

[!] この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
これまで、基礎知識編、増設計画編と、増設作業のための背景知識と準備内容を説明してきました。
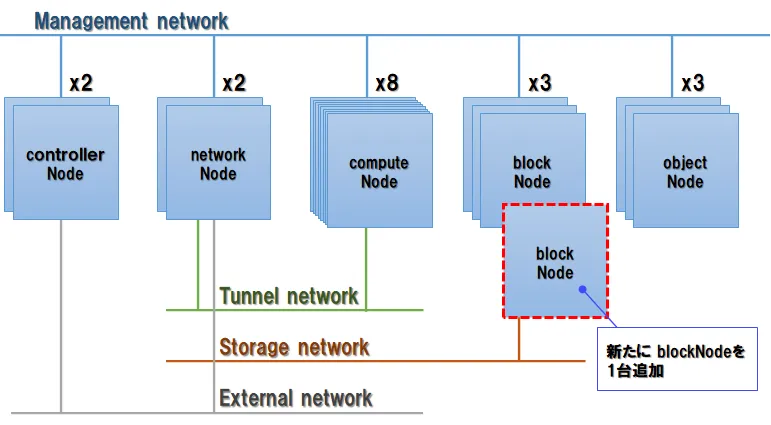
最終回の今回は、これまでの準備を元に、既存のOpenStack環境におけるBlockストレージにノードを追加する際の、実際の増設作業と動作確認の手順を紹介します。
作業前の注意点
増設作業では、多数のサーバーにログインして設定やファイルの変更を実施します。作業対象となるサーバーやファイルの取り違えには十分に注意してください。
また、増設計画編でも触れた通り、Cephクラスターの構成を変更した際に行われるデータの再配置処理は、長時間にわたってBlockストレージ全体の読み書き性能に影響を与える場合があるため、本作業はサービスを中断してのメンテナンス時間帯を設けて実施したほうが安全です。
サーバーの準備
まず、何もインストールされていない状態のサーバーを、新しいblockノードとして利用するためのOS環境の準備を行います。なお、この記事ではハードウェアの設置や、サーバーOSのインストール・設定に関する詳細な手順は取り扱いませんのでご了承ください。
OSのインストール
サーバーのシステム用ディスクにCentOS7.5を最小構成でインストールします。
OSの設定
ネットワーク
増設するblockノードのネットワーク関連の設定値を、以下のように投入します。OSインストール時に設定が可能であれば、その時点で行っても構いません。
| 項目 | 値 | 備考 |
|---|---|---|
| ホスト名 | block4 | block1~3は既存ホスト名 |
| IPアドレス(Managementネットワーク) | 192.168.1.63 | |
| IPアドレス(Storageネットワーク) | 192.168.20.63 |
上表の値は今回の環境における例として以降の本文中で使用する設定値です。
OpenStack環境各サーバーのホスト名とIPアドレスをblock4のhostsファイルに登録し、ホスト名からIPアドレスを解決できるようにすると共に、既存の各サーバーのhostsファイルにもblock4のホスト名とIPアドレスを登録します。
なお、この時点でcontrollerノードからblock4に一度SSHでログインし、known_hostsの登録を行っておくとよいでしょう。
ディスク
増設するノード上の各OSD用ディスクにパーティションを作成し、フォーマット後、指定のOSD用ディレクトリを作成してマウントします。今回の事例では、以下の構成でディスクを設定しました。
| ディスク名 | パーティション名 | ファイルシステム | マウント先ディレクトリ(※) |
|---|---|---|---|
| /dev/sda | /dev/sda1 | xfs | /ceph/19 |
| /dev/sdb | /dev/sdb1 | xfs | /ceph/20 |
| /dev/sdc | /dev/sdc1 | xfs | /ceph/21 |
| /dev/sdd | /dev/sdd1 | xfs | /ceph/22 |
| /dev/sde | /dev/sde1 | xfs | /ceph/23 |
| /dev/sdf | /dev/sdf1 | xfs | /ceph/24 |
(※)マウント先ディレクトリは任意に指定可能。上表の設定は、今回の環境における一例です
なお、今回は物理ディスク1台あたり1個のOSDとして構成し、1台のディスク上で割り当て可能な全領域を単一パーティションとして割り当てます。
ソフトウェアのインストールと設定
ここまでの手順で、OpenStackノードを構成する各種ソフトウェアをインストールする準備が整いました。
以下、各種ソフトウェアをインストールし、サービスを構成していきます。
OpenStackのインストールと設定
パッケージのインストール
まず、OpenStackノードとしての基本的な機能のパッケージをインストールします。
- centos-release-openstack-pike
- OpenStackclient
これらは、block4ノード上でyumコマンドを利用してインストールします。
Cephのインストールと設定
続いて、controllerノード上でceph-deployコマンドを使用して、新規ノードにCephをインストールします。
なお、ceph-deployはBlockストレージを新規構築する際にも使用され、増設を実施する時点ではcontrollerノードにインストール済みの前提であるため、この記事ではceph-deploy自体のインストール手順は取り扱いません。
インストール作業用OSユーザー作成
ceph-deployコマンドは、controllerノードから作業対象ノードにSSHでログインしてインストール処理を実施します。このログイン時に使用するblock4のユーザーを、block4ノード上でroot権限から以下のコマンドによって作成・設定します。
# cephadminユーザを作成[root@block4 ~]# useradd cephadmin[root@block4 ~]# passwd [任意に設定]
# cephadminユーザがパスワードなしでblock4にログインするための設定[root@block4 ~]# echo 'cephadmin ALL = (root) NOPASSWD:ALL' | sudo tee /etc/sudoers.d/cephadmin
# block4ノードからパッケージダウンロードのためインターネットに接続する際に使用するプロキシがあれば設定[root@block4 ~]# echo 'Defaults env_keep+="http_proxy"' | sudo tee -a /etc/sudoers.d/cephadmin[root@block4 ~]# echo 'Defaults env_keep+="https_proxy"' | sudo tee -a /etc/sudoers.d/cephadmin
# sudoersファイルのパーミッション設定[root@block4 ~]# chmod 0440 /etc/sudoers.d/cephadmin
# SSH経由でsudoが使えるようにする設定[root@block4 ~]# sed -i 's/Defaults.*requiretty/Defaults !requiretty/g' /etc/sudoers-
注意点
この設定は、サーバーのセキュリティー上の弱点となる場合があります。
増設計画編で示したように、blockノードは OpenStack外部のネットワークと直接接続しない設計であるために上記の設定を許容しています が、外部のネットワークからSSHトンネルなどを介さず直接接続できるサーバーでは、パスワード無しログインやSSH経由でのsudoを許容する設定を行わないよう注意してください。
ceph-deployの設定確認
controllerノードにてceph-deployの各種設定は以下の通り行われている前提とします。
| 項目 | 値 |
|---|---|
| controllerノードのホスト名 | controller1 |
| ceph-deploy利用ユーザー | cephadmin |
| ceph-deployホームディレクトリ | /home/cephadmin/my-cluster |
| Cephのconfigファイル名 | ceph.conf |
Ceph設定ファイルの更新
ここからCephのインストールが完了するまでの作業は、特に断りがない限りcontrollerノード上でコマンド実行します。
ceph-deployホームディレクトリ配下のceph.confを編集して、新規追加するノードの情報を記載します。
このファイルは、次にceph-deployコマンドによって各ノードに設定情報を配布するためのマスターとなります。
-
globalセクション
このセクションの
mon_host項目には、MONクラスターのメンバーがカンマ区切り一覧形式で列挙されています。ここに、今回追加するblock4の管理NWのIPアドレス(192.168.1.63)を追記します。
-
mon.dセクション
MONデーモンの設定項目は、デーモンごとに個別のセクションに分かれています。既存のMONデーモンに対応するmon.a~mon.cの各セクションの後ろに、今回追加するmon.dセクションを新設します。
[mon.d]host = block4mon addr = 192.168.1.63:6789なお、MONデーモンが通信に使用するポートは
6789固定です。 -
osd.18~osd.23セクション
OSDクラスター内の各OSDには0から始まる通し番号のIDが割り当てられます。既存OSDは18台あるため、今回追加する6台のIDはosd.18からosd.23となります。
それぞれのOSDについて個別にセクションを設け、通信に使用するIPアドレスを記載します。
今回のケースでは、同一ノード内のOSDは全て共通のIPアドレスとなります。
[osd.XX]public addr = 192.168.1.63cluster addr = 192.168.20.63 -
mds.dセクション
今回の環境ではOSDのファイルシステムとしてXFSを利用しています。このため、CephFS利用時のみ有効となるMDSは使っておらず、この項目は機能していませんが、設定ファイルにプレースホルダとしてのみ記載しています。
今回追加するblock4についても、以下の通りセクションを新設して記載を追加します。
[mds.d]host = block4
既存ノードへ設定ファイル配布
以下のceph-deployコマンドを実行し、編集済みのceph.confを既存の各ノードに配布します。
[cephadmin@controller1 my-cluster]$ ceph-deploy --overwrite-conf config push controller1,block1,block2,block3Cephパッケージのインストール
以下のceph-deployコマンドを実行し、block4ノードにCephのパッケージをインストールします。
[cephadmin@controller1 my-cluster]$ ceph-deploy install block4このコマンドを実行するとcephadminユーザでblock4にログインし、リモートSSH上でyumコマンドを実行して必要なパッケージのインストールまでを一括で行います。
MONクラスターへのメンバー追加
以下のceph-deployコマンドを実行し、MONクラスターのメンバーとしてblock4を追加します。
[cephadmin@controller1 my-cluster]$ ceph-deploy mon add block4データディスクの作成
以下のceph-deployコマンドを実行し、block4の上にデータディスクを作成します。
[cephadmin@controller1 my-cluster]$ ceph-deploy osd prepare block4:/ceph/19 block4:/ceph/20 block4:/ceph/21 block4:/ceph/22 block4:/ceph/23 block4:/ceph/24このコマンドは、block4のCeph用データディスク上(/ceph/XX/)にOSDのシステムファイルを作成します。また、OSDクラスタにblock4の新規OSDの情報を通知し、CRUSHマップを更新します。
データディスクの起動
以下のceph-deployコマンドを実行し、block4上で各OSDのデーモンを作成・起動します。
[cephadmin@controller1 my-cluster]$ ceph-deploy osd activate block4:/ceph/19 block4:/ceph/20 block4:/ceph/21 block4:/ceph/22 block4:/ceph/23 block4:/ceph/24これにより、各OSDが正式に運用開始となります。先の手順で更新されたCRUSHマップに基くデータの再配置は、この時点から開始されます。
設定ファイル・認証鍵の投入
以下のceph-deployコマンドを実行し、configファイルと認証キーをblock4に配布します。
[cephadmin@controller1 my-cluster]$ ceph-deploy admin block4この認証キーは、クライアント(ボリュームサービス)からblock4へのデータ読み書きを行う際に使用されます。
ここで、一旦block4にrootユーザでログインし、認証キーファイルに読み取り権限を付与します。
[root@block4 ~]# chmod +r /etc/ceph/ceph.client.admin.keyring以上の手順によって、block4ノードがCephクラスターの一員として追加されました。
Cephクラスタの状態確認
controllerノードに戻り、以下のコマンドでCephクラスターのステータスを確認します。
[cephadmin@controller1 my-cluster]$ ceph -sここまでの構築が終わったばかりの時点では、まだデータの再配置が行われている途中ですので、Cephのステータスは以下のようにWARNで表示されます。
cluster xxxxhealth HEALTH_WARN 513 pgs backfill_wait 3 pgs backfilling 72 pgs stuck unclean recovery 1049279/2253484 objects misplaced (46.563%)monmap e2: 4 mons at {block1=192.168.x.x:6789/0,block2=192.168.x.x:6789/0,block3=192.168.x.x:6789/0,block4=192.168.1.63:6789/0} election epoch 42, quorum 0,1,2,3 block1,block2,block3,block4osdmap e1411: 24 osds: 24 up, 24 in; 515 remapped pgs flags sortbitwise,require_jewel_osds pgmap v64338415: 1088 pgs, 2 pools, 3331 GB data, 843 kobjects 6694 GB used, 33527 GB / 40221 GB avail 1049279/2253484 objects misplaced (46.563%) 574 active+clean 512 active+remapped+wait_backfill 3 active+remapped+backfillingclient io 36388 B/s rd, 506 kB/s wr, 46 op/s rd, 80 op/s wrここでは、表示されたCephクラスターのステータスについて以下の項目を確認します。
- monmapの項目にblock4の情報が追加されていること
- osdmapの項目に表示されるOSD数が、今回追加したノードの分増えていること
- healthおよびpgmapの項目に、リバランス処理が行われている状態(objectのリカバリー進捗率、backfill/backfill_wait状態のPG数など)が出力されること
ディスク状態の確認
続いて、以下のコマンドを実行して、追加したOSDにデータが流入していることを確認します。
[cephadmin@controller1 my-cluster]$ ceph osd dfこのコマンドは、OSDごとのデータ格納状況を以下のように一覧で出力します。
ID WEIGHT REWEIGHT SIZE USE AVAIL %USE VAR PGS : 18 1.63660 1.00000 1675G 6725M 1669G 0.39 0.02 92 19 1.63660 1.00000 1675G 5148M 1670G 0.30 0.02 91 20 1.63660 1.00000 1675G 1101M 1674G 0.06 0.00 95 21 1.63660 1.00000 1675G 1096M 1674G 0.06 0.00 80 22 1.63660 1.00000 1675G 1092M 1674G 0.06 0.00 80 23 1.63660 1.00000 1675G 1097M 1674G 0.06 0.00 114少し時間をおいてコマンドを何度か実行し、出力された項目のうち、「USE」および「%USE」の項目が継続して増加していれば、追加したOSDに正常にデータが格納されていると判断できます。
Cinderのインストールと設定
ここまでの手順によって、ノード追加によるCephの拡張が正常に完了しました。次に、追加したノードをOpenStackから利用できるように、Cinderの設定を行います。
パッケージのインストール
block4ノードにrootユーザでログインして以下のyumコマンドを実行し、Cinder本体をインストールします。
[root@block4 ~]# yum install openstack-cinderさらに、下記のパッケージもインストールします。
[root@block4 ~]# yum install targetcli python-keystone libvirtサービスの設定
block4ノード上でCinderサービスのconfigファイル(/etc/cinder/cinder.conf)を編集し、Cephと連携できるように設定を行います。
なお、これ以外にCinder自身の動作のために必要な設定項目(OpenStackの接続・認証設定など)が存在しますが、この記事では割愛します。Cinderが動作しているOpenStack環境の構成に合わせて適宜設定を行ってください。
-
DEFAULTセクション
以下の通り、CinderボリュームサービスのバックエンドとしてCephを指定します。
[DEFAULT]:enabled_backends = ceph: -
cephセクション
このセクションは新規追加となります。Cephとの連携に必要な各種設定を以下の通り追記します。
[ceph]volume_driver = cinder.volume.drivers.rbd.RBDDrivervolume_backend_name = cephrbd_pool = [Cephのボリュームサービス用プール名]rbd_ceph_conf = /etc/ceph/ceph.confrbd_flatten_volume_from_snapshot = falserbd_max_clone_depth = 5rbd_store_chunk_size = 4rados_connect_timeout = -1rbd_user = cinderrbd_secret_uuid = [ボリュームサービス用シークレットUUID]restore_discard_excess_bytes = trueなお、
rbd_poolとrbd_secret_uuidの値は、Cinderサービスを提供する全ノードで共通の値が設定されます。既存のblockノードにログインしてcinder.confファイルを参照し、同じ値を記載してください。
Ceph-Cinderの連携設定
Ceph側の設定ファイルにCinderと連携するための設定を記載します。記載対象は、全てのblockノードとcomputeノードに配布済みの/etc/ceph/ceph.confです(※)。controllerノードに配布した設定ファイルや、ceph-deployホームディレクトリ配下のマスターファイルには、本手順の修正は必要ありません。
(※)Cinderとの連携設定は、ceph.confのマスターを修正して各ノードに配布する際に上書き消去されます。 このため、ceph.confを更新する都度追記が必要となります。各blockノードに配布済みの/etc/ceph/ceph.confに以下を追記します。
[client] rbd cache = true rbd cache write through until flush = true admin socket = /var/run/ceph/guests/$cluster-$type.$id.$pid.$cctid.asok log file = [computeノード上におけるハイパーバイザ(QEMU等)のインスタンスログ出力先を記載] rbd concurrent management ops = 20
[client.cinder] keyring=/etc/ceph/ceph.client.cinder.keyringlog fileの項目は、computeノードに置かれている既存のceph.confを参考に記載してください。
各blockノードの設定ファイルに上記の設定を行ったら、このceph.confファイルをscpコマンドにより各computeノードにも配布し、/etc/ceph/配下に格納します。
Cinderの認証設定
controllerノード上で以下のコマンドを実行し、CinderボリュームサービスがCephとの連携に使用する認証鍵をblock4ノードに配布します。
[cephadmin@controller1 ~]$ ceph auth get-or-create client.cinder | ssh root@block4 tee /etc/ceph/ceph.client.cinder.keyring次に、block4にログインして、上記で配布した鍵ファイルの所有権を変更します。
[root@block4 ~]# chown cinder:cinder /etc/ceph/ceph.client.cinder.keyringサービス有効化と動作確認
サービス再起動
ここまで変更してきた既存ノード上の設定を有効化するために、各ノード上で動作している以下のサービスを再起動します。
| ノード | サービス | コマンド |
|---|---|---|
| block1~4 | Cinder | systemctl restart openstack-cinder-volume target |
| compute1~8 | Nova | systemctl restart openstack-nova-compute |
再起動が完了したら、controllerノード上で下記コマンドを実行した際に表示されるCinderサービスのメンバー一覧に、今回増設したblock4が追加されていることを確認します。
[root@controller1 ~]$ cinder service-list表示されたサービス一覧の中に、下記のようにHostの項目が「block4@ceph」である行が出力されていれば、新ノードのサービスへの追加は成功です。
[cephadmin@controller1]$ cinder service-list+------------------+-------------+------+---------+-------+----------------------------+-----------------+| Binary | Host | Zone | Status | State | Updated_at | Disabled Reason |+------------------+-------------+------+---------+-------+----------------------------+-----------------+:| cinder-volume | block4@ceph | nova | enabled | up | YYYY-MM-DDThh:mm:ss.000000 | - |動作確認
以上の手順を以って、一連の増設作業は完了となります。
最後に、増設したblockストレージが正常に機能していることを、OpenStackのダッシュボード上から以下の操作と観点により確認します。
| 項目 | 実施内容・観点 |
|---|---|
| ボリューム作成 | Cinderボリュームを作成できること |
| ボリューム接続 | 作成したボリュームをOpenStackインスタンスに接続できること |
| ボリュームアクセス | インスタンスにログインし、上記で接続したボリュームにファイルの読み書きができること |
| ボリューム切断 | インスタンスからボリュームを切り離せること |
| ボリュームスナップショット | ボリュームのスナップショットを作成できること |
| スナップショット削除 | ボリュームのスナップショットを削除できること |
| ボリューム削除 | ボリュームを削除できること |
上表の各操作が一通り問題なく完了すれば、blockストレージは正常に機能しています。
まとめ
以上、3回に渡って、blockノードを1台増設するという最も単純なスケールアウトの場合について解説しました。
解説に使用したCephのバージョンはjewelですが、2020年9月現在最新バージョンのoctopusでもソフトウェアの基本的な構成は変わらないため、今回紹介した計画の立て方や作業手順を参考に増設が可能と考えられます。
プライベートクラウドを運用する場合、ストレージの拡張は当然避けて通れない問題ですが、AWSなどのパブリッククラウドを利用する場合であっても、分散型ストレージの仕組みに関する知識は環境設計やトラブルシュートなどの場面で有用なものとなります。
この記事が、そのための知識の入口となってくれれば幸いです。
