
[!] この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
近年、人工知能(AI)と自然言語処理(NLP)の進化に伴い、RAG(Retrieval-Augmented Generation)システムは多くの応用領域で重要な機能を果たしています。RAGシステムは、生成AIに情報の検索を組み合わせて、より専門的な内容に即した回答を提供することを目的としたシステムで、それによりユーザーは専門的な情報であっても必要な情報を迅速に得ることができ、業務や学習の効率が向上します。
しかし、RAGシステムは必ずしも高い精度で回答を生成できるとは限りません。システムの出力が期待に応えない場合、ユーザーは不満を抱き、さらなる利用をためらう可能性があります。
実際にRAGシステムを運用している場合、ユーザーからは『期待していた回答とは大きく異なる回答が返ってくる』などの問い合わせが寄せられることがあります。
そこでRAGシステムの精度を向上させるためには、RAGシステムの出力が複数の機能によって連携して生成されていることを踏まえ、システム全体の評価と各構成要素の詳細な解析が不可欠です。
一般的に、RAGの精度を測る指標としてRagas評価指標や、Recall@k、Precision@kなどがありますが、この記事ではそういった評価指標ではなく、私がRAGシステムの精度改善プロジェクトに従事した経験から得たポイントや注意点を解説します。
RAGシステムの構成要素
RAGシステムに詳しくない人のために、基本的なRAGシステムの概要を説明します。
基本的なRAGシステムは以下の3つの機能で構成されています。

ドキュメントをデータベースに登録し、そこから必要な情報を検索して生成AIに渡すことで、回答を生成します。
これらの機能の出来が回答精度に影響します。
それぞれの機能はそれぞれ以下のような役割を持っています。
-
データベース
あらかじめドキュメントをデータベースに保存しておきます。
ここでは例えば以下のようなテクニックが使われています。それぞれの意味や概要はこの記事では割愛します。- OCR(テキスト化)
- チャンク化
-
検索システム
ユーザーからの質問をもとにデータベースのドキュメント(チャンク)を検索します。
ここでは例えば以下のようなテクニックが使われています。それぞれの意味や概要はこの記事では割愛します。- キーワード抽出
- 全文検索
- ベクトル検索
-
生成AI(LLM)
検索システムで検索してきたチャンクを受け取り、回答を生成します。
RAGシステムの精度改善プロセス
RAGシステムが主にどのような機能で構成されているかわかったところで、精度の改善プロセスを説明していきますが、まずは今回想定するRAGシステムについて説明します。
RAGシステムの処理フロー
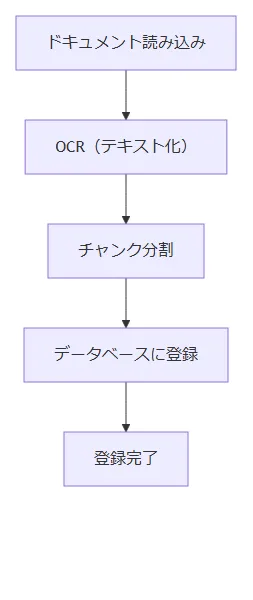
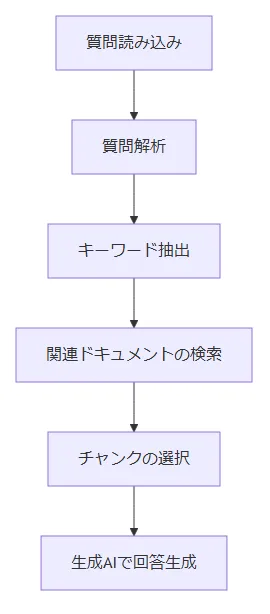
RAGシステムでは精度向上のためにさまざまな技術要素が採用される場合がありますが、この記事では改善プロセスの説明に焦点を当てるため、基本的な機能のみを備えた以下のフローで動作するRAGシステムを想定します。
[ドキュメント登録時]
[質問時]
改善プロセス
RAGシステムでの改善プロセスの基本は、評価・解析・改善の繰り返しです。
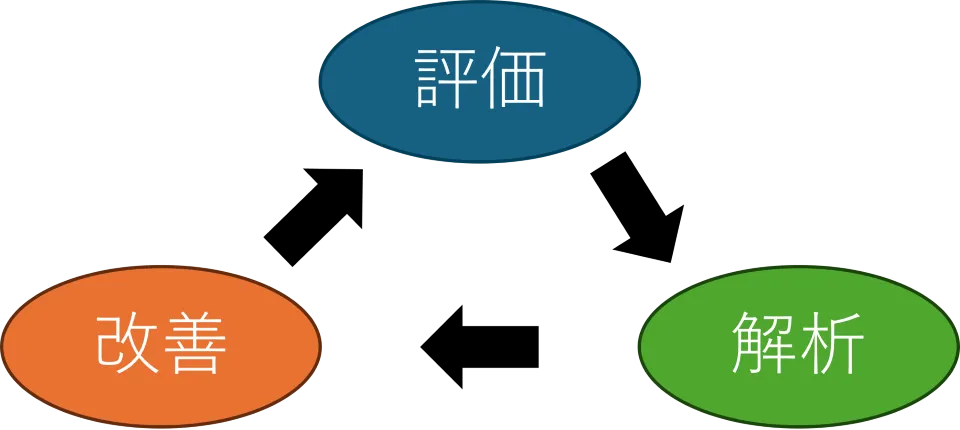
このプロセスは一般的に、物事の問題解決においての基本ともなりますが、RAGシステムの精度改善においても同じで、かなり重要なことです。
それぞれの流れを具体的に説明していきます。
現状の評価と原因の解析
作成したRAGシステムの精度が低く感じられた場合、まずは現状のRAGシステムの評価をおこないます。
はじめに、ドキュメント・質問・想定回答のセットになったテストケースを準備します。
テストケースが準備できたら以下のフローでRAGシステムの評価をおこないます。
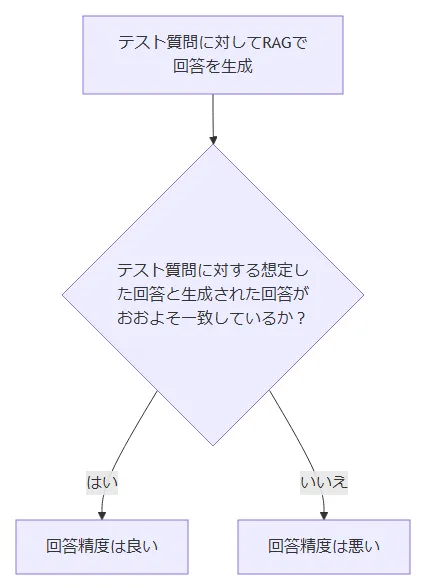
次に、回答精度が悪かったケースを使って解析を始めますが、RAG関連のシステムでは、その構造の複雑さや技術的なハードルから、問題点の解析が困難だと感じることがよくあります。そのため、解析をおこなう代わりに、精度向上に効果がありそうな手法を直接試すことで精度向上をしようとする場合もあります。
しかし、RAGシステムにおいてシステム内部で「処理フローのどこで回答に必要な情報が失われているのか」を特定しない限り、技術的・構造的な問題が放置されたままになり、表面的なテクニックの使用では精度の向上は望めません。
例えば、「現状のシステムで検索システムは正常に動作しているにも関わらず、新たにベクトル検索機能を導入した結果、回答精度がほとんど改善しない」ケースがあります。この中では、検索システム自体の問題ではなく、回答生成プロセスのどこかに問題が潜んでいる可能性が高いわけです。
また、別の例として「ドキュメントそのものに回答に必要な情報が欠けている場合」が挙げられます。この場合、いくらシステム側でアルゴリズム改善や新たな検索技術を取り入れても、想定した回答を得ることはできません。
これらの例からわかるように、回答精度の問題は必ずしもシステム側の技術だけに起因しているわけではありません。しかし実際の改善業務では、ドキュメントに問題があるケースであっても、システム側での対応によって解決を試みることが多く見られます。このような場合には、システムの構造やドキュメントの内容を包括的に解析することが重要です。
原因の解析と改善
それでは原因の解析プロセスを解説します。
先ほどの評価で回答精度に課題があったテストケースに対して、以下のプロセスで解析を行います。
-
想定回答につながる情報がドキュメントに含まれているか確認する
-
想定回答につながる情報がデータベース内のチャンクに含まれているか確認する
-
想定回答につながる情報が載ったチャンクが検索結果に含まれているか確認する
-
想定回答につながる情報が載ったチャンクが回答生成時にLLMに渡されているチャンクに含まれているか確認する
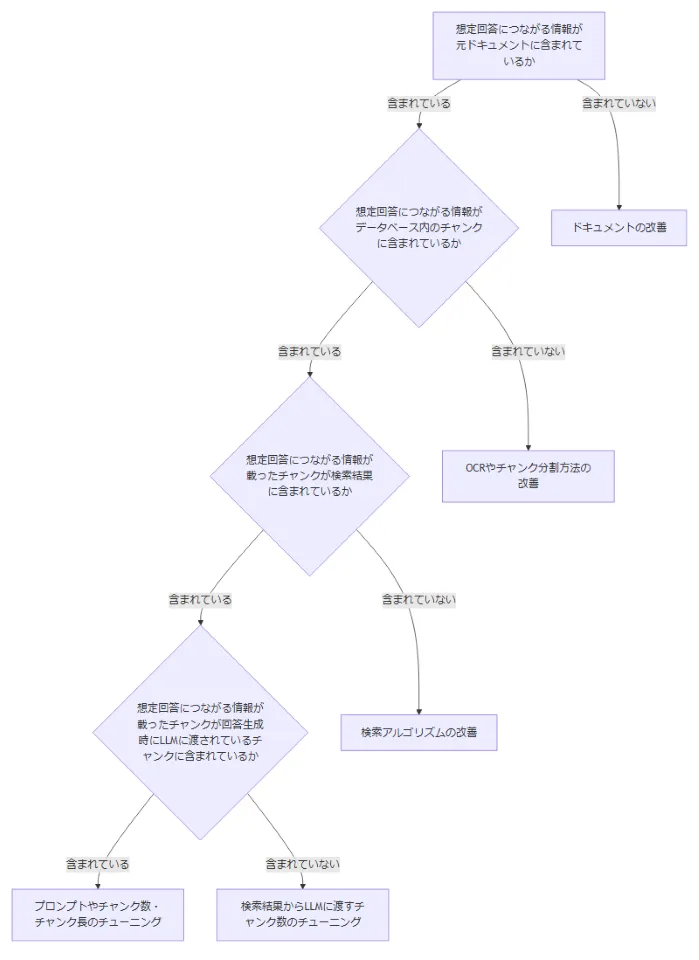
1. 想定回答につながる情報がドキュメントに含まれているか確認する
ドキュメントに想定回答を導き出すための十分な情報が含まれているかを確認します。
想定回答に必要な情報がドキュメントに含まれていない場合、ドキュメントの内容を修正する必要があります。
必要な情報がドキュメントの時点で不足していると、システム側ではどのような改善を施しても精度の改善は見込めません。
実際の業務では、精度が低い原因をシステム側の問題と捉えがちで、実はドキュメント自体に必要な情報が欠けているという問題に気付かないケースがよくあります。
2. 想定回答につながる情報がデータベース内のチャンクに含まれているか確認する
RAGシステムにおいて、一般的にドキュメントをデータベースに登録する際には、さまざまな形式のドキュメントファイル(Excel,PowerPoint,Word,Text,Markdown,PDFなど)をテキスト化し、チャンク分割を行います。これにより、LLMでの処理を可能にします。
さまざまなチャンクの分割方法がありますが、もっとも基本的な分割方法は文字数で分割する方法です。
そのような処理を施されたチャンクに、回答に必要な情報が含まれているか確認します。
テキスト化・チャンク分割されたデータに回答に必要な情報が含まれていない場合や途中で区切られて意味の通らない情報になってしまっている場合、以下のようなアプローチが有効と考えられます。
-
OCR(テキスト化)の仕組みの改善
ドキュメントでは視覚的な情報がテキスト化によって失われることが多くあります。 とくに矢印や画像、色を使った表現がうまくテキスト化できない場合が多いです。
視覚的情報をテキスト化する場合は、視覚的情報をもった部分を一枚絵として一度画像でLLMに読み込ませ、情報を言語化してもらうなどのアプローチが考えられます。 -
チャンクの分割方法の改善
文字数でチャンクを分割する単純な方法では、必要な情報が途中で分割されて欠ける場合があります。
どのような情報の欠け方をしているかを確認して、それに合わせてOCRを改善するかチャンクの分割方法を改善するかを決定します。
3. 想定回答につながる情報が載ったチャンクが検索結果に含まれているか確認する
RAGシステムでは、質問文を基にデータベース内のチャンクを検索し、関連性のあるものを選択して使用します。
ここでは、想定回答に必要なチャンクが適切に検索されているかを確認します。
想定した回答を導くのに必要なチャンクが検索されなかった場合、例えば以下のようなアプローチが有効と考えられます。
-
検索キーワードの抽出方法の変更
質問文から回答に必要な情報に関わる検索キーワードを抽出するアルゴリズムを改善すると、必要な情報が検索できるようになるかもしれません。 -
検索アルゴリズムの改善
質問文から抽出した検索キーワードを単純に検索するだけでは、意味が同じでも異なる言い回しの情報は検索できません。
ベクトル検索を導入することで、これらの情報も取得可能になります。
4. 想定回答につながる情報が載ったチャンクが回答生成時にLLMに渡されているチャンクに含まれているか確認する
回答生成時にLLMへ必要な情報が適切に渡されているかを確認します。
必要な情報が渡されていた場合、以下のようなアプローチが有効と考えられます。
-
プロンプト・使用しているLLMの見直し
プロンプトが適切でない場合、LLMが情報を効果的に利用して回答を生成できないことがあります。 また、使用しているLLM自体の言語処理能力が不足しており、渡された情報を効果的に利用できず、適切な回答を生成できていない可能性があります。 -
チャンク長・チャンク数(LLMに対して与える情報量)のチューニング
必要な情報が含まれていても、与える情報量が多すぎると、LLMが必要な情報を適切に利用できない可能性があるため、情報量のチューニングが必要となります。
必要な情報が渡されていなかった場合、以下のアプローチが有効と考えられます。
- 検索後のリランキングの導入
- チャンク数(LLMに対して与える情報量)のチューニング
回答を導くのに必要な情報が検索にひっかかっていても、アルゴリズムによってはLLMに情報が渡らないことがあります。
例えば「検索結果のうち、類似度が上位3件のチャンクをLLMに渡す」というアルゴリズムでは、必要な情報を含むチャンクが類似度で4位以下の場合、LLMに渡されません。
検索後に渡すチャンクの数や選定基準の改善、およびチューニングが必要です。
改善における注意点
原因解析・改善のプロセスを説明しましたが、いくつか注意点があります。
1. 改善をおこなったあとはすべてのテストケースで再検証をおこなう
例えば特定のテストケースにおいて、想定回答につながる情報が記載されたチャンクがLLMに渡されていたのにも関わらずうまく回答が生成されなかったとします。
そこで、該当のテストケースで適切な回答を得るために、LLMに渡すチャンクの数をチューニングした結果、該当のケースでは改善が見られたものの、他のケースでは想定していた回答が生成されなくなる場合があります。
特定のケースに特化しすぎたチューニングをすると他のケースに影響を及ぼすため、注意が必要です。
2. システム側でどのような改善を取り入れても良い結果が得られない場合はドキュメントを再度見直す
システム側でどのような改善を施しても回答がうまく生成されない場合、本当にそのドキュメントから想定した回答が得られるのか今一度確認しましょう。
ドキュメントの質が結果に大きく影響することに留意する必要があります。
ドキュメント情報を直接LLMに提供し、想定回答が得られるかを確認することで、ドキュメントの妥当性を評価できます。
3. 妥当性の高いテストケースを準備する
評価用テストケースが現実の利用ケースを正確に反映しているか確認することが重要です。特に、RAGを使用する際には特定のビジネス領域やトピックに特化した質問が多い傾向があります。その分野の情報の代表性や多様性を確保し、実際の利用ケースに近いテストケースを準備することが求められます。
4. 精度改善には限界がある
精度には限界があることを認識する必要があります。
RAGシステムは強力なアーキテクチャですが、弱点もあります。例えばRAGは複数に分散された情報から回答を導き出すのは苦手です。この弱点を解決するよう考案されたGraphRAGは複数に分散された情報から回答を導き出すのは得意ですが、汎用的に利用できるアーキテクチャではありません。RAGの適用範囲にも限界があることを認識することが重要です。
おわりに
この記事では、RAGの精度改善業務に従事した経験から得た知見を記載しました。
RAGシステムの精度改善は単なる技術的な改良に留まらず、データの整備、ユーザーの理解、チューニングなど、広範囲な視野での施策が必要です。精度を上げるためには、システムの運用やフィードバックの収集を継続して行い、ユーザー体験の向上に努めることが欠かせません。
このプロセスを繰り返すことで、RAGシステムはより効果的な情報提供が可能となります。
この記事で共有した経験と知見が、同様の課題に直面しているチームや組織にとって、参考となれば幸いです。
記事の執筆にあたっては情報の正確性に努めておりますが、掲載されている文章やソースコード、設定ファイル等の内容について、完全な正確性や安全性を保証するものではありません。活用される際は、必ず公式ドキュメント等をご自身で確認のうえご判断ください。
