

[!] この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
基礎知識編では、前提知識としてCephによるBlockストレージの基本的な仕組みについて解説を行いました。今回は、実際のストレージ増設の事例における、増設の計画や手順について説明します。
なお、本記事で紹介する事例は、既存のBlockストレージにハードウェアを増設する手順となります。ストレージ自体の新規構築は取り扱いませんのでご了承ください。
増設前の環境構成
OpenStack環境
今回増設を行うのは、下図に示すOpenStackを基盤に用いて構築したクラウド環境です。
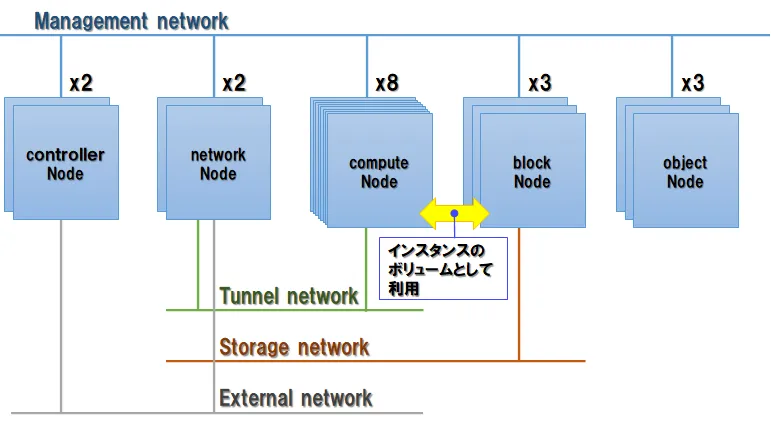
図中、それぞれのノード(サーバー)は以下の役割を持っています。
| ノード種類 | 台数 | 役割 |
|---|---|---|
| controller | 2 | クラウド全体の制御・管理など各種機能を司る |
| network | 2 | クラウド内部の仮想ルーター・ゲートウェイ機能を提供する |
| compute | 8 | 仮想マシンを収容し、CPU・メモリなどのリソースを提供する |
| block | 3 | Blockストレージサーバー |
| object | 3 | Objectストレージサーバー |
なお、用語「ノード」と「サーバー」は意味合いにおいてほぼ同等の要素に対応しますが、以降の本文中では下記の整理とします。
- OpenStackやCephなどのシステム/サービスの一員としての機能・役割を含めて表す場合、「ノード」と呼称します。
- 単体の物理的・論理的なコンピューターとしての対象を表す場合、「サーバー」と呼称します。
また、図中に示したネットワークは以下の通り区分されています。
| NW区分 | 速度 | 役割 |
|---|---|---|
| Management | 1Gbps | 各ノード/サーバーの管理作業に用いるほか、Blockストレージ/Objectストレージのデータ入出力に使用する |
| Tunnel | 10Gbps | 仮想マシン上のゲストOSが使用する。networkノードを経由して外部ネットワークとの通信も可能 |
| Storage | 10Gbps | Blockストレージを構成するblockノード同士のデータ同期やレプリケーションに使用する |
| External | 100Mbps | クラウド環境外のネットワーク |
Blockストレージ環境
本環境のBlockストレージは、ボリュームサービスにCinder、バックエンドのストレージにCephを用いて構築しています。
Blockストレージの主な構成は、以下の通りです。
表を開く/閉じる
| 項目 | 構成内容 |
|---|---|
| 合計ディスク容量 | 32.4TB |
| レプリケーション数 | 2 |
| 合計実効ディスク容量 | 16.2TB |
| OpenStackバージョン | Pike |
| Cinderバージョン | 11.1.0-1 |
| Cephバージョン | Jewel |
各blockノードは以下の構成で、3台全て同じスペックです。
表を開く/閉じる
| 項目 | 構成内容 |
|---|---|
| サーバーCPU | Xeon E3-1220 x1(3.1GHz 4C4T) |
| サーバーメモリ | 8GB |
| サーバーOS | CentOS 7.3 |
| システムディスク | 300GB x2(RAID1) |
| OSD用ディスク | 1.8TB x6(合計10.8TB) |
| OSDファイルシステム | XFS |
| ディスク搭載上限 | 8台(空き0) |
各blockノード上では、MONデーモン1つとOSDデーモン6つが動作しています。

増設内容の検討
以下、Blockストレージの増設構成を決めていきます。
増設容量
まず、今回の増設作業によってどれだけの容量のディスクを追加する必要があるか検討します。
今回は、実効容量(仮想マシンにボリュームとして提供できる容量)を5TB追加する場合を例とします。実効容量に対するディスク容量は、
ディスク容量 = 実効容量 × レプリケーション数で求められます。
よって、今回増設するディスク容量は、最低10TB以上であればよいことになります。
スケールアップかスケールアウトか
次に、増設の方法としてスケールアップ(個々のサーバーのリソースを増強する)とスケールアウト(サーバーそのものを増設する)のどちらを取るかを決定します。
具体的には、スケールアップの場合は現在運用中のサーバーにディスクを追加することになり、スケールアウトの場合は4台目以降のblockノードを追加することになります。
前掲のblockノード構成より、運用中のblockノードにディスクを追加できる物理的な余地がないため、今回はスケールアウトを前提として増設の計画を立てていきます。
ハードウェア構成の決定
増設すべきディスク容量が決まったところで、この容量をどのようなハードウェア構成とするかを検討します。
現状使用しているblockノードのサーバー1台あたりのディスク容量は10.8TBですので、単純に考えるならば同じサーバー構成のノードを1台増設すればよいことになります。
とはいえ、将来ふたたび増設が必要になる可能性を考えると、今のうちにもっと容量の大きなサーバーを増設する選択肢はないでしょうか?
たとえば一台のサーバーにより多数のディスクを搭載すれば、それ以外のCPU・メモリといったリソースを、容量に対して少ない数に集約することができ、導入価格や消費電力などのコスト削減につながります。また、現行よりもディスクあたり容量の大きなサーバーを導入する方法もあるでしょう。一見して魅力的な案に思えます。
ですが、そうするべきではない理由があります。
一部ノードだけディスク容量を増やした場合の問題点
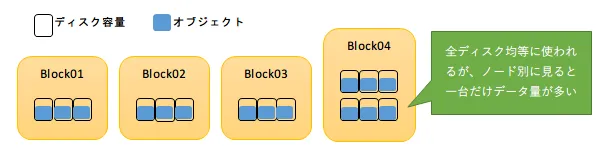
Cephの設定の仕組みとして、ディスクにデータ書き込みを行うペースの指標であるウェイト値がCRUSHマップに定義されています。標準設定においては、全てのディスク使用率が均等に増加するよう容量に応じて決定されます。
これに従えば、Cephクラスターを構成する全てのディスクの容量は均等に使われていくことになり、一見して何の問題もなさそうに思えます。
ところが、このような構成は運用上の不都合を招く危険があります。理由は、全てのディスクが均等に使われた結果、下図のようにディスク数が多いサーバーに集中してデータが格納されていくためです。
次の図のようにクラスターを構成するディスクの一部が故障した場合、残されたディスクは故障したディスクが持っているデータと対になるレプリカを元に、健在なディスクに複製を行ってデータの冗長性を回復しようとします。
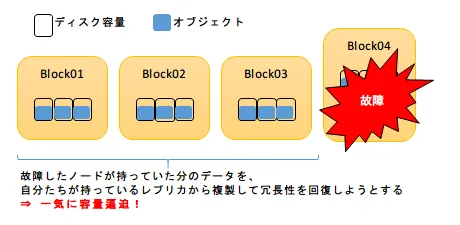
この処理は時間・処理負荷ともに大変コストが高く、最悪の場合は長時間にわたってBlockストレージ自体が読み書き不能となってしまいます。また、ノードごとに持っているデータ量があまりに偏っている場合、新たに複製されたデータで容量が逼迫する危険もあります。
これらの影響をできるだけ軽減するためには、クラスター全体に対して個々のディスク/サーバーが持っているデータ量の割合はできるだけ均等かつ少ない方が望ましく、一部だけ大量のデータを持ったサーバーが存在することは、サービス継続上の弱点となります。
ノードごとのデータ書き込み量を均等にした場合の問題点
一部のノードに偏ってデータが書き込まれるのが問題なのであれば、CRUSHマップのウェイト値を変更して、各ノード単位で均等に書き込みが行われるようにするとどうなるでしょうか。
この場合は、大きなディスク容量が有効に使われないという問題が生じます。
基礎知識編で紹介したように、Cephにおけるデータの格納先はPGを単位として決定されますが、どのPGのデータがどのディスクに格納されるかは、CRUSHマップに定義されたディスク構成とPGの数によって一意に決定されます。
これは同時に、Cephのデータ書き込みがディスクの空き容量を全く考慮せずに行われることも意味します。特定のディスクに空き容量の余裕があるからといって、「だったら今回はこのディスクに集中して書き込みましょう」といった融通を臨機応変に利かせることはできないのです。
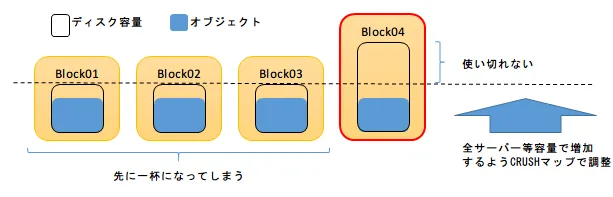
上図に示したように、空き容量が不均等な状態のまま減少していくと、最終的にはいずれかのディスクが一杯になった時点で、Cephクラスター全体がそれ以上の書き込みを受け付けなくなってしまいます。
以上を考慮した結果、増設するハードウェアは現行と同じスペックのものに決定しました。
なお、今回はスケールアウトを前提として増設ハードウェア構成の考え方を説明しましたが、スケールアップの場合もハードウェア構成のベストプラクティスの考え方は変わりません。クラスター全体にわたって、ノードあたりのディスク数と個々のディスクの容量を均等に保つことが基本となります。
ソフトウェア構成の決定
ここまでの検討によって、ハードウェアの構成は決まりました。次に、ソフトウェア側の設定などで増設内容に影響する部分がないか検討します。
検討のポイントとしては、Cephのデータ格納の枠組みに影響する設定(レプリケーション数、PG数)および各種ソフトウェアのバージョンといった、クラスターの運用中に変更機会が少ない箇所について、今回の増設を機に見直しが必要かを見ていきます。
レプリケーション数
今回使用するCephのレプリケーション数は2としていますが、Cephの公式ガイドラインにおいて、レプリケーション数は最低3とすることが推奨されています。
そこで、今回の増設を機にレプリケーション数を3に増やしてデータの冗長性を向上させることを考えましたが、そのためには物理ディスク容量を実効ディスク容量の3倍確保する必要があります。計算してみると、これを達成するためには、今回増設するものと同じスペックのサーバーをさらに2台追加する必要があることが判り、費用と設置スペースの両面から今回の変更は見送ることになりました。
PG数
Cephの公式ドキュメントにおいては、PGの数はOSDの台数に応じた適正な数を作成することが推奨されています。今回の増設によって、適正数に変化が生じるか確認を行います。
Cephの公式が提供するPGcalculator ⧉に、以下の変数を投入して計算を行います。
| 項目 | 意味 | 増設前 | 増設後 |
|---|---|---|---|
| Size | レプリケーション数 | 2 | 2 |
| OSD # | 全体のOSD数 | 18 | 24 |
| %Data | プール比率 | 1.0 | 1.0 |
| Target PGs per OSD | OSDあたりの目標PG数(上限値) | 100 | 100 |
上記パラメータにより計算した結果、算出された適正数は増設前後とも1024となりました。既にこの数のPGが作成済みであるため、今回はPG数の変更は不要であることが確認できました。
なお、プールとは、Cephストレージ内に用途別(例:ボリュームサービス、イメージサービス、バックアップ等)に作成される領域の区分を指します。今回の環境では、Cephストレージをボリュームサービスの用途のみに利用しているため、Cephストレージ全体が単一のプールである(プール比率1.0)と見なします。
また、Target PGs per OSDは、PGcalculator ⧉サイトの説明文に記載された指標値にしたがって入力します。
ソフトウェアバージョン
-
Ceph
既存のblockノードでは、CephのバージョンはJewelを使用しています。クラスター内のCephバージョン混在を避けるため、今回追加するノードのCephも同じJewelで構築を行います。
-
Cinder
CinderのバージョンはOpenStackのバージョンに紐付くため、既存のOpenStackと同じPikeに含まれる11.1を使用します。既存ノードのCinderとはビルドバージョンが異なりますが、ボリュームサービスの動作上、混在しても問題はないことを確認済みです。
-
OS
OSは、今後のOpenStack環境のアップグレードを考慮して、できるだけ最新のバージョンを使用します。本作業の準備に取り掛かった時点で検証ができた最新バージョンはCentOS7.5ですので、この上でJewelバージョンのCephが利用できること、およびこのノードが従来構成のノードと混在できることを検証したうえで採用することとしました。
以上の検討より、追加するノードの構成は以下の通り決定しました。
| 項目 | 構成内容 | 備考 |
|---|---|---|
| サーバーCPU | Xeon E3-1220 x1 | 既存ノードと同一 |
| サーバーメモリ | 8GB | 既存ノードと同一 |
| サーバーOS | CentOS 7.5 | |
| OSDディスク数 | 6台 | 既存ノードと同一 |
| OSDディスク容量 | 10.8TB | 既存ノードと同一 |
| OpenStackバージョン | Pike | 既存ノードと同一 |
| Cinderバージョン | 11.1.1-1 | |
| Cephバージョン | Jewel | 既存ノードと同一 |
次回予告
ここまでの検討により、増設するblockノードの構成が決定しました。
次回は、この構成で実際の新規ノードを構築し、既存クラスターに追加するに当たっての、それぞれの手順の意味合いや要注意ポイントなどについて、これまで説明した内容を踏まえる形で解説して行きます。
記事の執筆にあたっては情報の正確性に努めておりますが、掲載されている文章やソースコード、設定ファイル等の内容について、完全な正確性や安全性を保証するものではありません。活用される際は、必ず公式ドキュメント等をご自身で確認のうえご判断ください。
