

[!] この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
物体検出とは
物体検出は、画像・動画内に写っている物体の位置とクラス(人間、車といったカテゴリー)を特定する方法です。
代表的なものとして、顔検出や自動運転などに応用されています。
物体検出の分野では、R-CNN, YOLO, SSDなどの深層学習を用いた手法が開発され、幅広く使われています。
今回は、YOLOv5 ⧉を使って、物体検出をします。
YOLOv5は、2020年6月に公開された最新の物体検出手法です。 他の手法と比べて超高速で、リアルタイムでの実行も可能です。 また、自作データセットをYOLOv5で簡単に学習できることも特徴です。
環境構築
YOLOv5は、Pythonで動作するので、事前にPythonをインストールしてください。
この記事の開発環境は以下の通りです。
| バージョン | |
|---|---|
| OS | Windows 10 Pro |
| Python | 3.9.5 |
Pythonの仮想環境を作成
Pythonの開発では、パッケージのバージョン違いや依存関係が問題になることがよくあります。
そのため、仮想環境を作成して開発をおこなうことが一般的です。
ここでは、venv-yolov5という名前の仮想環境を作成します。
以下のコマンドを実行して、仮想環境を作成し、作成した仮想環境を有効化させます。
> python -m venv venv-yolov5> ./venv-yolov5/Scripts/activate以下のように表示されていれば、仮想環境が有効化されています。
(venv-yolov5) >YOLOv5の準備
YOLOv3のPyTorchバージョンを開発していたUltralyticsが、GitHubにYOLOv5のリポジトリを公開しています。
そのリポジトリからYOLOv5をダウンロードします。
> git clone https://github.com/ultralytics/yolov5必要なライブラリをインストールします。
> cd yolov5> pip install -r requirements.txtこれでYOLOv5を使用する準備は完了です。
事前学習済みモデルを使用した物体検出
data/imagesに物体検出をしたい画像を保存します。
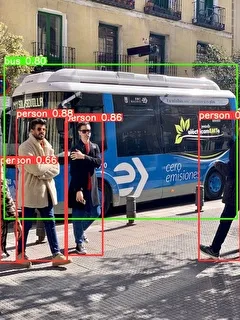
今回は、サンプルとして保存されている以下の画像(data/images/bus.jpg)に対して、物体検出してみます。

detect.pyを実行すると、初回起動時にYOLOv5の学習済みモデルがダウンロードされます。
これは、80クラス(人、バス、車など)について事前に学習したモデルです。
事前学習済みモデルは、PyTorch Hub ⧉に公開されているモデルがダウンロードされます。
またYOLOv5のモデルには、YOLOv5s, YOLOv5m, YOLOv5lなどがあり、それぞれ精度や処理速度に違いがあります。[1][2]
以下のコマンドを実行して、物体検出をします。
> python detect.py --source data/images/bus.jpg --conf 0.5 --weights yolov5s.pt上記のコマンドの引数は以下の通りです。
- source:画像のフォルダ、または画像のパスを指定。
- conf:指定した値以下の確率値は表示しない。
- weights:事前学習済みモデルの重みファイルを指定。
実行後、フレームとラベル付きの画像ファイルがruns/detect/expに保存されます。
実行後の画像ファイルを見てみると、person(人)とbus(バス)が検出されています。
画像内で見切れている人の検出もできていることが分かります。
自作データセットを用いたYOLOv5での学習
前節では事前学習済みのモデルを使用して、物体検出をしました。
次に、自分でデータセットを作成して、YOLOv5で学習してみます。
今回は、猫の検出をしてみたいと思います。
データセットの準備
まずはじめに、教師データとなる猫の画像を大量に集めます。
300枚程度あれば、高確率で検出できると思います。少なすぎると検出ができなかったり、精度が悪くなったりします。
ネット上で十分な画像が入手可能な場合は、Google画像検索などを活用して収集するとよいです。
次に、猫の画像にアノテーションをつけていきます。
アノテーションとは、画像に対して物体がある位置とクラスの注釈をつけることをいいます。
YOLOv5では、学習のために画像とアノテーションファイル(.txt)のペアが必要です。
画像cat01.jpgに対して、アノテーションファイルcat01.txtを作成する必要があります。
アノテーションファイルには、物体の位置情報が保存されており、以下のようなYOLO形式のものを用意します。
# [oject-class] [x_center] [y_center] [width] [height]0 0.260000 0.350000 0.303333 0.4200000 0.591667 0.603750 0.420000 0.492500このアノテーションをおこなうために、アノテーションツールを使います。
物体検出用のアノテーションツールとして、VoTT ⧉, labelImg ⧉などいくつか種類があるので使いやすいものを使用してください。
今回は、VoTTというツールを使用してアノテーションをつけていきます。保存する際は、YOLO形式で保存するようにします。
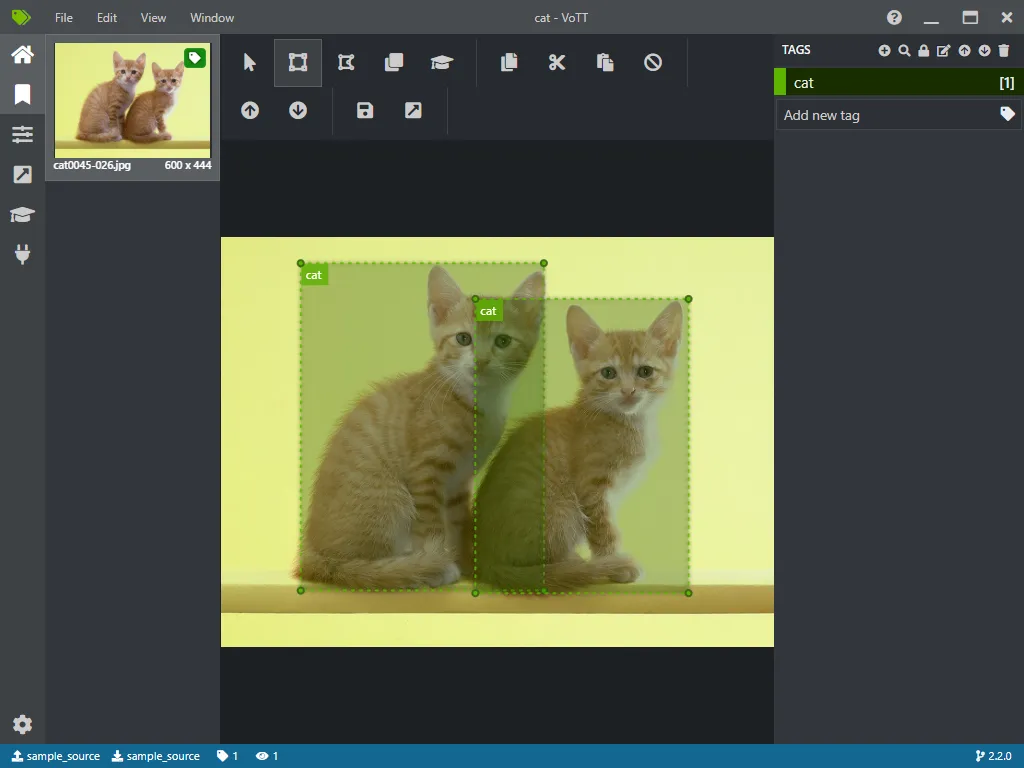
すべての画像にアノテーションを付けたら、データセットの準備は完了です。
学習
以下のようにディレクトリを作成してください。
trainフォルダ:学習用の画像およびアノテーションファイルを入れるフォルダです。validフォルダ:検証用の画像を入れるフォルダです。画像が入っていないと実行に失敗するので注意してください。
前節で作成した画像とアノテーションファイル(.txt)をtrainフォルダに配置してください。
yolov5 ┠ data ┠ train ┃ ┠ images ┃ ┃ ┗ *.jpg ┃ ┗ labels ┃ ┗ *.txt ┠ valid ┗ images ┗ *.jpg次に、dataフォルダ内にdata.yamlを作成します。
data.yamlはデータセットの設定ファイルです。
train: data/train/images # 学習の画像のパスval: data/valid/images # 検証用画像のパス
nc: 1 # クラスの数names: [ 'cat' ] # クラス名以下のコマンドを実行して、学習させます。
> python train.py --data data/data.yaml --cfg yolov5s.yaml --weights '' --batch-size 8 --epochs 300上記の引数は以下の通りです。
- data:データセットを指定。
- cfg:使用する学習モデルを指定。今回は、YOLOv5sを使用。
- weights:重みファイル(ニューラルネットワークにおいて入力値の重要度などを数値化したもの)を指定。
- batch-size:GPUで使用するメモリを指定。
- epochs:エポック数(学習回数)を指定。
今回は、猫の画像を100枚用意、CPUを使用して学習時間は約8時間でした。GPUを使用すれば、学習時間は短くなります。
学習が完了すると、runs/train/exp/weightsにlast.pt, best.ptのファイルが生成されます。
このファイルが学習モデルの重みファイルになります。
この重みファイルを利用して、物体検出ができます。
物体検出
前節で学習させたモデルを使用して物体検出をしてみます。
best.ptを重みファイルとして使用します。
best.ptをyolov5ディレクトリの直下へコピーします。
引数weightsにbest.ptを指定して、物体検出をします。
> python detect.py --source data/images/ --weights best.pt確率値が41%と精度は低いですが、猫の検出に成功しました。

これで、自作データセットを使用した学習モデルを使用して、物体検出ができます。
まとめ
今回は、YOLOv5の導入から自作データセットを用いて学習するところまでを紹介しました。
YOLOv5は他の手法に比べて、学習時の細かいチューニングが必要なく、簡単に使用できます。
より精度の高い検出をしたい場合は、作成した学習モデルを分析することが必要です。
データのサンプルが少ない、過学習をしているなど問題点が見つかり、より精度の高い学習モデルの作成につながります。
ぜひ一度、独自データで実践してみてください。
参考文献
- [1]: PyTorch Hub YOLOv5, https://pytorch.org/hub/ultralytics_yolov5/ ⧉
- [2]: YOLOv5 release ,https://github.com/ultralytics/yolov5/releases/tag/v5.0 ⧉
記事の執筆にあたっては情報の正確性に努めておりますが、掲載されている文章やソースコード、設定ファイル等の内容について、完全な正確性や安全性を保証するものではありません。活用される際は、必ず公式ドキュメント等をご自身で確認のうえご判断ください。
