

[!] この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
Mattermost ⧉の投稿を、Redash ⧉上のPythonで抽出する方法をまとめました。
はじめに
当社はコミュニケーションツールにMattermost ⧉を採用しています。チャット機能は十分なのですが、投稿の検索や抽出に使いづらい点もあります。
- 投稿文をキーワードでOR検索できない。(ただしハッシュタグは可能)
- 複数の投稿文をまとめてコピペすると、余分な改行が入ったり、リンク先の情報が消えたりする。
そこで、BIツールのRedashと連携させて、Mattermost API ⧉を利用して投稿を抽出する方法をまとめました。この記事では、Mattermost APIの呼び出しやデータの抽出処理に、Redash上のPythonを使用します。
前準備
Mattermost APIの利用や、Redash上でPythonを実行するには、前準備が必要です。
Mattermostパーソナル・アクセス・トークンの発行
Mattermost APIを利用するには、「パーソナル・アクセス・トークン」が必要です。Mattermost管理者権限で発行できます。詳しくは、Personal Access Tokens ⧉を参照してください。
RedashでPythonを実行可能にする
RedashでPythonを実行するには、サーバーの環境変数REDASH_ADDITIONAL_QUERY_RUNNERSに、.(ドット)を挟んでpythonを追加します。
REDASH_ADDITIONAL_QUERY_RUNNERS=redash.query_runner.pythonRedashがKubernetes上で稼動している場合は、DeploymentのYAMLへ同様に追加します。serverコンテナとworkerコンテナの両方に追加する必要があります。
- name: REDASH_ADDITIONAL_QUERY_RUNNERS value: redash.query_runner.pythonPythonデータソースの作成
Pythonの実行結果を源とする、Pythonデータソースを作成します。
Redashにログイン後、画面右上の「自身のユーザー名 > Data Sources」を選択し、画面左側の「+New Data Sources」ボタンをクリックします。セレクトボックスにある「Python」をクリックすると、以下の画面が表示されます。
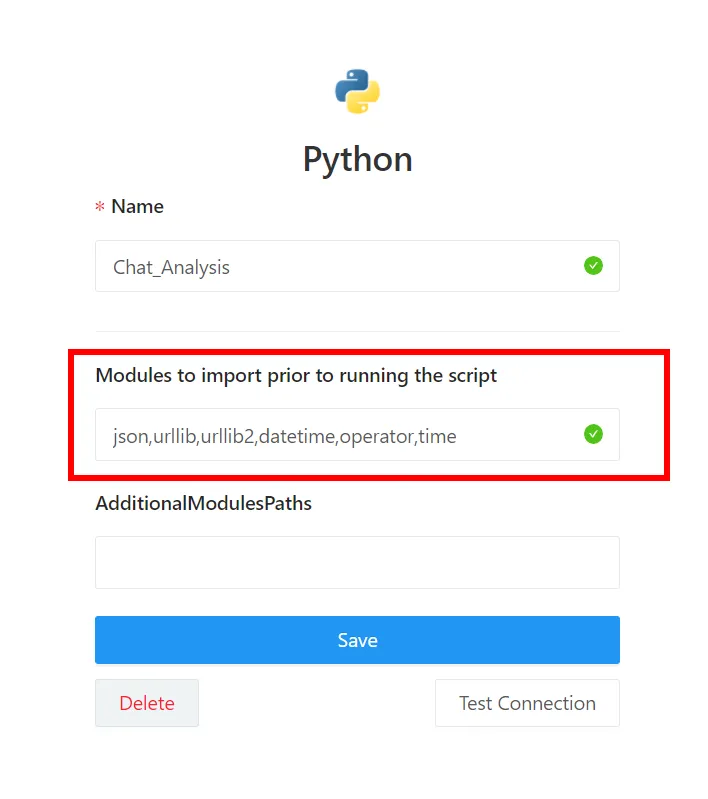
- 「Name」には任意の名前を入力します。
- 「Modules to import prior to running the script」には、使用するPythonのモジュール名をカンマ区切りで設定します。ここで設定していないと、Pythonのソースコード内でimportしても使用できません。今回は、この記事のサンプルコードに必要な「json,urllib,urllib2,datetime,operator,time」を指定します。
- 「AdditionalModulesPaths」は、Pythonの標準以外のモジュールを使用する場合、モジュールのサーバー上のパスをカンマ区切りで指定します。この記事で作成するソースコードは必要ないため、指定しません。
「Save」ボタンをクリックすると、Pythonデータソースが作成されます。
投稿の抽出
Pythonデータソースを作成したら、投稿を抽出するコードを作成できます。画面左上の「Create > Query」を選択します。データソースにPythonデータソースを選択すると、テキストエリアでPythonコードを記述できます。
仕様と方針
- 指定したチャネルの投稿を以下の条件で表示。
- プログラム実行日時から、指定された日数の間にある投稿。
- 指定したキーワード(複数可、OR検索)が含まれる投稿。
- 表示内容は、「投稿日時」「ユーザー名」「投稿内容」
- Pythonのバージョンは、2.7.18を使用。
- Redashの最新安定板は、既にサポート終了のバージョン2系 ⧉を使用しているため、合わせる必要があります。
サンプルコード
抽出条件のパラメーター指定は、今回は全てソースコード内に直接記述しています。
import jsonfrom datetime import datetime, timedeltaimport urllibimport urllib2import operatorimport time
## アクセストークンaccess_token = 'XXXXXXXXXXXXXXXX'
####### 対象チャネルの投稿を取得 ####### 対象チャネルのIDchannel_id = 'XXXXXXXXXXXXXXXX'## 対象チャネルの投稿を取得するAPIchannel_url = 'https://chat.example.com/api/v4/channels/' + channel_id + '/posts'## リクエストヘッダにアクセストークンを含めるchannel_post_get_request_header = { 'Authorization': 'Bearer ' + access_token,}## リクエストパラメータで、チャットの取得範囲を指定since_time = datetime.now() - timedelta(days=1825)since_time_unixtime = time.mktime(datetime.timetuple(since_time))since_time_unixtime_milli = int(since_time_unixtime * 1000)req_param = urllib.urlencode( { 'since': since_time_unixtime_milli })
## 対象チャネルの投稿を取得するAPIにリクエストパラメータを付与channel_url = channel_url + "?{0}".format(req_param) # "+=演算子はRedashでは利用不可"req = urllib2.Request(channel_url,headers=channel_post_get_request_header)
res = urllib2.urlopen(req)post_data = res.read()res.close()
## 対象チャネルの投稿データJSONpost_data_JSON = json.loads(post_data)
####### ユーザーIDとユーザー名の対応 #####post_user_id_set = set() # 重複排除にsetを利用for prop in post_data_JSON['posts']: post_user_id_set.add(post_data_JSON['posts'][prop]['user_id'])post_user_id_list = list(post_user_id_set) # ただしlistにしないと後でjsonに渡せないため変換
####### ユーザーIDと表示名のディクショナリを作成 ####### ユーザーIDを渡すと、そのユーザー情報を返すAPIuser_list_url = 'https://chat.example.com/api/v4/users/ids'
## リクエストヘッダにアクセストークンとContent-Typeを含めるuser_list_get_request_header = { 'Authorization': 'Bearer ' + access_token, 'Content-Type': 'application/json'}## 投稿者のユーザーIDセットを渡し、各ユーザーの情報を取得req = urllib2.Request( user_list_url, headers=user_list_get_request_header, data=json.dumps(post_user_id_list).encode())res = urllib2.urlopen(req)user_data = res.read()res.close()user_data_JSON = json.loads(user_data)
###### 「ユーザーID:表示名」のディクショナリを作成 #####post_user_dict = {}## 取得した投稿の投稿者(user_id)のリストを1件ずつ見て、ユーザー名(username)の対応付けfor pu_id in post_user_id_list: for uid in user_data_JSON: # uidは、user_data_JSONの各要素 if uid["id"] == pu_id: post_user_dict.update({pu_id:uid["username"]}) break else: # ユーザー名が引けなかった場合、ユーザーIDを表示。 post_user_dict.update({pu_id:pu_id})
###### ソート ####### APIから取得したままだと、post_idでソートされている。## post_idはランダム文字列のため、投稿日時でソートする。post_data_list = []for prop in post_data_JSON['posts']: # 'create_at'はUNIX時間のミリ秒 dt = datetime.fromtimestamp(post_data_JSON['posts'][prop]['create_at'] / 1000) + timedelta(hours=+9) post_data_list.append( { 'create_at':dt.strftime('%Y-%m-%d %H:%M.%S'), # 「ユーザーID:表示名」ディクショナリから、ユーザーIDから表示名を取得 'username':post_user_dict[ post_data_JSON['posts'][prop]['user_id'] ], 'message':post_data_JSON['posts'][prop]['message'] } )sorted_post_data_list = sorted(post_data_list,key=operator.itemgetter('create_at'))
###### 表示する投稿の絞り込み #####narrow_words_set = {'リモートワーク','Teleworker','機能'}narrow_words_decoded_set = [nwd.decode('utf-8') for nwd in narrow_words_set]
## ソートされた投稿を1件ずつ、キーワードが部分一致するか確認する。narrow_post_data_list = []for spost in sorted_post_data_list: for nword in narrow_words_decoded_set: # 部分一致したら、リストに入れる。部分一致が0件ならリストは空のまま。 if nword in spost['message']: narrow_post_data_list.append(spost) break
###### 画面表示 #####result = {}for disp_post in narrow_post_data_list: add_result_row(result,{ 'create_at':disp_post['create_at'], 'username':disp_post['username'], 'message':disp_post['message'] })
add_result_column(result,'create_at','','string')add_result_column(result,'username','','string')add_result_column(result,'message','','string')ポイントは以下の通りです。見出しはサンプルコード内のコメントと対応しています。
ユーザーIDとユーザー名の対応
対象チャネルの投稿を取得するAPI ⧉の仕様で、投稿者はユーザーIDで出力されます。このユーザーIDはユーザー名ではなくランダムな文字列のため、投稿者がわかりません。
そこで、ユーザーIDを渡すとそのユーザー情報を返すAPI ⧉を使用して、今回表示する投稿の投稿者ユーザーIDに対応するユーザー名を取得し、辞書型で保持しておきます。これにより、この後の処理でユーザーIDからユーザー名を導出できます。
ソート
対象チャネルの投稿を取得するAPI ⧉から取得してきた投稿は、「post_id」の昇順でソートされています。このIDはランダムな文字列のため、投稿日の昇順でソートしなおします。
表示する投稿の絞り込み
Mattermost APIだけでは投稿をキーワードで絞り込んで取得することはできないため、Python側で絞り込みます。
for文がネストし、さらにその奥にif文があります。本来なら、以下のようにシンプルに書けるはずのですが、Redashではany関数の中にある変数を読み取れないエラーになるようです。
narrow_post_data_list = [nl for nl in sorted_post_data_list if any(map(lambda x : x in nl['message'], narrow_words_set))]## もしくはnarrow_post_data_list = [nl for nl in sorted_post_data_list if any(x in nl['message'] for x in narrow_wo画面表示
Redashの公式ドキュメントには記載されていないのですが、add_result_row add_result_columnという2つの関数を使用すると、簡単に画面に表示できます。ソースコード ⧉を見た限り、以下の仕様のようです。
add_result_row関数
第2引数に行の各値を辞書型で代入すると、第1引数の辞書型変数に次々と格納します。この第1引数の辞書型変数には、「表示する全ての行」が格納されます。
add_result_column関数
- 第1引数に、先の
add_result_row関数で準備した「表示する全ての行」を格納した辞書型変数を指定します。 - 第2引数には、先の
add_result_row関数の第2引数に代入した辞書型変数のkeyを指定します。 - 表の列の並びは、
add_result_column関数を実行した順です。 - 第4引数には、データ型を指定します。指定できるデータ型については、ソースコード ⧉の変数
SUPPORTED_COLUMN_TYPESを確認してください。 - 第3引数には、列の表示名を入れられるようですが、現時点では表示されなかったため、空文字としています。空文字にすると、第2引数に指定した文字列が列名に使用されます。
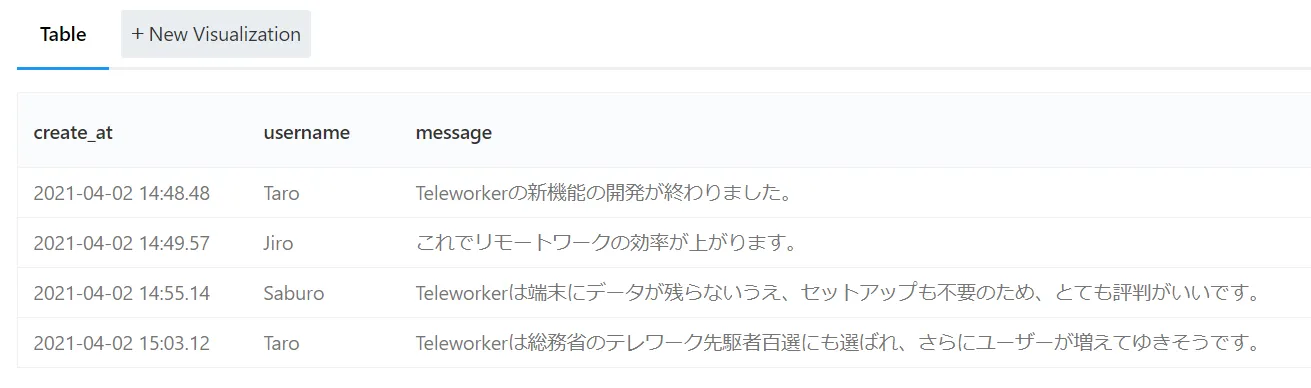
サンプルソースの実行結果
実行すると、以下のような表が表示されます。
検索キーワードは、サンプルソース内のnarrow_words_set変数に設定している通り、「リモートワーク」「Teleworker」「機能」です。いずれかのキーワードを含む投稿を表示します。
おわりに
Mattermost APIを使用して、投稿をRedashに表示してみました。今回は単純な処理しかしていませんが、集計や分析の土台にも使えるかもしれません。さらには、Pythonが持つ豊富なライブラリを活用することで、チャットの投稿から投稿者の感情を分析することなどもできそうです。
記事の執筆にあたっては情報の正確性に努めておりますが、掲載されている文章やソースコード、設定ファイル等の内容について、完全な正確性や安全性を保証するものではありません。活用される際は、必ず公式ドキュメント等をご自身で確認のうえご判断ください。
