

[!] この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
みなさんはリアクティブプログラミングという言葉を聞いたことがあるでしょうか?
リアクティブプログラミングは、リアルタイムに発生するストリームデータを非同期に処理するプログラミングパラダイムです。リアクティブプログラミングでアプリケーションを開発できるライブラリにはAkka ⧉やSpring WebFlux ⧉、ReactiveX ⧉などがあります。
この記事では、その中のSpring WebFluxについて説明し、実際にアプリケーションを開発して学んだことを紹介します。なお、Spring Frameworkの仕組みに関する詳細な説明は行いませんのでご了承ください。
Spring WebFluxの紹介
Spring WebFluxは、リアクティブプログラミングによってノンブロッキングで非同期なアプリケーションを開発できるSpring Frameworkです。Spring WebFluxには2つのプログラミングモデルがあります。1つはSpring MVCで開発したことがある方にはお馴染みのアノテーションコントローラ ⧉を使用するモデルです。Spring MVCとの相違点として、Spring WebFluxのコントローラメソッドは基本的にPublisher型(Mono ⧉型またはFlux ⧉型)を返します。
@RestControllerpublic class HelloController {
@GetMapping("/hello") public Mono<String> hello() { return Mono.just("Hello"); }}もう1つはFunctional Endpoints ⧉というモデルで、関数を使用してリクエストをルーティングするモデルです。このモデルではRouterFunctionsクラスの関数によってHTTPメソッドとパス、リクエストを受信した際に実行する処理を設定します。その設定をBean定義するとリクエストをルーティングできます。
@Componentpublic class HelloHandler {
public Mono<ServerResponse> hello(ServerRequest req) { return ServerResponse.ok().body(Mono.just("Hello"), String.class); }}@Configurationpublic class RouterConfiguration {
@Bean public RouterFunction<ServerResponse> router(HelloHandler helloHandler) { return RouterFunctions .route(RequestPredicates.GET("/hello"), helloHandler::hello); }}Spring WebFluxとSpring MVCの主な相違点は、ロジックの記載方法とリクエストの処理に使用するスレッドプールの仕組みです。
まず、ロジックの記載方法について説明します。Spring WebFluxはReactor ⧉というReactive Streams ⧉の仕様に基づいたリアクティブライブラリを使用します。Reactorは関数型プログラミングによってストリームデータの処理を行います。Spring WebFluxの開発ではセッション情報の処理やHTTPレスポンスの処理、コントローラの戻り値など、ビジネスロジックのほとんどの部分にReactorを使用します。
次に、リクエストの処理に使用するスレッドプールの仕組みについて説明します。Spring MVCでは、1つのリクエストに対して1つのスレッドが割り当てられます。Spring WebFluxでは、リクエストやレスポンスを処理するために少数のスレッドが用意されており、それらのスレッドは1つで複数のリクエストを処理します。何故、そのようなことができるかというと、Spring WebFluxは非同期処理なのでHTTP通信などの待機時間のある処理時にスレッドを解放して、別の処理に使用することができるからです。
例えば、Spring MVCから別のサービスへHTTPリクエストを送信した場合、相手からレスポンスが返ってくるまでHTTPリクエストの送信に使用したスレッドを占有します。この時にSpring MVCが新たなリクエストを受け取ると、HTTPリクエストの送信に使用したスレッドとは別のスレッドを使用して処理を行います。
Spring WebFluxから別のサービスへHTTPリクエストを送信した場合、HTTPリクエストの送信後に使用したスレッドを解放します。その後、相手からレスポンスが返ってくると空いているスレッドを使用して処理を行います。そして、スレッドを解放しているときにSpring WebFluxが新たなリクエストを受け取ると、その解放されたスレッドで別のリクエストを処理するため、1つのスレッドで複数のリクエストを処理することができます。
以下にSpring MVCとSpring WebFluxのスレッドの動きのイメージを提示します。
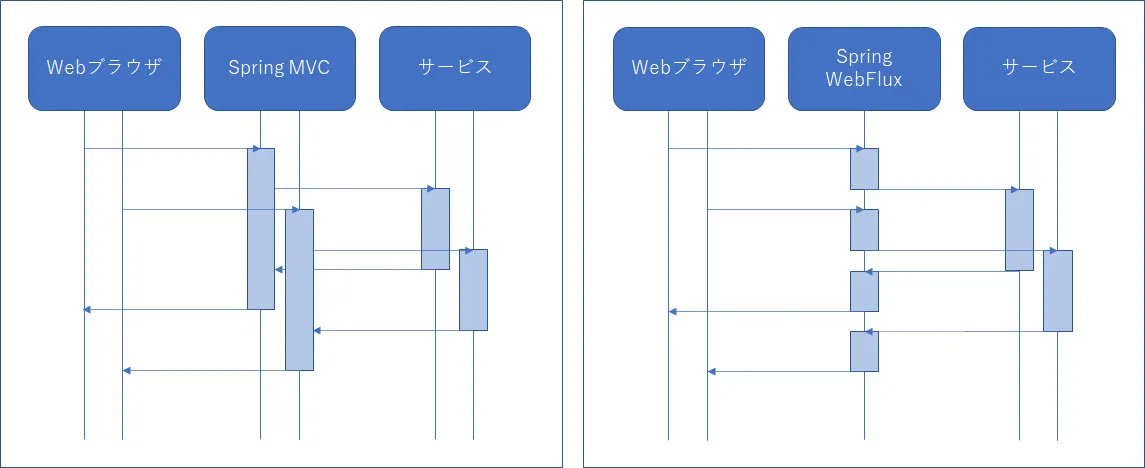
Spring MVCからSpring WebFluxに変更する
上記でSpring WebFluxの説明とSpring MVCとの主な相違点について紹介しました。ここからは、既存のアプリケーションのライブラリをSpring MVCからSpring WebFluxに変更したことについて紹介します。
アプリケーションの概要
まず、改修したアプリケーションの処理の一部を説明します。アプリケーションはリクエストを受け取ると他のサービスへAPIリクエストを送信します。そして、そのAPIのレスポンスを受信すると、受け取った情報を使用して再度同じサービスに別のAPIリクエストを送信します。その後、2回目のAPIのレスポンスで取得した情報を使用し、ディレクトリサービスにアクセスして情報を問い合わせます。APIとディレクトリサービスから取得した情報を組み合わせてDBに保存し、レスポンスを返します。
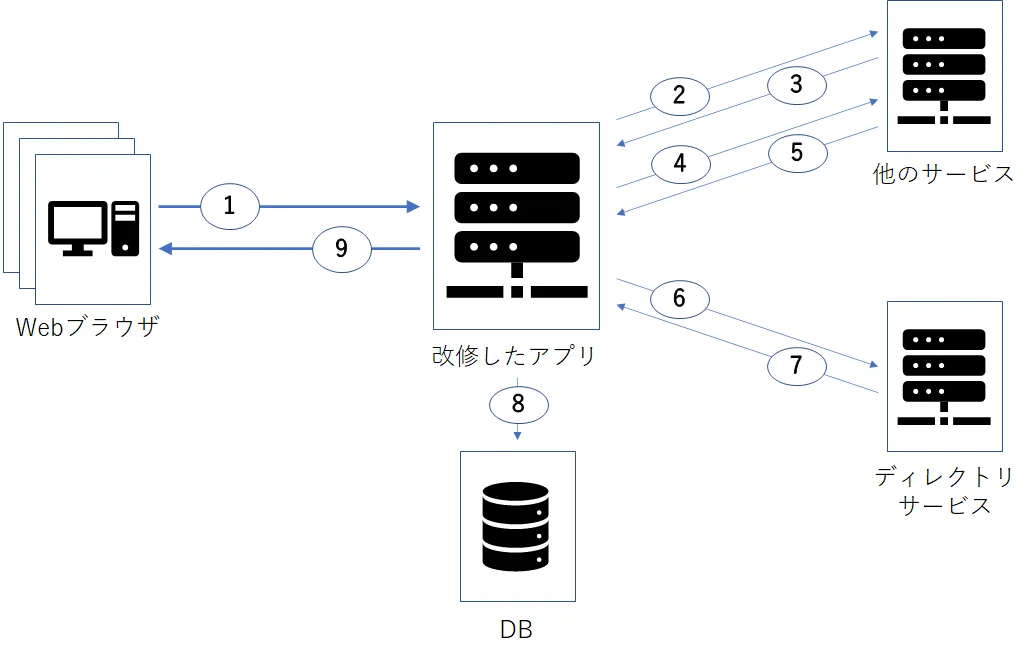
サンプルソース
上記で説明した処理の流れをSpring MVCで開発したサンプルソースが以下になります。
@RestControllerpublic class MvcSampleController {
@Autowired private SampleRepository sampleRepository;
@Autowired private DirectoryService directoryService;
private final RestTemplate restTempalte;
public MvcSampleController() { this.restTemplate = new RestTemplate(); }
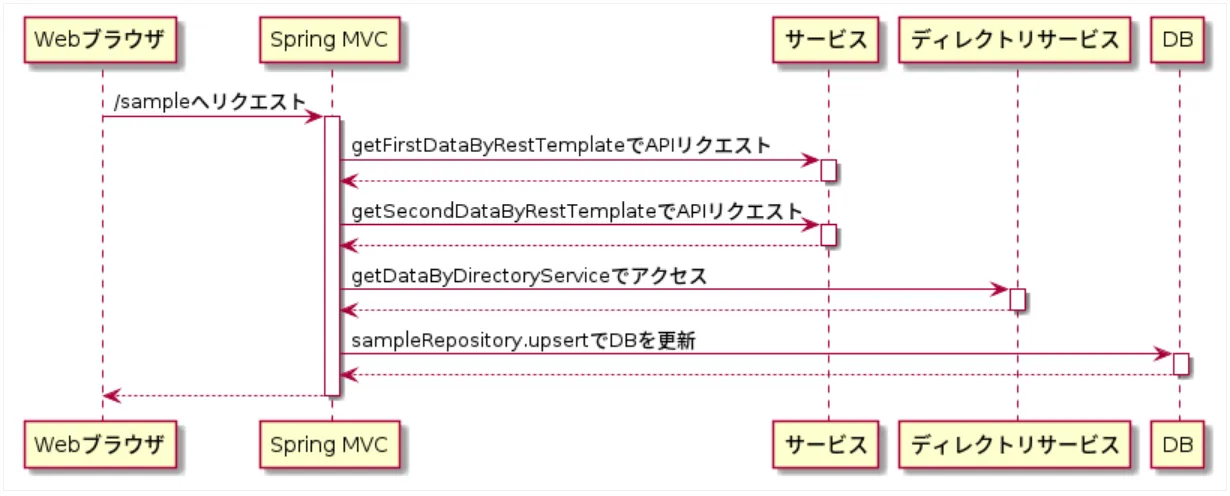
@GetMapping("/sample") // 1 public ResponseData sample() { FirstData firstData = this.getFirstDataByRestTemplate(); // 2, 3 SecondData secondData = this.getSecondDataByRestTemplate(firstData); // 4, 5 DirectoryData directoryData = this.getDataByDirectoryService(secondData); // 6, 7 ResponseData responseData = new ResponseData(firstData, secondData, directoryData); this.sampleRepository.upsert(responseData); // 8 return responseData; // 9 }
private FirstData getFirstDataByRestTemplate() { return this.restTemplate .getForObject("http://localhost:8081/api/v1/first", FirstData.class); }
private SecondData getSecondDataByRestTemplate(FirstData firstData) { return this.restTemplate .postForObject("http://localhost:8081/api/v1/second", firstData, SecondData.class); }
private DirectoryData getDataByDirectoryService(SecondData secondData) { return this.directoryService.search(secondData); }}このサンプルソースのシーケンスを図で表すと以下のようになります。
そして、Spring MVCで開発したサンプルソースをSpring WebFluxに改修したサンプルソースが以下になります。
@RestControllerpublic class WebFluxSampleController {
@Autowired private SampleRepository sampleRepository;
@Autowired private DirectoryService directoryService;
private final WebClient webClient;
public WebFluxSampleController(WebClient.Builder webClientBuilder) { this.webClient = webClientBuilder.baseUrl("http://localhost:8081").build(); }
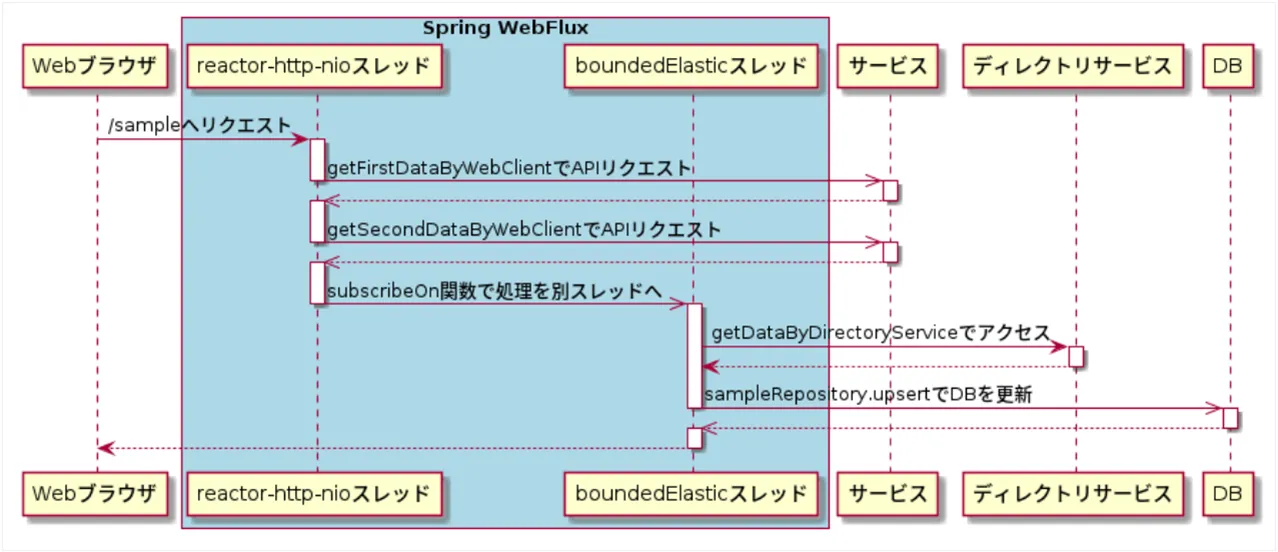
@GetMapping("/sample") // 1 public Mono<ResponseData> sample() { return this.getFirstDataByWebClient() // 2 .zipWhen(firstData -> // 3 this.getSecondDataByWebClient(firstData)) // 4 .zipWhen(tuple -> // 5 this.getDataByDirectoryServiceWrapper(tuple.getT2()), // 6 (tuple, directoryData) -> // 7 new ResponseData(tuple.getT1(), tuple.getT2(), directoryData)) .doOnNext(this.sampleRepository::upsert); // 8 } // 9
private Mono<FirstData> getFirstDataByWebClient() { return this.webClient.get() .uri("/api/v1/first") .retrieve() .bodyToMono(FirstData.class); }
private Mono<SecondData> getSecondDataByWebClient(FirstData firstData) { return this.webClient.post() .uri("/api/v1/second") .bodyValue(firstData) .retrieve() .bodyToMono(SecondData.class); }
private DirectoryData getDataByDirectoryService(SecondData secondData) { return this.directoryService.search(secondData); }
private Mono<DirectoryData> getDataByDirectoryServiceWrapper(SecondData secondData) { return Mono.fromCallable(() -> this.getDataByDirectoryService(secondData)) .subscribeOn(Schedulers.boundedElastic()); }}このサンプルソースのシーケンスを図で表すと以下のようになります。
解説
注目するポイントは、Reactorを使用した関数型プログラミングである点とブロッキング処理をMonoでラップしている点です。
先ほどSpring WebFluxの紹介でも説明しましたが、Spring WebFluxはロジックのほとんどの部分にReactorを使用します。Reactorは関数型プログラミングによって処理を構築するので、関数型プログラミングの経験が少ない方は普段のJavaとの差異に戸惑うかもしれません。Spring MVCとSpring WebFluxのサンプルソースでHTTPリクエストを実装しているメソッドを比較してみてください。Spring MVCでHTTPリクエストを行うときはRestTemplateを使用していました。RestTemplateでは1つの関数でリクエストのURLとボディのデータ、レスポンスの型を指定できます。RestTemplateは同期処理のため、戻り値を関数で指定した型で取得し、その後の処理にそのまま使用することができます。
private SecondData getSecondDataByRestTemplate(FirstData firstData) { return this.restTemplate .postForObject("http://localhost:8081/api/v1/second", firstData, SecondData.class);}Spring WebFluxでHTTPリクエストを行うときはWebClient ⧉を使用します。WebClientではHTTPメソッドを指定する関数やURIを指定する関数など、複数の関数を繋げてHTTPリクエストを行います。WebClientは非同期処理のため、戻り値をPublisher型で取得し、その後の処理はReactorの関数を繋げて実装しなければなりません。
private Mono<SecondData> getSecondDataByWebClient(FirstData firstData) { return this.webClient.post() .uri("/api/v1/second") .bodyValue(firstData) .retrieve() .bodyToMono(SecondData.class);}また、関数型プログラミングでは戻り値に注意して開発する必要があります。Spring MVCでは同じメソッドの中であれば変数に格納した値をいつでも使用することができました。しかし、関数型プログラミングでは原則として外部の変数を使用することができず、一つ前の関数の戻り値のみを入力として関数を処理します。そのため、一度でも情報を戻り値から切り捨ててしまうと再びその情報を使用することができなくなってしまいます。
Spring WebFluxのサンプルソースを例に説明します。サンプルソースではHTTPリクエストの処理をzipWhen関数で繋いでいます。zipWhen関数は1つ前の関数の戻り値(1回目のHTTPレスポンス)と引数に指定した関数の戻り値(2回目のHTTPレスポンス)を合わせてTuple2型の値を返します。
this.getFirstDataByWebClient() .zipWhen(firstData -> this.getSecondDataByWebClient(firstData))この処理を引数は変えずに、zipWhen関数をflatMap関数に変えて実装するとどうなるでしょうか。flatMap関数は引数に指定した関数の戻り値をそのままflatMap関数の戻り値として返します。つまり、1回目のHTTPレスポンスの情報を切り捨てて、2回目のHTTPレスポンスの情報のみを次の関数に渡すことになり、以降の関数では1回目のHTTPレスポンスの情報を使用できなくなります。このように、関数型プログラミングでは後の処理で使用する情報を常に考慮して開発しなければ、処理に必要な情報が参照できない事態を引き起こします。
this.getFirstDataByWebClient() .flatMap(firstData -> this.getSecondDataByWebClient(firstData))Spring WebFluxで開発するときに、最も気を付けなければならない点はブロッキング処理を作らないことです。Spring WebFluxはリクエストを処理するためのスレッドが少ない(デフォルトではランタイムで使用可能なプロセッサの数)ので、1つのリクエストがスレッドを長時間占有してしまうとすぐに詰まってしまいます。もし、どうしてもブロッキング処理を使用しなくてはならない場合は、publishOn関数やsubscribeOn関数を使用して処理を別のスレッドに移譲して、リクエストやレスポンスを処理するためのスレッドを解放するようにしましょう。
今回のソースでは、ディレクトリサービスへのアクセスがブロッキング処理になります。(DB処理はR2DBC ⧉を使用するとノンブロッキング処理に変更することができます。)そのため、ディレクトリサービスへのアクセスを行っているgetDataByDirectoryServiceメソッドをfromCallable関数を使用してMono型にラップし、subscribeOn関数を使用して処理を別スレッドに移譲しています。
private DirectoryData getDataByDirectoryService(SecondData secondData) { return this.directoryService.search(secondData);}
private Mono<DirectoryData> getDataByDirectoryServiceWrapper(SecondData secondData) { return Mono.fromCallable(() -> this.getDataByDirectoryService(secondData)) .subscribeOn(Schedulers.boundedElastic());}まとめ
Spring MVCからSpring WebFluxへ改修するときのポイントは以下になります。
- HTTP通信には同期処理であるRestTemplateではなく、非同期処理であるWebClientを使用します。
- Spring WebFluxはReactorを使用した関数型プログラミングによって処理を構築するため、それぞれの関数の戻り値に注意して設計する必要があります。
- Spring WebFluxは基本的にノンブロッキングな処理だけで構築しますが、どうしてもブロッキング処理を使用しなくてはならない場合は、publishOn関数やsubscribeOn関数を使用してブロッキング処理を別スレッドに移譲します。
おわりに
今回、Spring MVCで開発したアプリケーションをSpring WebFluxに改修してみて、リアクティブプログラミングの設計の難しさを感じました。この記事で紹介したサンプルソースはストリームのデータが1つで処理の流れも単純なため、Spring MVCからSpring WebFluxへの変更はそれほど難しくないと感じたかもしれません。しかし、実際にアプリケーションを開発する際はエラー処理や条件分岐など少々複雑な処理が含まれていることがほとんどです。さらに、ストリーム処理で扱うデータが複数になると順不同に流れてくるデータを選別したり組み合わせたりと、データが1つのときよりも処理が複雑になります。そのようなアプリケーションの設計は一筋縄ではいかないでしょう。また、zipWhen関数やflatMap関数、subscribeOn関数などの説明を行いましたが、この記事で紹介した関数はReactorの関数全体のごく一部です。より複雑な処理を行う場合、Reactorにどのような関数が存在するのかを知らないと開発をスムーズに行うことはできないでしょう。
リアクティブプログラミングは今までのJavaとは一味違うプログラミングパラダイムであるので学習コストが高く、さらにSpring WebFluxやReactorは参考になる日本語のサイトも少ないため、必要になってから学ぶのでは望んだ性能を満たすアプリケーションを構築できないかもしれません。この記事を読んでSpring WebFluxやリアクティブプログラミングに興味を持った方は、ぜひこの機会に学んでみてはいかがでしょうか。
記事の執筆にあたっては情報の正確性に努めておりますが、掲載されている文章やソースコード、設定ファイル等の内容について、完全な正確性や安全性を保証するものではありません。活用される際は、必ず公式ドキュメント等をご自身で確認のうえご判断ください。
