

はじめに
私のチームでは、社内データのAI活用促進の一環として、Difyを用いた社内文書RAGの検証を行っています。
DifyはオープンソースのLLMアプリケーション開発プラットフォームで、ノーコードやローコードで操作できる直感的なユーザーインターフェースを持っています。また、豊富なモデルをサポートし、ナレッジ機能も備えているため、RAGシステムの検証には非常に適しています。
まず、ユーザーの入力に基づいてナレッジ検索を行い、LLMが回答を作成するシンプルなチャット形式のアプリケーションを用意しました。簡単な想定問答を設けてテストを実施してみたところ、以下の課題が明らかになりました。
- 単語のみの入力や指示語の多用など、ユーザーの入力内容を起因とする回答精度の著しい低下
- 一度の検索では情報が集まりきらず、回答が不完全になる場合がある
これらの課題を解決するためには、柔軟な対応力と検索精度の向上が必要であるとして、以下のアプローチを実施しました。
- エージェントアシスタントによるAgentic RAG化
- ナレッジに親子チャンク分割を採用
この記事では、これらの改善策の意義と実装方法についてご紹介します。
改善された社内文書RAGのフローは、以下の図に示した通りです。
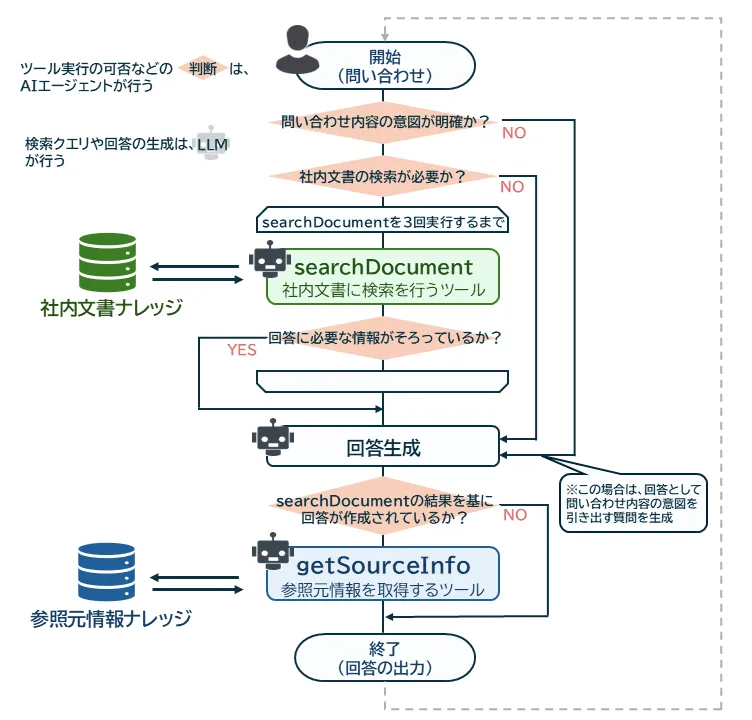
エージェントアシスタントでAgentic RAG化
Agentic RAGとは
Agentic RAGとは、RAGパイプラインにAIエージェントを組み込むことにより、動的な意思決定、反復的な推論を実現する手法です。
AIエージェントの役割や各ツールの使用用途を記述しておくことで、ある程度思考の方向性をコントロールすることが可能です。
タスクを遂行する際は、AIエージェントが自律的に必要なツール(呼び出すことができるコンポーネント化された機能)を判断し選択することで、ワークフローの最適化や複雑な問題解決を支援します。
また、Agentic RAGには多様なアーキテクチャがあるため、用途に応じて適切なものを選ぶ必要があります。
今回は、単一のエージェントが全体のプロセスを管理するSingle-Agent RAGを採用しました。
この構成は、並列処理や拡張にはある程度の限界がありますが、一元化によって設計・実装・保守が容易なので、利用するツールやデータソースの種類が限られており、プロセスが明確なタスクに向いています。
社内文書RAGは検索対象が限られており、必要な処理工程も明確になっているため、Single-Agent RAGが適していると判断しました。
参考
- What is Agentic RAG ⧉
- Rethinking the Bounds of LLM Reasoning:Are Multi-Agent Discussions the Key? ⧉
- Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG ⧉
Difyのエージェントアシスタント
採用する構成が決まったので、Difyを使ってAgentic RAGを実装する方法を検討します。
Difyでは、選択可能なアプリケーションタイプの1つとして「エージェント」が用意されています。これによって作成したエージェントアシスタントでは、事前に登録したツールをタスクの状態に応じて呼び出すことで、動的にフローを構築します。
用意したツール
エージェントアシスタントが呼び出すツールには、外部のAPIだけでなく、Dify上で自作したワークフローも登録できます。
ワークフローでは、編集フィールド上でノード(実行可能な処理をコンポーネント化した要素)をドラッグ&ドロップして繋げることでフローを構築します。
今回は以下の2つのワークフローを用意し、ツールとしてエージェントと連携させました。
1. 社内文書を検索するツール "searchDocument"
渡された検索クエリを使用し、社内文書ナレッジに対してベクトル検索を行い、関連性の高いテキスト情報を返すツールです。
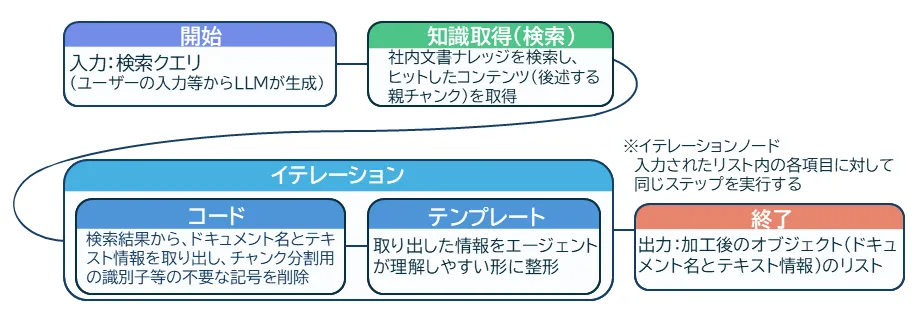
ナレッジに関しては、後述する親子チャンク分割を採用したことで、多くの情報をLLMに渡すことができるようになりました。しかし、その分消費トークンの数が大幅に増加してしまったため、コードノードを利用して検索結果を加工し、トークンの消費を抑えています。
2. 参照元情報を取得するツール "getSourceInfo"
回答作成に使用した社内文書の名前から、参照元のリンク情報を返すツールです。
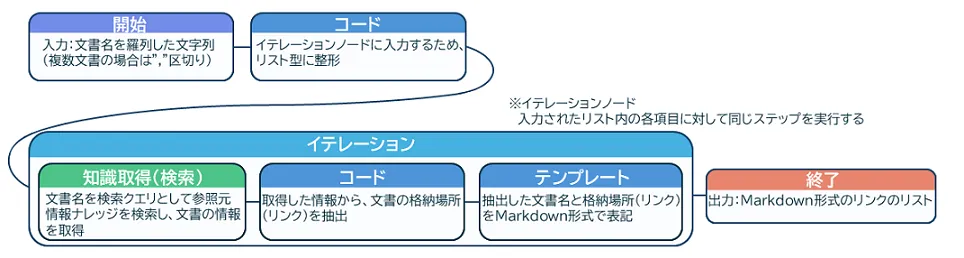
参照元情報は、検索対象の社内文書ナレッジとは別のナレッジに格納しています。
エージェントアシスタントのプロンプト
エージェントアシスタントによるフロー構築に一番影響を及ぼすシステムプロンプトについては、オープンソースのエージェント型開発支援ツールであるCline ⧉を参考に、以下のような構成にまとめました。
- エージェントアシスタントの役割
- ツールの定義
- 問い合わせに対する対応手順
エージェントアシスタントの役割
最初に、エージェントアシスタントがどのような能力を持っていて、どのような役割として動いてほしいかを記述します。能力を発揮すべき領域を明確に示しておくことで、思考の方向性をコントロールすることが可能になります。
今回は以下のように記述しました。
エージェントアシスタントの役割についてのプロンプト
あなたはIT企業「株式会社アルファシステムズ」の社内文書に精通し、あらゆる社内情報を網羅的に理解している文書管理者です。社員の問い合わせに対し、回答を作成してください。ツールの定義
ここでは、エージェントアシスタントが使用できるツールの定義、使い方、使用ガイドラインを記述しています。 状況に応じたツールの使い方などは、次の「問い合わせに対する対応手順」にて記述しますが、ツール実行時の注意事項については、定義とまとめて記載する方が指示への忠実さが増す印象を受けました。
ツールの定義についてのプロンプト
## searchDocument
回答作成に社内文書の検索が必要な場合に使用します。
– 社内文書の検索が必要だと判断した場合、検索に使用するクエリを作成し、実行してください。
– 1回の問い合わせにつき、3回まで実行できます。
– 検索の対象は社内の文書です。わざわざ「アルファシステムズ」という単語を使用した説明はほとんどありません。クエリを作成する際に「アルファシステムズでは~」など社名を補うとかえって検索の精度が下がってしまうため、「株式会社アルファシステムズ」という単語を使用する際は「当社」と言い換えてください。
– ツールでは渡されたクエリを基に、社内文書を登録してあるナレッジベースに対して、ベクトル検索を行います。そのため、作成するクエリは単語の羅列ではなく、自然言語を用いた文章であることが望ましいです。
– 検索の精度を向上させるため、クエリを作成する際は、必ず1つの事柄を検索するように作成してください。
– 「明日、東京で晴れている地域の最高気温は?」のような質問はせずに、「明日、東京で晴れている地域は?」と(晴れている地域の検索結果を基に)「○○区の最高気温は?」のように、複数の質問に分けてツールを実行するようにしてください。問い合わせに対する対応手順
タスクに記載する対応手順を長く丁寧に記述してみたところ、細かい注意事項が見落とされることが多くなってしまいました。そこで、基本的な手順を簡潔な3つのステップにまとめ、各ステップに詳細な指示を記述したところ、意図通りに動くようになりました。
基本的な手順のプロンプト
# 問い合わせに対する対応手順
以下のステップに沿って回答を作成してください。回答作成までの思考の過程は出力せずに、これから何をするかについてのみ「ですます調」で出力してください。
1. ## ツール実行の判定 の手順に従って回答の作成にツールの実行が必要かどうかを判定してください。2. ## 社内文書の検索 の手順に従って回答の作成に必要な情報を取得してください。3. ## 回答の作成 の手順に従って回答を作成してください。「ツール実行の判定」ステップでは、質問の意図が分からない場合、質問者から必要な情報を引き出すための質問を返すように指示しています。
「ツール実行の判定」ステップのプロンプト
## ツール実行の判定
1. 問い合わせの内容と会話履歴を参考に、回答の作成にツールの実行が必要かどうかを判定してください。 - 問い合わせ内容の意図が分からない場合は、必要な情報を引き出すため、明確で簡潔な質問を返すようにしてください。 - 直接社内の情報について尋ねていなくても、会社の制度などによって回答が変化する場合は、必ずツールを実行して検索を行ってください。2. ツールの実行が必要だと判断した場合は次のステップへ進んでください。3. ツールの実行が不要だと判断した場合は回答を作成し、残りの手順をスキップしてください。「社内文書の検索」ステップでは、1度の検索で情報が集まらなかった場合、会話履歴や1度目の検索結果を踏まえて、再度別の検索クエリで情報を集めるように指示しています。
このように、エージェントアシスタントが回答生成に必要な情報が十分に揃っているかを自律的に判断することで、「柔軟な対応力」と「複数回検索」が実現しました。
「社内文書の検索」ステップのプロンプト
## 社内文書の検索
1. 問い合わせの内容と会話履歴を参考に、回答の作成に足りない情報が何かを考え、searchDocumentで使用する検索クエリを作成してください。 - 検索クエリは、丁寧さよりも簡潔さを優先した短い文章にしてください。2. 作成した検索クエリを用いて searchDocument を実行してください。 - searchDocument 実行後、必要な情報が不足している場合は、検索結果を考慮したうえで、再度検索クエリを作成し searchDocument を実行してください。 - 特に、回答に必要な追加の情報が別の章や表などに記載されている場合は、専用のフォーマット「{ドキュメント名}の{記載場所}の内容を教えて」を使用した検索クエリで searchDocument を実行して情報を取得してください。この形を変更してはいけません。 - searchDocument が合計で3回実行されていた場合は情報がそろっていない状態でも次のステップへ進んでください。3. 回答に必要な情報がそろった場合は次のステップへ進んでください。「回答の作成」ステップでは、検索結果に十分な情報がない場合、ユーザーに追加の情報提供を促すよう指示しています。
そして、参照元情報を取得するgetSourceInfoでは、検索にはヒットしてもLLMの回答生成に利用されなかった文書は、結果から除外するように指示しています。
しかし、この除外対象の制御が難しく、出力結果が安定しませんでした。そこで、プロンプトをいくつかのブロックに分割し、それぞれの冒頭部分に制約を記述することで、意図しない出力の大幅な削減に成功しました。
プロンプト全体に限らず、構造的に分割した1ブロック(##見出しごとのまとまり等)の中であっても、最初と最後に書いてある指示が通りやすいということが分かりました。
「回答の作成」ステップのプロンプト
## 回答の作成
1. 回答の根拠となる document_name のみを使用し、getSourceInfo を実行して参照元情報を箇条書きで出力してください。 – 取得した参照元情報を回答の最後に記載してください。 – 回答の根拠として直接関係のない文書は参照情報を表示してはいけません。2. 検索結果を基に回答を作成してください。 – 回答の作成に必要な情報が取得できなかった場合は、その旨を回答として通知してください。必要に応じて、情報提供を促す質問を返してください。 – 回答は検索結果に忠実に作成してください。一般常識から推測した内容を織り交ぜてはいけません。 – searchDocument で取得した関連情報でも、直接回答の根拠となる情報以外は共有しないでください。3. 作成した回答が社員の問い合わせに対する回答になっているかを自身で確認し、必要に応じて修正してください。 – 特に、以下の2つに注意してください。 – 回答の作成に必要な情報が取得できなかった場合、「関連する情報が見つからなかったこと」を通知していることを確認してください。 – 回答の作成に使用した情報の参照元情報がしっかりと回答に含まれている事を確認してください。また、これらのプロンプトを調整する過程で、動的に処理を変更するエージェント型の場合、状況に応じた分岐の数が増えるにつれて、細かい指示が通りにくくなる傾向があることが分かりました。この場合は、人間が試行錯誤して分岐条件の調整を行うよりも、まず回答を作成させて、その後でLLMに修正させる方が安定した結果が得られるようです。
使用するLLM
当初は、チャット形式でのやり取りがスムーズなGPT-4oを使用する予定でしたが、親子チャンクの採用によってLLMに渡す情報量が増えた結果、会話履歴を参照するためのトークン数が足りなくなってしまいました。
コンテキストウインドウの大きい他のLLMも試してみましたが、実行予定のツール名などの「利用者に見せたくない思考の過程」まで出力することが頻発しました。対策として、「思考の過程は出力せずに作成した回答のみを出力してください。」という一文を追加したのですが、ツールの使用に関する判断が曖昧になったり、ハルシネーションが発生するなど、他の部分で不具合が生じてしまいました。
このように、ステップバイステップで処理を進める場合、その過程の出力を無理に制限させると、回答の精度が著しく低下することがあるようです。折衷案として、次に実行することを簡潔に出力させることで、思考過程を省略しつつ精度を維持することに成功しました。
最終的に、ツールの実行判定や検索クエリの作成といったエージェントとしての判断力において、試したモデルの中で最も優れていたClaude 3.7 Sonnetを採用しました。
ナレッジに親子チャンク分割を採用
チャンクとは
チャンクとは、データや情報を扱いやすくするために小さく分割したものです。これをナレッジで扱うデータの単位とすることで、以下の効果が期待できます。
- 検索対象を小分けに管理することで、情報が埋もれることを防ぎ、検索精度が向上する
- 必要最小限の情報を扱うことで、処理速度の向上と、LLMのトークン数消費の抑制が期待できる
親子チャンクとは
今回は、2025年1月のアップデートでDifyに搭載された親子チャンクの機能を使いました。
これは、「子チャンク(Child-chunk)」と「親チャンク(Parent-chunk)」というサイズの異なるデータを階層構造で管理し、使い分けることで、より詳細なマッチングと豊富な情報の提供を可能にするものです。
- 子チャンク:検索に用いられるチャンク。焦点を絞って小さく分割されているため、ユーザーのクエリにマッチングする際の精度が高い。
- 親チャンク:LLMに渡されるチャンク。子チャンクを含む、段落やセクション、文書全体など、より大きな塊で構成されているため、多くの情報を含む。
通常のチャンクを使用する場合は、検索にヒットしたチャンクそのものをLLMに渡します。一方で親子チャンクの場合は、子チャンクを含む親チャンクをLLMに渡します。
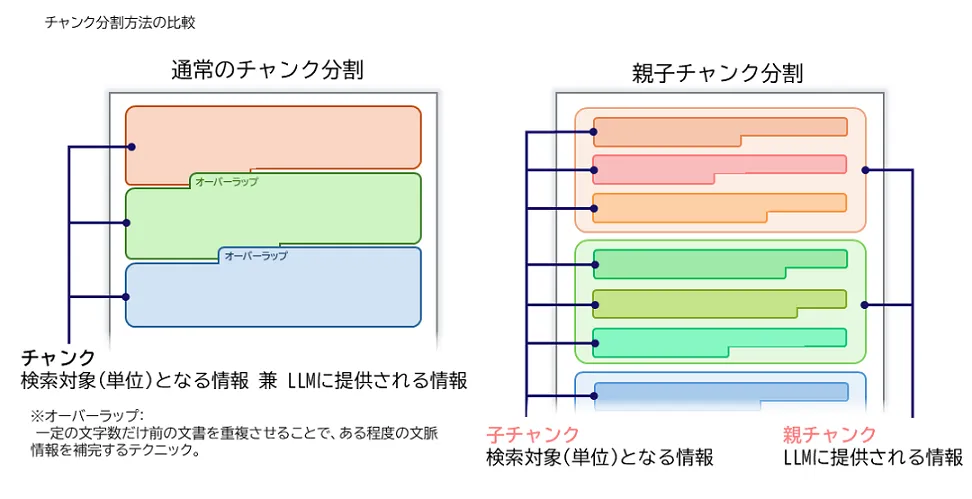
このように、子チャンクを利用することで検索精度を確保しつつ、親チャンクによって広範囲の情報を扱うことが可能になります。
親子チャンク分割の実装
今回は、ナレッジ登録対象の文書ファイル(PDF形式)にテキスト抽出・加工を行い、DifyのAPIを使用してナレッジに登録するスクリプトを作成しました。処理の流れは以下の通りです。
- 文書ファイルのテキストを抽出し、Markdown形式に変換する
- テキストにチャンク分割用の識別子を挿入し、表(テーブル)を加工する
- 加工済みのテキストをtxtファイルとして出力する
- APIでナレッジに登録する
文書ファイルのテキストを抽出し、Markdown形式に変換する
テキスト情報だけでなく、見出し、箇条書き、表などの構成を保持するため、Markdown形式で構造化しました。
テキスト情報を持つドキュメント
PDFコンテンツをRAGやLLMに活用しやすい形式にして抽出できるPythonライブラリ「PyMuPDF4LLM」を利用し、文書ファイルが持つテキスト情報をMarkdown形式の構造化テキストに変換しました。このライブラリは、マルチカラムや簡単な表も認識することができます。
また、類似のライブラリに「MarkItDown」がありますが、日本語の処理精度があまり良くなかったため、採用には至りませんでした。ただし、さすがはMicrosoft製ということで、Microsoft Officeのドキュメントに対しては高い精度の読み取リが可能です。pptxファイルでは、スライド内に表示されないノート内のテキストもしっかりと認識されていました。
テキスト情報を持たないドキュメント
ライブラリでテキスト情報が認識されなかったドキュメントについては、1ページごとに画像(png)に変換し、それをBase64でエンコードしてLLM(GPT-4o)に渡します。そして、画像から抽出したテキストをMarkdown形式で構造化しながら書き起こさせることで対応しました。
使用したプロンプトは、以下の通りです。
テキスト情報を持たないドキュメント用プロンプト
あななたは文字起こしサービスの一部として稼働しています。画像に書かれている内容を、ありのままに書き起こしてください。必ず以下の「#ルール」に従い、適切な処理を行ってください。#ルール* 出力する際、画像に書かれている内容に対し、削除や省略、要約、補足、追記は一切行わないでください。* 途中で切断されたと思われる文や、一般的でない単語があったとしても、修正を行わす、そのまま書き起こしてください。* 見出しや箇条書きは、markdown形式で出力してください。ただしmarkdownのコードブロックで囲む必要はありません。* 画像の内容の文頭が、前ページの文末と繋がっている場合は、見出しを付けずに書き起こしてください。上記プロンプトの1,2行目を明記するまでは、続く文章を予測するというLLMの仕様のせいか、原文通りのテキスト出力が安定的に行えず、ハルシネーションが起きていました。プロンプトエンジニアリングの基本ですが、期待される役割の提示が出力に与える影響の大きさを再確認させられました。
また、1ページごとに画像へ変換する都合上、ページをまたぐことで途中で切れてしまう文章があり、LLMがその文章を補完しようとハルシネーションを起こすことがありました。この問題については、前ページのテキストも一緒にLLMへ渡して文章を補完することで対処しました。
テキストにチャンク分割用の識別子を挿入し、表(テーブル)を加工する
Difyでは、ドキュメントをアップロードする際に設定した識別子と最大チャンク長に基づいて、チャンク分割が行われます。今回は親子チャンクの分割を行うため、親と子の2種類の識別子を使いました。
また、このテキスト加工と合わせて、表(テーブル)の表記方法をMarkdown形式から、項目と値の関係性を明確にあらわせるJSON形式に変更しました。
この加工に使用したプロンプトは、以下の通りです。
テキストと表(テーブル)の加工用プロンプト
提示された日本語の文章をRAGシステムの検索対象として登録するために、`@@SEPARATOR@@` もしくは `=====` の位置でチャンク分割を行います。必ず「#ルール1」に従って適切な処理を行った後に、「#ルール2」に従い適切な処理を行ってください。* 出力する際、提示された文章に対し、削除や省略、要約、補足、追記は一切行わないでください。* 処理された文章以外は出力しないで下さい。まずは以下の「#ルール1」に従い適切な処理を行ってください。
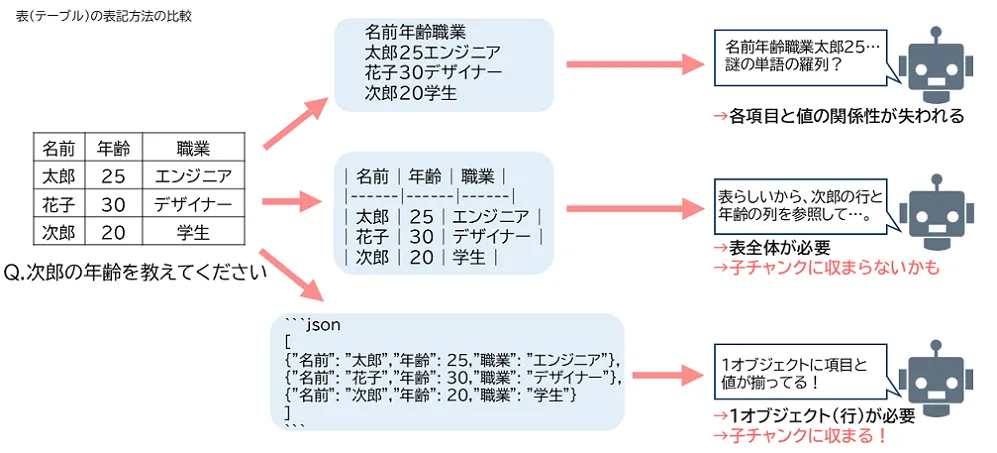
#ルール1* 表が存在する場合は、それに対応するJSON形式に変更してください。そして変更前の表は必ず削除し、JSON形式に差し替えてください。JSON形式への変換例です。変換前| 名前 | 年齢 | 職業 ||------|------|------|| 太郎 | 25 | エンジニア || 花子 | 30 | デザイナー || 次郎 | 20 | 学生 |
変換後[ {"名前": "太郎","年齢": 25,"職業": "エンジニア"}, ===== {"名前": "花子","年齢": 30,"職業": "デザイナー"}, ===== {"名前": "次郎","年齢": 20,"職業": "学生"}]
* `##` 見出しは太文字に変えてください* `###`、`####` 見出しは通常の文字に変換してください* 「第1章」や「第1節」、「付則」など、複数の段落のまとまりが明示的に切り替わる所に `@@SEPARATOR@@` を挿入してください。該当する箇所がなければ、この工程は行わないで下さい。* 独立した段落の間を1行空け、そこに `=====` を挿入してください。* 箇条書きの各項目の次の行に、`=====` を挿入してください。既に挿入されている場合は不要です。以下は、分割例です。
---
**(2-8)高い倫理観に基づくテクノロジーの推進**① 人工知能(AI)をはじめとする新しいテクノロジーを使用する場合は、以下の点を遵守すること。- 人権の尊重、自然への配慮のもとでデータ保護・管理に責任を持ち、適正に利用すること- アルゴリズムやデータのバイアスから生じる不当な差別等のネガティブな影響の多寡を確認し、適切に対処すること=====- 可能な限り、AI 判断の結果が出力されるに至った判断根拠の提示に努めること- AI 等の学習に使用するデータは、適切な手段で得られたデータであることを保証することAI をはじめとする新しいテクノロジーの利用にあたっては、人と自然の共生が重要です。高い倫理観のもとで、これらのテクノロジーを研究開発し、利活用・社会実装することを追求していく必要があります。@@SEPARATOR@@**3. 安全衛生**
企業は、関連法規制を守るのみならず、ISO 45001(労働安全衛生マネジメントシステム)やILO 労働安全衛生マネジメントシステムに関するガイドライン等に留意し、労働者の業務に伴う怪我や心身の病気を最小限に抑え、安全で衛生的な作業環境を整える取り組みを行う必要があります。安全で衛生的な作業環境が、業務上の怪我や病気の発生を最小限に抑えることに加えて、製品およびサービスの品質、製造の一貫性、ならびに労働者の定着率および勤労意欲の向上に繋がります。また、企業が職場での安全衛生の問題を特定および解決するために、労働者の意見聴取と教育は不可欠です。=====
**(3-1)労働安全**① 所在国の労働安全法令を遵守するとともに、職務上の安全に対するリスクを特定・評価し、また適切な設計や技術・管理手段をもって労働者の安全を確保すること。特に、妊娠中の女性および授乳期間中の母親への合理的な便宜を図ること。② 健康および職場環境の安全衛生に関するトレーニングを提供すること。③ 安全のための啓発活動(個人保護具の取扱いを含む)を行うこと。職務上の安全に対するリスクとは、電気その他のエネルギー、火気、乗物・移動物、滑りやすい・つまずき易い床面、落下物等による、労働中に発生する事故や健康障害の潜在的なリスクを指します。=====---
上記の「#ルール1」の処理が完了した後に、以下の「#ルール2」に従い適切な処理を行ってください。
#ルール2* `@@SEPARATOR@@`の前後の文字数が2000文字以下の場合は、その`@@SEPARATOR@@`を削除してください。* `=====`の前後の文字数が200文字以下の場合は、その`=====`を削除してください。"""適切な子チャンクのサイズについて
上記のプロンプト最後に記載した通り、子チャンク(=====区切り)は約200文字程度になるように調節しています。当初は句点で区切られている独立した一文(約100文字以下)ごとに分割していましたが、検索テストを行った結果、精度が悪くなっていました。
基本的に、チャンクサイズは小さい方が検索の精度が上がるといわれています。ですが、今回登録した社内文書の規則類には、簡潔で短い文章や箇条書きが多く含まれていたため、一文ごとの分割ではベクトル化した際の意味情報が単純化されすぎてしまい、検索精度が低下してしまったようです。そこで、子チャンクあたりの最大文字数を引き上げてみたところ、問題なく検索結果にヒットするようになりました。
表(テーブル)の表記方法
表からテキストを抽出しただけでは、単語や文がただ並んでいるだけの情報となるため、各項目と値の関係性が失われてしまいます。したがって、表や箇条書きはMarkdown/CSV/JSONなどに変換することで、構造化された情報として認識させることが推奨されます。
今回は、チャンクサイズを小さく分割する都合上、1行(1オブジェクト)で項目と値の関係が表せるJSON形式で表記しました。
加工済みのテキストをtxtファイルとして出力する
Difyでは、MarkdownやHTMLなど特定のファイルをアップロードすると、自動で文書の構造に基づいたチャンクに分割されてしまいます。
今回は明示的にチャンクの分割箇所を指定したいため、テキスト部分はMarkdown形式ですが、拡張子をtxtとすることで意図しない分割を避けました。
APIでナレッジに登録する
Difyでは、ナレッジやドキュメントを管理するためのAPIが用意されています。今回は、以下のコードを用いてファイルアップロード時にチャンク分割のルール(識別子や最大チャンク長など)を指定し、ナレッジへの登録を行いました。
ナレッジ登録用スクリプト
# Difyナレッジ登録APIdef postFile(txtPath): url = f'{dify_endpoint}/datasets/{dataset_id}/document/create-by-file'# dataset_idは、登録先ナレッジを開くことで確認可能(`https://~~/datasets/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX/documents`) headers = { 'Authorization': f'Bearer {knowledge_api_key}' } data = { 'data': json.dumps({ 'indexing_technique': 'high_quality', 'doc_form': 'hierarchical_model', # 階層(親子)モデルを指定 'process_rule': { 'rules': { 'pre_processing_rules': [ {'id': 'remove_extra_spaces', 'enabled': True}, # 連続するスペース、改行、タブを置換するか {'id': 'remove_urls_emails', 'enabled': False} # URLとメールアドレスを削除するか ], 'segmentation': { 'separator': '@@SEPARATOR@@', # 親チャンク識別子 'max_tokens': 4000 # 親チャンクの最大チャンク長 }, 'parent_mode': 'paragraph', 'subchunk_segmentation': { 'separator': '=====', # 子チャンク識別子 'max_tokens': 300 # 子チャンクの最大チャンク長 }, }, 'mode': 'hierarchical' } }) } with open(txtPath, 'rb') as file: files = { 'file': file } # POSTリクエストの送信 requests.post(url, headers=headers, data=data, files=files)登録後にナレッジにアクセスすることで、実際にどのように分割されたかを確認できます。
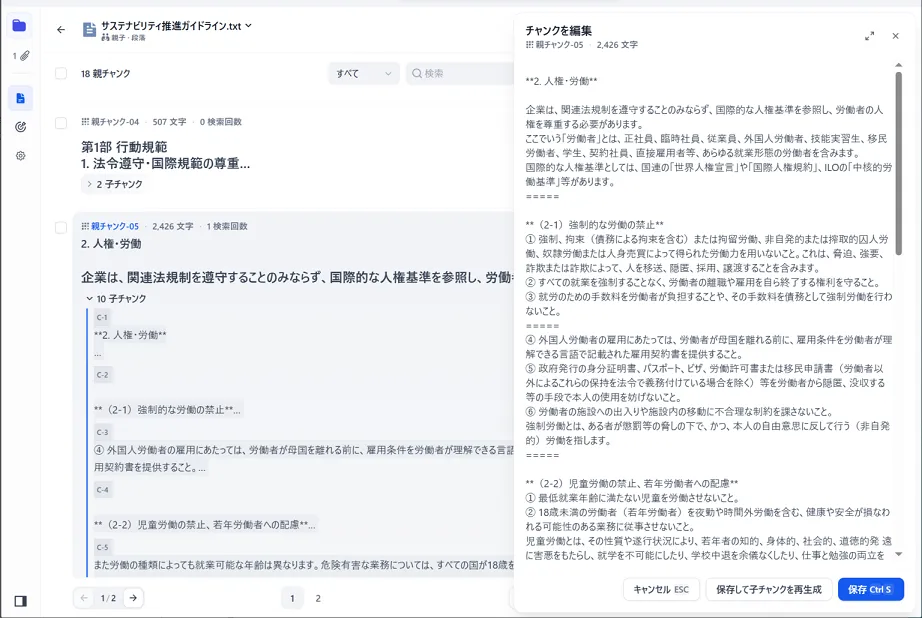
親子チャンク分割を行った社内文書を登録したところで、想定問答を用いて検索から回答生成まで実行してみました。その結果、ヒットした子チャンクの周辺に記載されている具体例や例外時の対処法を含んだ親チャンクがLLMに渡されることで、ユーザーに寄り添った回答を得られることが確認できました。
さいごに
この記事では、Difyを用いてAgentic RAGと親子チャンク分割を採用した社内文書RAGの検証から得られた知見をご紹介しました。
AIエージェントは多機能ゆえに一見難しそうな印象を受けますが、Difyのエージェントアシスタントは簡単な設定で動作するため、入門として非常に適していると感じました。 また、実際に親子チャンクを実装してみることで、チャンク分割がRAG性能に与える影響の大きさや、最適なチャンクサイズを確かめることができました。
RAGの精度向上については、今後も新しい技術やアーキテクチャ、概念が次々に登場すると思われます。 さらに今後は、単なる文書検索にとどまらず、様々なクラウドサービス・企業の情報システム・アプリケーション・データなどをシームレスにつなげ、物理世界をも対象にした高度なアウトプットが可能になることが予想されます。
今回はエージェントアシスタントが利用するツールもDify上で作成しましたが、現時点でもAIエージェントの可能性を大きく広げるMCP(Model Context Protocol)やA2A(Agent2Agent)に対応したアプリケーションが次々と登場しています。
それらを実装、活用するにあたり、手軽に検証が行えるDifyは非常に有用なプラットフォームですので、興味のある方はぜひ触ってみてください。
記事の執筆にあたっては情報の正確性に努めておりますが、掲載されている文章やソースコード、設定ファイル等の内容について、完全な正確性や安全性を保証するものではありません。活用される際は、必ず公式ドキュメント等をご自身で確認のうえご判断ください。
