

[!] この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
当社は、日頃から他社の決算短信から業績データを収集し、お客様や同業他社など周辺環境の把握に役立てています。従来は、業績データの収集に外部のAPIサービスを利用していましたが、昨年そのAPIサービスが突如終了してしまったことから、急遽、業績データ取得ツールを自作することになりました。
作成した業績データ取得ツールは、東京証券取引所の適時開示情報閲覧サービス ⧉(以降、TDnet)に公開される決算短信から業績データを取得してデータベースに保存しておき、利用者が必要な時にWebブラウザで参照出来るといったものです。これをAWSを用いてサーバレスで構築しました。
この記事では、構築したツール内部の処理内容と、AWS上のどのようなサービスを組み合わせて構築したかをご紹介します。
サマリー
主な紹介内容は、以下の通りです。まずは全体像が分かるようAWS上の構成からご紹介していきます。
- 使用したAWS上のサービスと全体構成
- 業績データを取得するツール内部の処理内容
使用したAWS上のサービスと全体構成
使用したサービス
業績データ取得ツールを構築するにあたり、AWS上の以下のサービスを使用しました。
| サービス名 | 用途 |
|---|---|
| SageMaker | 開発環境(Jupyter Notebookを使用) |
| Lambda | 開発環境で作成したプログラムの実行環境 |
| CloudWatch | ログの記録やイベント設定 |
| DynamoDB | 業績データを保管するデータベース |
| S3 | 決算短信やAPI呼出し用HTMLを保管するストレージ |
| API Gateway | Web APIとして提供するための設定 |
全体構成
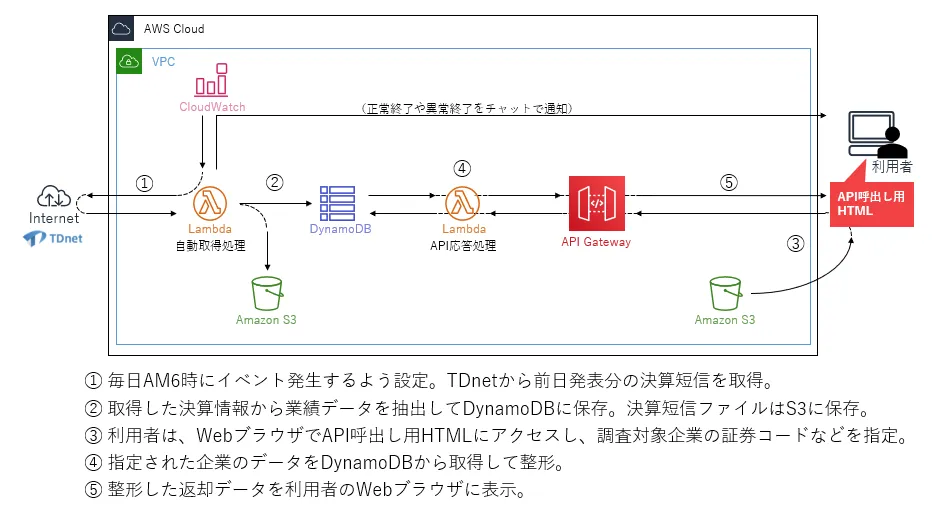
Lambdaには、TDnetから業績データを自動取得する処理(以降、自動取得処理)や、Web APIの呼出しに応える処理(以降、API応答処理)などを実装しました。
自動取得処理はCloudWatchのイベント設定を用いて毎朝6時に自動実行するよう設定し、取得した業績データはDymanoDBに、決算短信のファイル類も参考用に取得してS3に保存しました。また、API応答処理はAPI Gatewayを用いて社内からアクセスできるよう設定しました。
S3にはAPI呼出し用HTMLも保存しており、利用者はこれをWebブラウザから利用することができます。API呼出し用HTMLは、HTML内のJavaScriptでAPIを呼出せるよう作成しました。
業績データを取得するツール内部の処理内容
作成した主なツールは、自動取得処理、API応答処理、API呼出し用HTMLの3つです。自動取得処理とAPI応答処理は、AWSのSageMaker(Jupyter Notebook)上にPythonで作成しました。
自動取得処理
自動取得処理は、TDnetから決算情報を取得し、そこから必要な業績データを抽出してDymanoDBに保存する処理です。決算情報は決算短信ファイルの他、XBRL (eXtensible Business Reporting Language) と呼ばれるXMLベースのフォーマットで公開されているため、ここから業績データを抽出しました。
TDnetから決算情報を取得
まずは当日開示されている情報のリストを取得していきます。リストページの解析にはBeautifulSoup ⧉というHTMLをパースするライブラリを用いました。
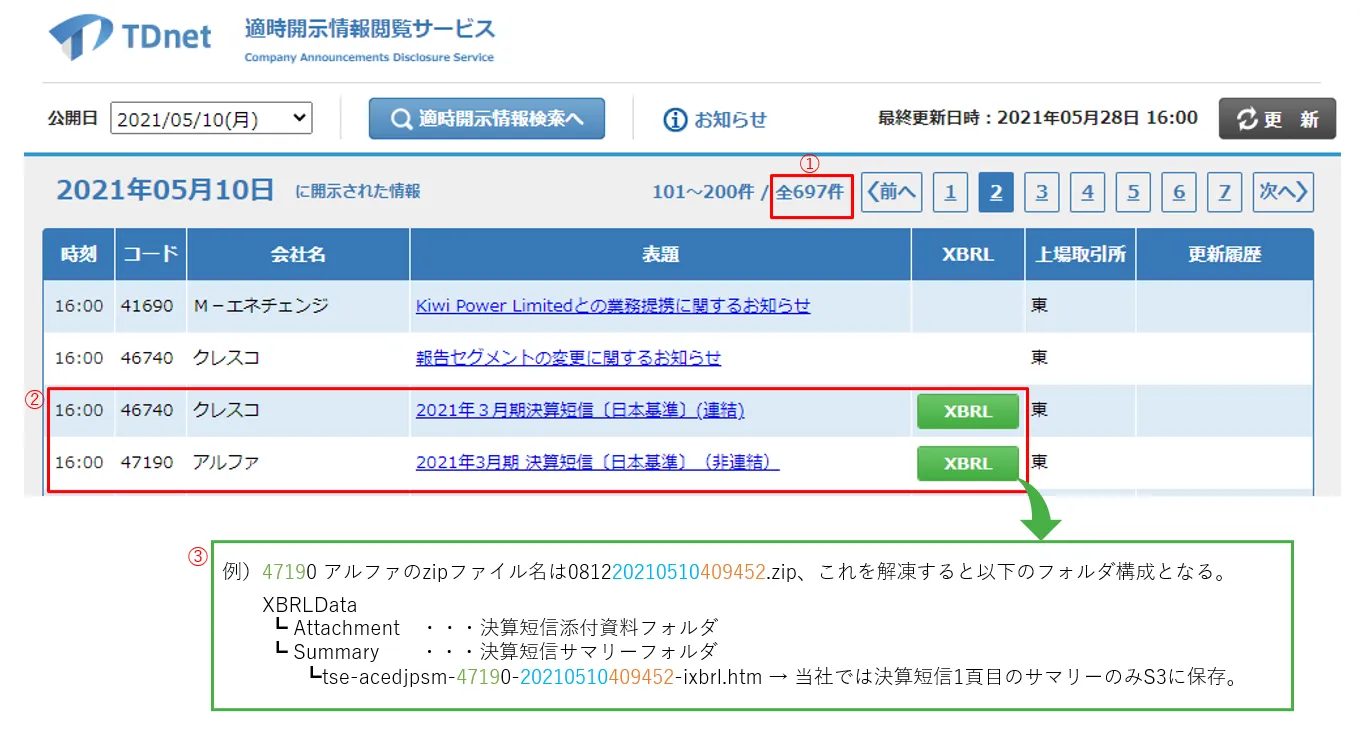
TDnetには発表日ごとに決算短信などの情報を公開する頁があります。1日の発表が100件を超過した場合は複数頁に分けて公開されるため、同じ発表日にある全頁から情報取得する必要があります。
①画面内の全件数の表示から全頁数を算出し、発表日に含まれる全頁のURLを割り出し
※各頁のURL=https://www.release.tdnet.info/inbs/I_list_XXX_YYYYMMDD.html(XXX=頁番号、YYYYMMDD=公開日)
②各頁の決算短信開示の行データを取得し、XBRLファイルが一式入っているZIPファイルをダウンロード
③ZIPファイルを解凍して必要なXBRLファイル「~~~-ixbrl.htm」をS3に保存(XBRLファイルの説明については後述)
※XBRLファイル名の命名規約はTDnetの適時開示情報サイト ⧉の「適時開示システム タクソノミ設定規約書」を参照
業績データを抽出してDymanoDBに保存
次にXBRLファイルから必要な業績データを取得してDymanoDBに保存していきます。ここでも前述のBeautifulSoup ⧉を用いました。
XBRLファイルは、ブラウザで表示すると決算短信のPDFと同じ表示イメージになりますが、ソースを表示すると下図のようにixタグがインラインで埋め込まれています。このixタグ一つ一つが決算短信内の各情報を示しており、ここから、社名などの基本情報や主な業績データの前期実績、今期実績、来期予測を取得しました。
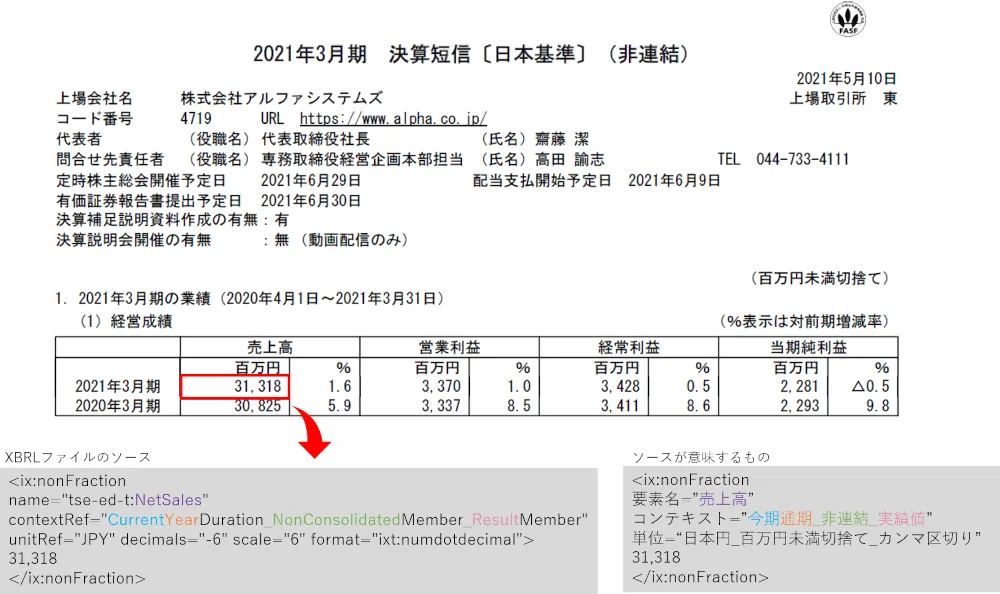
※XBRLファイル内の要素名やコンテキストの詳細は、TDnetの適時開示情報サイト ⧉の「決算短信サマリー報告書インスタンス作成要領」を参照
API応答処理とAPI呼出し用HTML
API応答処理は、APIの呼出しに応じてDynamoDBから決算期の一覧や業績データを取得し、整形して返却する処理です。API GatewayでAPI応答処理のLambdaを実行するREST APIを作成しました。

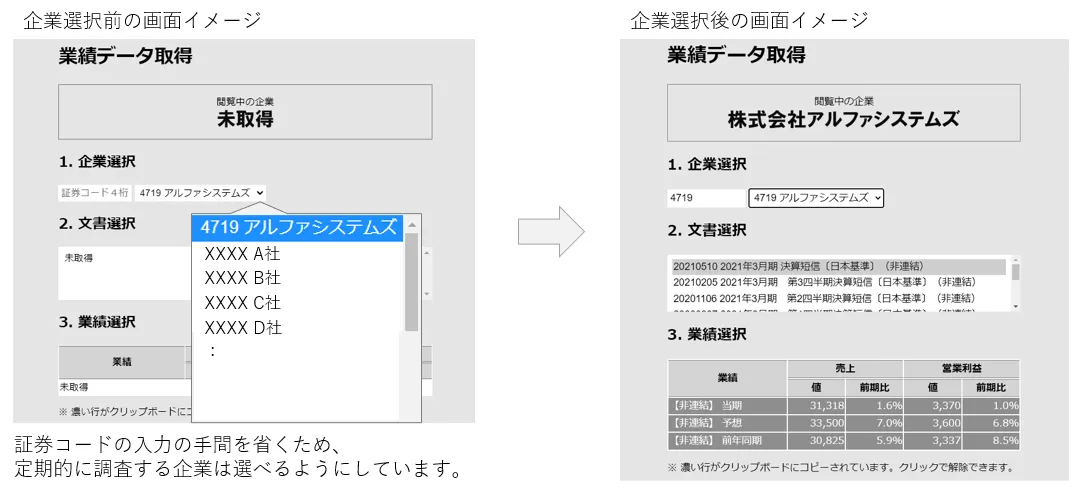
これを下の図のようなAPI呼出し用HTMLを作成して利用しています。当社では、定期的に調査する企業が決まっているので、企業名を選択するだけで業績データを取得できるようにしました。
まとめ
外部のAPIサービスが突如終了したことに伴い、急遽作成し直すことになりましたが、以前利用していた外部のAPIサービスより応答も早く大変便利に使用できています。毎日粛々と業績データを蓄積してくれますし、なんといっても、サーバレスで組むことができ、仮想サーバを常時確保しておく必要がなくなったのが大きいです。
今後の課題は、Lambdaの処理が15分間でタイムアウトすることから1日における決算短信の掲載量が多いと処理が中途半端に終了してしまう点の改善です。現状はチャットに表示されるタイムアウトの通知をうけ、手動で実行して取り損なったデータを取得しています。処理時間の削減や自動で再実行するなどの対処を考えていきたいと思います。
