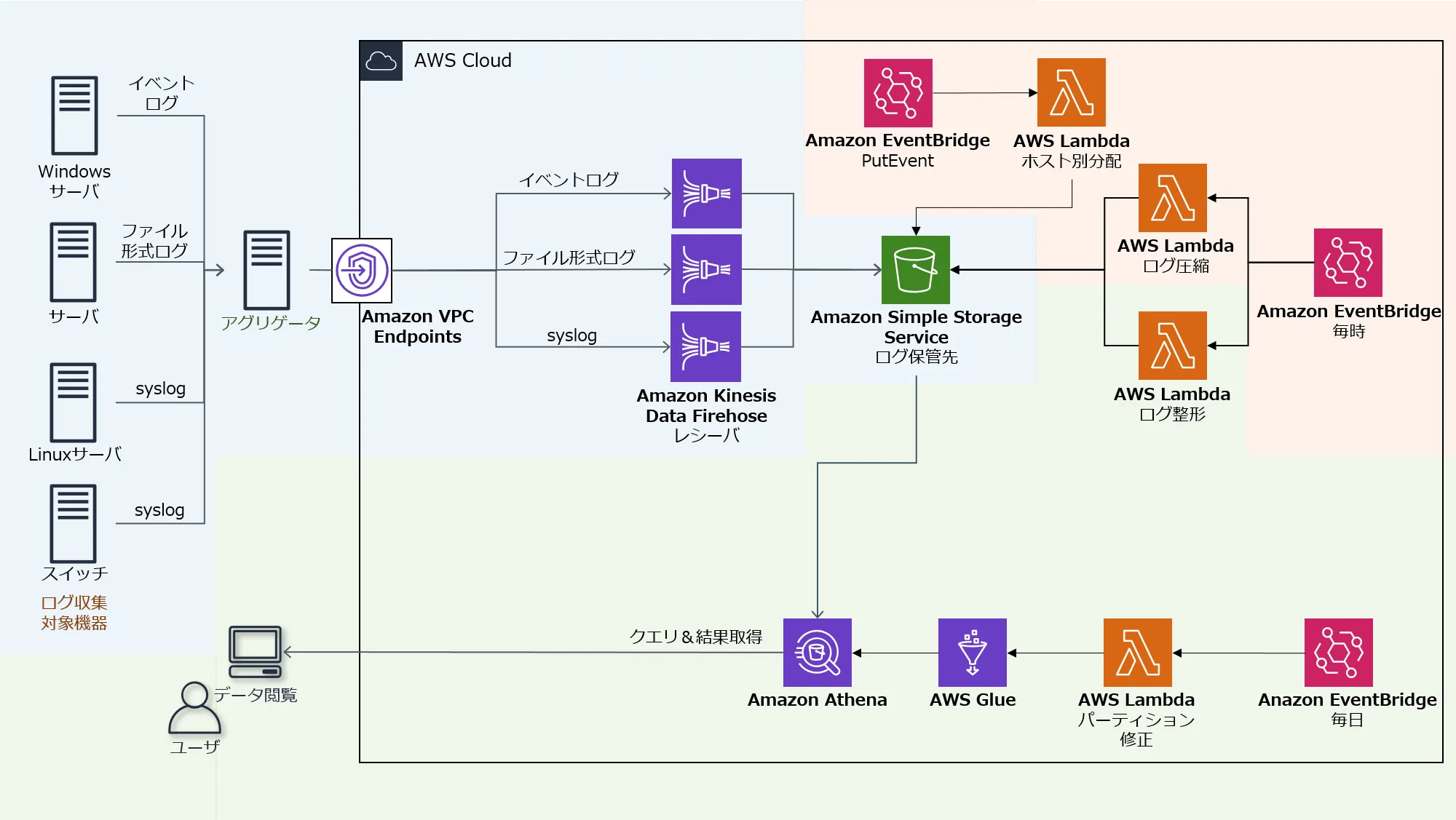
| 役割 | エリア | 説明 |
|---|---|---|
| ログ収集 | 青 | ログを転送し、ストレージに格納する |
| ログ圧縮 | オレンジ | ストレージに格納した生ログを圧縮して保管する |
| ログ閲覧 | 緑 | 検索・集計用にログを整形し、閲覧可能にする |
ログ収集
ログ収集の部分は、以下の構成となっています。
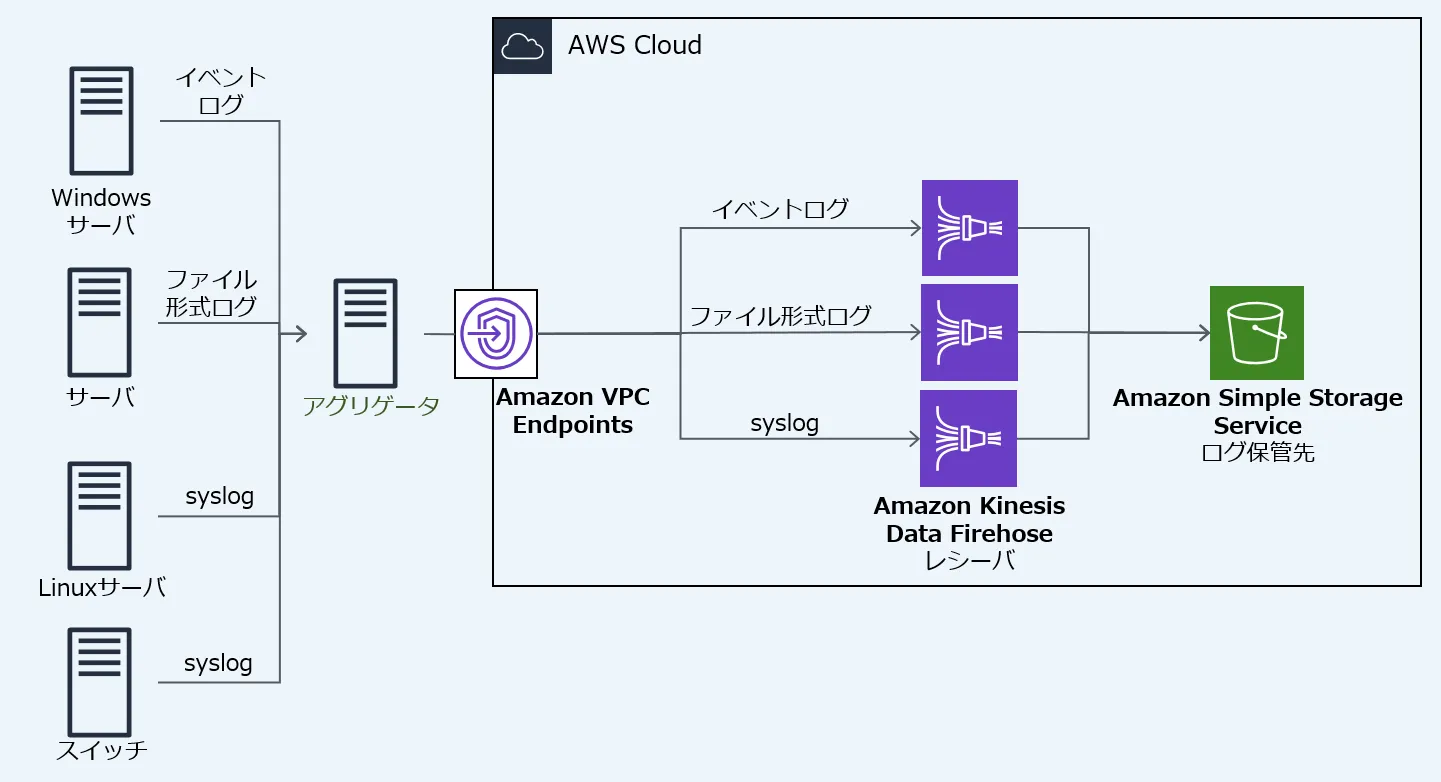
ログの保管先
ログの保管には、オブジェクトストレージサービスである Amazon Simple Storage Service(以降、S3)を利用します。ログ保管先の S3 バケットを作成し、データストリームからの一時保管先、1時間毎に圧縮した生ログ、閲覧用の整形ログを別途保管するため、オブジェクトのプレフィックスでディレクトリを分けておきます。
s3のバケット ├ temp/ : データストリームからの一時保管先(配置から1週間で削除) ├ rawlog/ : 1時間毎に圧縮された生ログの蓄積先(配置から3年で削除) └ processedlog/ : 検索性向上のための整形済ログの蓄積先 (配置から3年で削除)ログデータストリーム(レシーバ)
ログの一時受け取り先として、データストリームサービスの Amazon Kinesis Data Firehose (以降、Firehose) のストリームを作成します。Firehose は受信したログを定期的に S3 に送信しデータを保管します。
今回は syslog、イベントログ、ファイル形式ログの3つを取得し、保管先を細かく分類したいため、それぞれ別のストリームを作成しています。ログ保管先は先ほど用意した S3 の temp を指定して保管します。
s3のバケット └ temp/ : データストリームからの一時保管先 └ firehose/ ├ syslog/ : syslog ├ eventlog/ : イベントログ └ filelog/ : ファイル形式ログ当社が構築したログ管理システムでは、リアルタイム性は重視されず、ログ収集対象機器の将来的な増加も想定してFirehose を採用しています。
VPCエンドポイント
オンプレミス機器のログを収集するにあたって、ネットワークに関する懸念点があります。
- インターネット経由でレシーバにログを送ると、社内ネットワーク上で経由するWebプロキシサーバの負荷が懸念される。
- システムログには機微な情報が含まれている可能性もあるため、素のインターネット経由で流すよりはVPN経由で送りたい。
当社ではオンプレミスネットワークとAmazon VPCをVPNで接続していたことから、 Firehose用VPC Endpoint を立てることでインターネットを経由させない作りにしました。
アグリゲーター
収集対象機器からクラウド上のレシーバへ直接ログを送ると、以下の点が懸念されます。
- すべてのサーバーで、レシーバのAPIにアクセスするための資格情報(シークレットアクセスキー)を設定する必要がある。アクセスキーの扱い方として難しさが否めず、将来的にクラウド側の構成を変更する場合(例えばレシーバをFirehoseからKinesis Data Streamに変更する)、全台で設定を修正することになる。
- ネットワーク機器のログ送信は、一般的にsyslogプロトコルしか対応していない。
そこで、アグリゲーターを用意して、収集対象機器は対応プロトコルでアグリゲーターに送信し、アグリゲーターがHTTPSでレシーバーに送るようにします。 アグリゲーターとしては、オープンソースのログ収集ツール Fluentd(td-agent)を利用します。導入するプラグインは下表の通りです。
| プラグイン名 | プラグインの役割 |
|---|---|
| aws-fluent-plugin-kinesis | Kinesis サービスへの送信用プラグイン。Firehose だけではなく、Kinesis Data Streamsにも利用可能 |
| fluent-plugin-beats | イベントログの収集に winlogbeat を利用しており、winlogbeat から送信されたログを Fluentd で受け取るためのプラグイン |
ログ収集用クライアント(ログコレクタ)
ログ収集対象のサーバーには、ログコレクタをインストールします。ログの種類ごとに、使用するコレクタも異なります。
| ログの種類 | ログコレクター |
|---|---|
| syslog | rsyslog |
| イベントログ | Winlogbeat |
| ファイル形式ログ | Fluentd(td-agent) |
以上で、アグリゲーターがログ収集対象のサーバーからログを収集し、クラウドのエンドポイントを経由して、データストリームからストレージに書き出していくログ収集基盤がオープンソースソフトとクラウドで実装できます。
ログ圧縮
サーバーやネットワーク機器からクラウドのレシーバに送られてきたログは1分毎に S3 に一時保管しています。このままだと、細かく分断されたログファイルが大量に配置され、検索性には優れません。そこで、1時間に1度ログファイルを結合・圧縮し、別のディレクトリ(/rawlog)に再配置します。
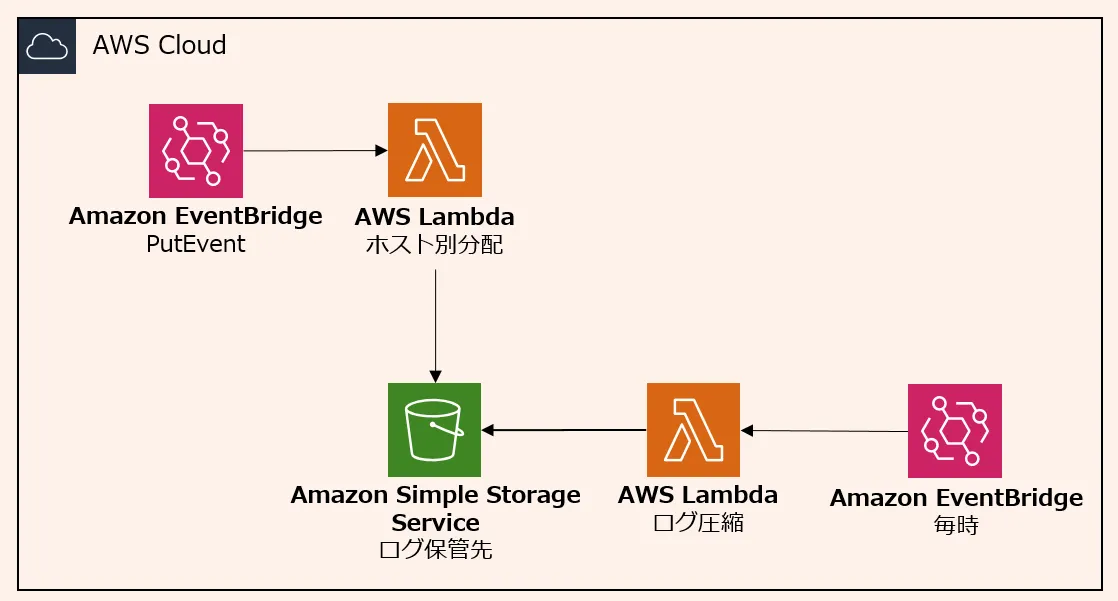
ログ分類
ログが結合・圧縮され再配置されるタイミングで、以下のように分類等を実施します。
- 前述のプレフィクスを除く第一階層でホスト別に分類
- 第二階層でログの種類別(syslog はファシリティ、イベントログはセキュリティ、システムなどのロググループ)に分類
- タイムゾーンをJSTに変更
分類には、Amazon EventBridge(以降、EventBridge)と AWS Lambda (以降、Lambda) を利用します。
分類前
s3のバケット └ temp/ : 一時保管先 └ firehose/ └ syslog/ └ 2020/ : 年(UTC) └ 03/ : 月(UTC) └ 25/ : 日(UTC) ├ 00/ : 時(UTC, JSTで9時) │ ├ 2020-03-25-00-00-01.gz │ ├ 2020-03-25-00-01-05.gz │ ├ 2020-03-25-00-02-03.gz │ ├ … │ └ 2020-03-25-00-59-01.gz ├ 01/ : 時(UTC, JSTで10時) ├ …
----分類後(時刻がJST化され、ホスト別、ロググループ別になったため、検索性が向上)
s3のバケット └ temp/ : 一時保管先 ├ firehose/ └ byhost/ : ホスト別のディレクトリを追加 └ syslog/ └ 2020/ : 年(JST) └ 03/ : 月(JST) └ 25/ : 日(JST) └ 09/ : 時(JST) ├ server_1/ : ホスト名 │ ├ Cron/ : ロググループ │ │ ├ 2020-03-25-09-00-01-server_1-Cron.gz │ │ ├ 2020-03-25-09-01-05-server_1-Cron.gz │ │ ├ 2020-03-25-09-02-03-server_1-Cron.gz │ │ ├ … │ │ └ 2020-03-25-09-59-01-server_1-Cron.gz │ ├ Daemon/ │ ├ … ├ server_2/ ├ …ログ圧縮
EventBridge と Lambda を利用して、圧縮します。
s3のバケット └ rawlog/ : 1時間毎に圧縮された生ログ保管先 └ server_1/ : ホスト名 └ Cron/ : ロググループ └ 2020/ : 年(JST) └ 03/ : 月(JST) └ 25/ : 日(JST) ├ 20200325-0900-server_1-Cron-00.log.gz └ …なお、上述のような細かい分類のため、1時間毎に圧縮したログファイルでもファイルサイズが数MB規模にとどまります。分類は、検索のユースケースを考慮して、後述のパーティショニングによるスキャン量抑制を目的としていますが、ファイルサイズを128MB以上にまとめるのがAthenaでは推奨されているため、改善の余地があります。
ログ閲覧
ログの検索には、 SQLクエリサービスのAmazon Athena(以降、Athena)を利用します。
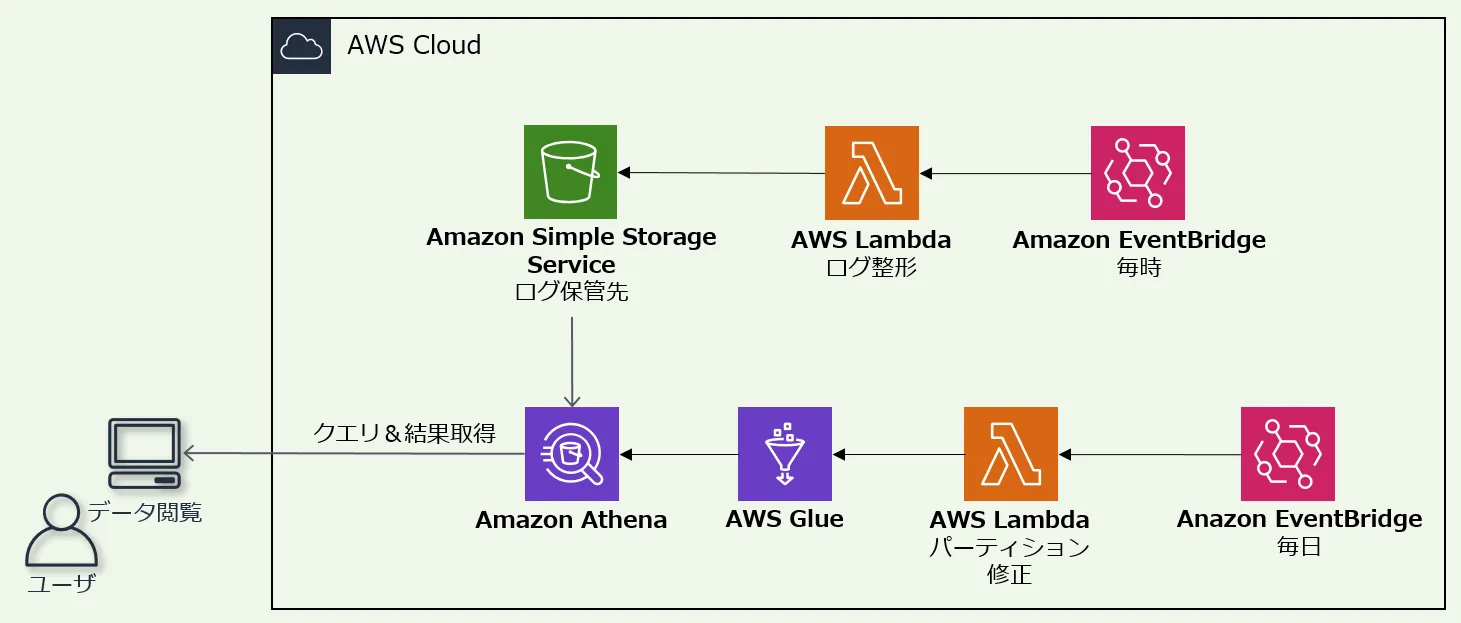
ログ整形
Athena はクエリ実行時のデータスキャン量に基づいて料金計算が行われるため、ログ圧縮で圧縮したログをそのまま利用するとコストがかかります。そのため、保管されているログに以下の整形処理を行います。
- Snappyでファイル圧縮
- 列指向データ化(Parquet化)
- パーティションの設定
EventBridge と Lambda を利用して、1時間に一度、整形しています。
Snappyでファイル圧縮
ファイルを圧縮するとデータスキャン量は圧縮後のサイズで料金計算が行われるため、コストメリットも期待できます。例として、無圧縮、Snappy、 gzip で圧縮率と展開時間を比較してみました。圧縮率は gzip が高いものの、圧縮・展開に時間がかかり、Lambda 関数での整形処理や Athena のクエリ実行が遅くなります。このため、圧縮率よりも圧縮・展開速度を重視して Snappy で圧縮しています。
![]()
列指向データ化
列指向データに変換することで、スキャン対象を絞ることができます。
例えば、図のテーブルからdate(2020/3/22 のみ), action, user のカラムを取り出す際、一般的な行指向データの場合は各行の全カラムを取得するため、全カラムへのアクセスが必要になります(図中の緑)。これを列指向データに変換しておくことで、必要な部分だけがスキャンされ、スキャン量の低下と検索速度の向上が図れます(図中の橙)。
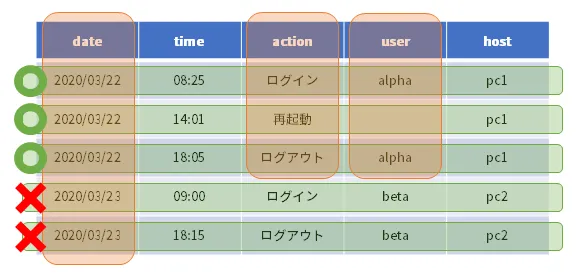
今回のログ管理システムでは、列指向フォーマットとして、Apache Parquetを採用しています。
パーティションの設定
パーティションを設定することで、オブジェクトのプレフィクスを検索条件にすることができます。
例えば、2020年のログを取得した場合、パーティションを設定していなければ、クエリの WHERE句等で timestamp から年月を比較して抽出するため、すべてのログファイルをスキャンする必要があります。
一方、パーティションが設定されており、S3 の保管先が S3://bucket/host=pc1/user=alpha/year=2020/.../hoge.log の場合、オブジェクトのプレフィクスが year=2020 となっているログファイルのみがスキャン対象となり、検索対象を削減できます。
パーティション情報は更新が必要なため、EventBridge と Lambda で毎朝処理しています。
まとめ
100台規模のサーバーやネットワーク機器のシステムログをクラウドに集約する仕組みを紹介しました。現在のところ、安定稼働してログを保管できています。ログの長期保存は、突発的なシステム障害やインシデント時に調査するためというよりは、後になって判明した問題点を過去にさかのぼって調査するための手がかりとして重要です。クラウドのストレージに保管することで、拡張性と柔軟性が期待できます。細かい課題はありますが、運用を続けてデータの活用を深めていきたいと思います。
参考文献
記事の執筆にあたっては情報の正確性に努めておりますが、掲載されている文章やソースコード、設定ファイル等の内容について、完全な正確性や安全性を保証するものではありません。活用される際は、必ず公式ドキュメント等をご自身で確認のうえご判断ください。
