

[!] この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
私たちのチームではJava + Spring Boot を使用してWebアプリケーションのバックエンドAPIを構築しています。バックエンドの開発にはデータベースとのやり取りが必須になります。この記事ではデータベースCRUD処理の開発に役立つORMについて解説し、実際に私たちのチームでSpring Data JPA を採用したエピソードと、最後に導入方法について紹介します。
ORMとは
ORM(Object-Relational Mapping)とは、アプリケーションのオブジェクトとリレーショナルデータベース(以下「DB」)のレコード、およびオブジェクト間の関連とテーブル間のリレーションシップを相互にマッピング(対応付け)する技法です。
ORMを実現するための機能やソフトウェアをORマッパーといいます。
これらはプログラミング手法にオブジェクト指向、データストアにリレーショナルデータベースを使用した際に、SQLクエリ結果を1行ずつ取り出しJavaオブジェクトに詰めるといった開発者の負担を軽減できます。
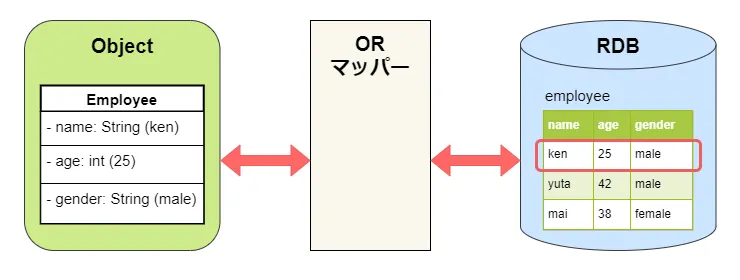
ORマッパーのメリット
採用するORマッパーにより機能の差異はありますが、基本的に以下の機能を提供します。
-
インピーダンスミスマッチの解消
オブジェクト指向のオブジェクトは「現実世界に即したデータモデル」であるのに対し、リレーショナルデータベースは「データの検索や更新などの処理に最適化されたデータモデル」です。この設計思想の違いをインピーダンスミスマッチといい、これによりデータのマッピングが煩雑になります。
ORマッパーではこうしたオブジェクトとDBレコード間のデータマッピングを自動で行います。自動マッピングにより開発者はSQLクエリ結果からJavaオブジェクトへデータを詰める作業から開放され、テーブル構造を意識せずともデータの取得や永続化が可能になります。 -
ボイラープレートコードの排除
ボイラープレートコードとは、言語仕様により複数の場所で繰り返される定型コードです。本来実装したい業務ロジックとは直接関係しないコードとなります。
JavaのDBアクセスにおいては以下の処理に関するコードが挙げられます。- プリペアドステートメントの作成/値セット
- リザルトセットからのデータ取得……など
ORマッパーの導入によりこれらのボイラープレートコードをソースコードから排除でき、開発効率の向上・可読性の向上などが期待できます。
-
プリペアドステートメントによるサニタイジング
クエリを発行する方法は各ORマッパーにより様々ですが、SQLを自動生成することが可能なものがあります。
そうしたORマッパーでは開発者が明示的にSQLを書く必要が無くなるため、SQLインジェクションのリスクを回避することができます。
ORマッパーのデメリット
ORマッパーの導入によって以下のデメリットをもたらす可能性があります。
-
SQLチューニングができない
SQL自動生成機能を持つORマッパーでは、SQLパフォーマンスを改善しようと思っても、開発者が改善対象のSQLを直接編集することができず、パフォーマンス改善の障壁になる場合があります。
ただし、中には明示的にSQLを記述して問合せを行うことができるものもあります。 -
ORマッパーがSQLを自動生成する際に、適切にJOINを行ってくれずN+1問題を引き起こす場合があります。これによりDBからデータを取得する処理のパフォーマンスが低下する恐れがあります。
これにはソースコード内で明示的にJOIN句を含むSQLを記述するか、ORマッパーのローディング(フェッチ)設定を「EAGER」にすることでN+1問題を解決できる場合があります。
JPA・Spring Data JPAとは
JPA(Java Persistence API)とは、Jakarta EE(Java EE)標準のORマッパーです。JPAは仕様(Interface)のみ提供し、その実装はJPAプロバイダより提供されます。
Spring Data JPAとは、Springフレームワーク群のSpring Dataファミリー内のデータベースプロジェクトの1つです。
その名のとおりJPAをベースとしており、JPAを使いやすくラップしたものがSpring Data JPAです。
Spring Data JPAではデフォルトのJPAプロバイダとしてHibernate ⧉を使用します。
Spring Data JPAを使用して
実際に私たちのチームでORマッパーとしてSpring Data JPAを採用した理由と、開発に取入れてみてのメリット/デメリットを紹介します。
ORマッパーの選定
一言に「ORマッパー」といっても、JDBC ⧉を薄くラップしたものから、データのマッピング以外にも多様な機能を提供するものまで、その種類は様々です。
基本的に機能が少なくSQLネイティブなORマッパーほど、その学習コストが低くなります。
反対に高機能でJavaネイティブに使用できるORマッパーほど複雑性が増し、固有知識の習得が必要になります。
どのようなORマッパーが最適なのかをプロジェクトによって判断していく必要があります。
ORマッパーの選定については次のスライドが参考になります。
Java ORマッパー選定のポイント(2019/1/31 株式会社カサレアル 多田真敏氏) ⧉
私たちのチームでは次の理由からSpring Data JPAを採用しました。
-
DBアクセス処理に起因するバグを減らすため
開発者が記述するコード量が増えるほどバグが増えやすいという考えのもと、高機能で、開発者のコード記述量が少なくて済むものを採用しました。
-
開発効率を上げるため
これもバグ削減と同様に、実装に伴うコード記述量を減らすためです。また記述量が減ることによって可読性が向上し、コード修正やコードレビューの敏捷性が高まることを期待して採用しました。
-
教育/学習コストを最小限に抑えるため
開発経験が少なくDBに対して深い知識を持たないメンバーのアサインが多くあったため、DBを意識せずとも開発が可能な強力なORマッパーを探していました。また開発チーム内にDBやJPAに詳しくデータマッピングの設定ができるメンバーが1人以上いれば、その他のメンバーは永続化コンテキストやEntityManager等の複雑なJPAの仕様を理解しきらずとも多くの機能を効率的に利用できることから、Spring Data JPAを採用しました。
Spring Data JPA導入による効果
私たちのチームでは、Spring Data JPA導入の結果、以下の効果を得ることができました。
-
メンバーのアサインを早めることができた
DB関連知識の学習/教育コストを削減することによりアサイン前の学習期間を短縮し、プロジェクトへのアサインを早めることができました。また業務ロジックの開発に意識とリソースを集中させることができました。
-
長く複雑なSQLをソースコード内から排除することができた
それまでソースコード内に直書きしていたSQLを、Spring Data JPAのQuery Methods ⧉機能を使用して排除することができました。
-
クエリ結果をJavaオブジェクトに詰める処理をソースコード内から排除することができた
結果を詰め替えるだけのボイラープレートコードをソースコード内から排除し、開発効率とソースコードの可読性が向上しました。
Spring Data JPA導入に伴う課題
開発ノウハウ引継ぎの体制が整っていなかった
教育/学習コストを低く抑える事ができるという期待から導入したSpring Data JPAですが、これはプロジェクト内に1人以上DBやJPAの仕様に詳しい人がいる前提での採用でした。
長期のプロジェクトで「プロジェクトの期間」が「1メンバーが開発に携わる期間」よりも長いことを考えると、開発/技術ノウハウの引継ぎにある程度の労力が必要になります。それらの知識を引継ぐ体制の構築が課題のひとつです。
Spring Data JPAの導入方法
Spring(Java)プロジェクトにSpring Data JPAを導入する方法を紹介します。
ファイル構成
sample└── src └── main └── java └── jp └── co └── alpha └── sample ├── Sample.java ├── SampleApplication.java ├── model │ ├── Department.java │ └── Employee.java └── repository └── EmployeeRepository.java-
ビルドツールの依存関係にSpring Data JPAプロジェクトを追加する
pom.xml (Mavenの場合)
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency>build.gradle (Gradleの場合)
dependencies {implementation 'org.springframework.boot:spring-boot-starter-data-jpa',} -
Entityに、対応するDBテーブルの情報を付与する
次のようなテーブル定義の場合
CREATE TABLE departments (department_id INT PRIMARY KEY,department_name TEXT NOT NULL);CREATE TABLE employees (employee_id INT PRIMARY KEY,name TEXT NOT NULL,mail_address TEXT NOT NULL,department_id INTEGER NOT NULL REFERENCES departments(department_id));サンプルレコード
INSERT INTO departments VALUES(1, '経理部'),(2, '総務部'),(3, '企画部');INSERT INTO employees VALUES(1, 'アルファ太郎', 'taro@alpha.co.jp', 1),(2, 'アルファ次郎', 'jiro@alpha.co.jp', 1),(3, 'アルファ花子', 'hanako@alpha.co.jp', 3);以下のようにクラスにDBテーブルの情報を付加します。
Department.javapackage jp.co.alpha.sample.model;import javax.persistence.Column;import javax.persistence.Entity;import javax.persistence.Id;import javax.persistence.Table;// テーブルとマッピングを行うオブジェクト(Entity)であることを明示@Entity// 対応するテーブル名を明示@Table(name = "departments")public class Department {// 主キーに付加@Id// 対応するカラム名を明示@Column(name = "department_id")private int id;@Column(name = "department_name")private String name;// コンストラクターおよびアクセサーメソッド 省略}Employee.java
package jp.co.alpha.sample.model;import javax.persistence.Column;import javax.persistence.Entity;import javax.persistence.Id;import javax.persistence.Table;@Entity@Table(name = "employees")public class Employee {@Id@Column(name = "employee_id")private int id;// フィールドとカラムが同名の場合は@Column不要private String name;// camelCase → snake_case の変換を行って一致するカラム名がある場合も@Column不要// カラム名: mail_addressprivate String mailAdress;private int departmentId;// 結果確認用@Overridepublic String toString() {return "id: " + this.id + "\n"+ "name: " + this.name + "\n"+ "mailAddress: " + this.mailAddress + "\n"+ "departmentId: " + this.departmentId + "\n";}// コンストラクターおよびアクセサーメソッド 省略} -
Repositoryインターフェースを作成する
JpaRepositoryインターフェースを継承したインターフェースを宣言することで、JpaRepository ⧉が提供するメソッドを実装することができます。
EmployeeRepository.java
package jp.co.alpha.sample.repository;import org.springframework.data.jpa.repository.JpaRepository;import org.springframework.stereotype.Repository;import jp.co.alpha.sample.model.Employee;@Repository// JpaRepository<操作対象のEntity, 操作対象Entityの主キーの型>public interface EmployeeRepository extends JpaRepository<Employee, Integer>{} -
Repositoryインターフェースの利用
package jp.co.alpha.sample;import java.util.List;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import jp.co.alpha.sample.model.Employee;import jp.co.alpha.sample.repository.EmployeeRepository;@Configurationpublic class Sample {// EmployeeRepositoryをインスタンス化// EmployeeRepositoryの実装(Implementation)はSpring Data JPAにより生成される@Autowiredprivate EmployeeRepository employeeRepository;@Bean(initMethod = "init")public void sysoutEmployees() {// findAll()でemployeesテーブル全件取得List<Employee> employeeList = employeeRepository.findAll();employeeList.forEach(employee -> System.out.println(employee));}}
実行結果
$ mvn spring-boot:run...id: 1name: アルファ太郎mailAddress: taro@alpha.co.jpdepartmentId: 1
id: 2name: アルファ次郎mailAddress: jiro@alpha.co.jpdepartmentId: 1
id: 3name: アルファ花子mailAddress: hanako@alpha.co.jpdepartmentId: 3...以上のようにEntity, Repositoryを定義することで、EmployeeRepositoryクラスを介してDBから目的のレコードをEmployeeエンティティに取得することができます。またsave ⧉メソッドを使用してレコードの挿入や更新処理、delete ⧉メソッドを使用してレコードの削除処理をそれぞれ行うことができます。
おわりに
ORMおよびORマッパーの役割、それから実際に私たちのチームでSpring Data JPAを使用した事例について紹介しました。
オブジェクト指向 × リレーショナルデータベースによる開発は現在多くのプロジェクトで行われています。また今後も当分の間はこれらのパラダイムに則った技術を使用しての開発が行われるものと思います。その際に必ずオブジェクト指向とリレーショナルデータベースの設計思想の違いにより、データマッピングに関する不都合が生じます。それらをプロジェクトの方針や実情に合わせてどのように対応していくのか。それを考える上での参考になれば幸いです。
