

目次
はじめに
業務でAWSのAI関連サービスを扱う機会が増えてきました。 そこで、理解を深めることを目的に個人のAWSアカウントで実際に手を動かしてみることにしました。
今回は、Amazon Bedrockを使って、Alexaと会話できるスキルを作成します。
対象読者
- AWSを使った生成AIサービスに興味がある方
- Alexaスキルを自作してみたい方
- 音声UIとAIを組み合わせたアプリケーションを試したい方
前提条件
- AWSアカウントを保有していること
- LambdaやIAMの基本操作に慣れていること(初心者でも手順通りで実装可能)
Alexaスキルとは
Alexaスキルは、Amazon Echoなどのスマートスピーカーに追加できる機能(アプリ)のことです。Amazonが公式で提供しているスキルの他に、開発者が自作したスキルを使うこともできます。
スキルには大きく分けて2種類あります。
- 公開スキル: スキルストアで誰でも利用できるスキル(審査あり)
- 開発中スキル: 開発者のみ利用できるスキル(審査なし)
今回は個人用のスキルを作るため、開発中スキルとして作成します。
今回作るもの
「Claudeトーク」という名前のAlexaスキルを作成します。
- Echoデバイスに「アレクサ、クロードトークを開いて」と呼びかけるとスキルが起動
- 自由に話しかけるとAIが応答を生成して音声で返答
- 会話履歴を保持し、文脈を踏まえた応答が可能
- 月間コストの上限を設定し、超過時は起動をブロック
スキルの使い方
| 呼びかけ | 動作 |
|---|---|
| 「アレクサ、クロードトークを開いて」 | スキル起動 |
| 「AWSとは何ですか」など自由に話しかける | AIが応答 |
| 「ストップ」「終了」 | スキル終了 |
スキル起動後は何を話しかけてもAIが応答します。会話は続けて行え、文脈を覚えています。
会話の終了について: 「ストップ」「終了」と言うか、一定時間(約8秒)無言でいるとスキルが終了します。スキルが終了すると会話履歴はリセットされ、次回起動時は新しい会話として始まります。
構成図
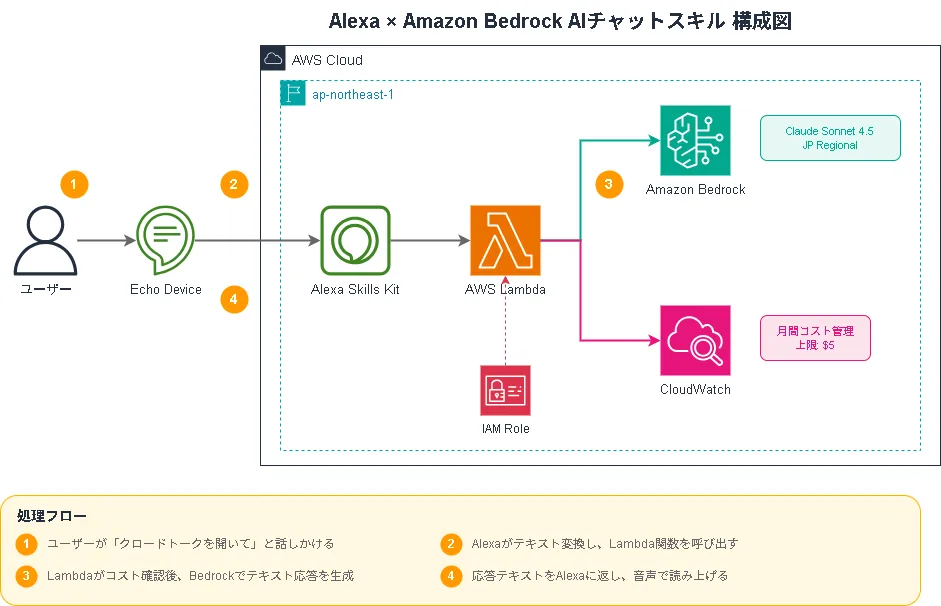
使用するAWSサービス
| サービス | 概要 |
|---|---|
| Amazon Bedrock | 各社の生成AIモデルをAPI経由で利用できるサービス。今回はAnthropicのClaudeを使用 |
| AWS Lambda | サーバーレスでプログラムを実行できるサービス。Alexaからのリクエストを処理 |
| Amazon CloudWatch | AWSリソースの状態やログを収集するサービス。トークン使用量の取得に使用 |
| IAM | AWSリソースへのアクセス権限を管理するサービス |
モデル選定
今回はClaude Sonnet 4.5を使用します。
コストと性能のバランスが良く、会話用途には十分な性能があります。業務でもBedrockのClaudeを使用しており、使い慣れているモデルということも選定理由の一つです。
JP Cross-Region Inference(日本国内クロスリージョン推論)
Amazon BedrockではJP Cross-Region Inference(日本国内クロスリージョン推論)を利用できます。
JP Cross-Region Inferenceとは
推論リクエストが東京(ap-northeast-1)と大阪(ap-northeast-3)リージョン間で自動的にルーティングされる機能です。一方のリージョンが混雑している場合、もう一方に振り分けられることで、安定した応答が期待できます。
なぜJP Cross-Region Inferenceを使うのか
Claude Sonnet 4.5 / Haiku 4.5は、日本では推論プロファイル(jp.*)経由でのみ利用可能です。東京リージョン単体での直接呼び出し(anthropic.claude-sonnet-4-5-*)はサポートされていません。そのため、これらのモデルを日本で使う場合は必然的にJP Cross-Region Inferenceを使用することになります。
グローバル推論プロファイルを使わない理由
Bedrockには、世界中のリージョンにルーティングできるグローバル推論プロファイルもあります。しかし今回は以下の理由でJP Cross-Region Inferenceを選択しました。
- レイテンシー: 日本国内で処理が完結するため、海外リージョンへの通信が不要で応答が速い
- データの所在地: 推論リクエストが日本国外に送信されない
特に企業でAWSを使う場合、コンプライアンスやデータ主権の観点から「データを国内に保管する」要件があるケースも多いようです。JP Cross-Region Inferenceは、このような要件を満たしつつ高可用性を実現できます。
今回はモデルIDにjp.anthropic.claude-sonnet-4-5-20250929-v1:0を指定します。
コストと応答時間
コスト: 1回の会話あたり約0.5〜1円程度。100回会話しても$0.50(約75円)程度で収まります。※AWS Lambdaは月100万リクエストまで無料枠があるため、個人利用では実質Bedrock料金のみです。
※ 会話が長くなると履歴を含めてAPIに送信するため、トークン消費量が増加します。短い会話を多数行う場合の目安です。
応答時間: 質問から回答まで5〜7秒程度。主にBedrockの推論処理に時間がかかります。精度より速度を重視する場合は、Claude Haiku 4.5を使用したり、システムプロンプトで回答文字数を制限(例:「50文字以内で回答」)すると改善できます。
事前準備:Bedrockモデルの有効化
Lambda関数を作成する前に、BedrockでClaudeモデルを有効化しておきます。
モデルの有効化手順
2024年後半以降、Bedrockの「モデルアクセス」ページが廃止され、モデル有効化の手順が変更されました。現在は以下の手順で有効化します。
- AWSマネジメントコンソールでAmazon Bedrockを開く
- 左のナビゲーションペインから「プレイグラウンド」→「チャット/テキストのプレイグラウンド」を選択
- 「モデルを選択」ボタンをクリック
- カテゴリ「Anthropic」、モデル「Claude Sonnet 4.5」、推論「JP Anthropic Claude Sonnet 4.5」を選択し、「適用」をクリック
- ユースケースの入力画面が表示されるので、利用目的を入力して提出
- 承認後、プレイグラウンドで1回以上チャットを実行する(何か質問を送信)
個人利用の場合のユースケース入力について: Claudeモデルを使用する際は会社名などの入力が求められますが、個人でも利用可能です。個人利用の場合は、会社名に「個人」「無所属」または個人名を入力し、ユースケースには「個人学習」「技術検証」などと記載すれば使用できます。
AWS Marketplaceサブスクリプションについて
Bedrockの一部モデル(Claudeを含む)はAWS Marketplace経由で提供されており、初回利用時にサブスクリプションが自動作成されます。プレイグラウンドでチャットを実行すると、このサブスクリプション処理が完了します。
プレイグラウンドを使わずにLambdaから直接モデルを呼び出す場合は、IAMロールに以下のAWS Marketplace権限を追加する必要があります。
{ "Effect": "Allow", "Action": [ "aws-marketplace:Subscribe", "aws-marketplace:ViewSubscriptions" ], "Resource": "*"}補足: プレイグラウンドで一度チャットを実行しておけば、サブスクリプションが完了するため上記の権限は不要です。簡単に済ませたい場合はプレイグラウンドでの動作確認をおすすめします。
補足: プレイグラウンドを使わずにユースケースを提出する場合は、
PutUseCaseForModelAccessAPIを使用する方法もあります。
Service Quotasの確認
AlexaスキルでBedrockを頻繁に呼び出す場合、デフォルトのクォータでは制限に達する可能性があります。事前に確認・緩和申請を行うことで、運用中のエラーを防げます。
BedrockのService Quotasで、モデルの呼び出し回数やトークン数の上限を確認できます。
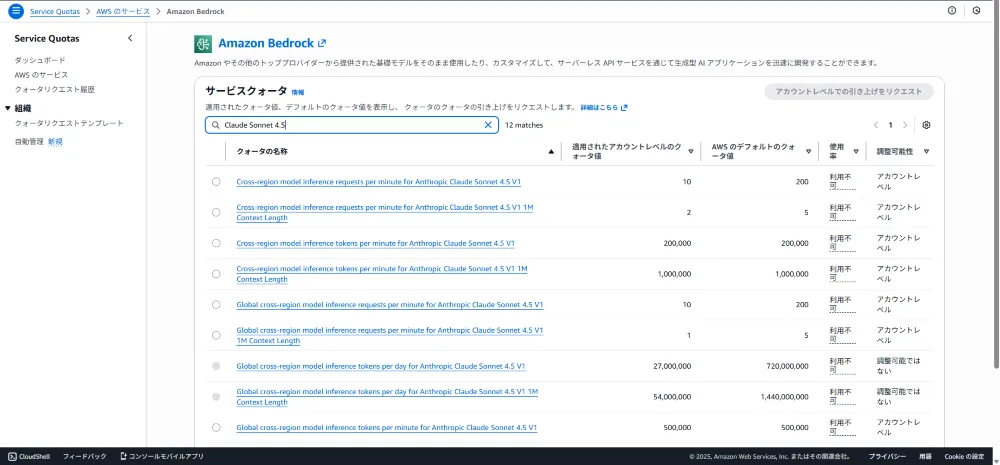
注意: 新規アカウントや利用実績の少ないアカウントでは、デフォルトで低いクォータが設定されていることがあります。(例:1分間に1回のみ呼び出し可能など)
上限緩和の申請方法は以下の通りです。
- Service Quotasコンソールから: 「アカウントレベルでの引き上げをリクエスト」ボタンをクリック
- AWSサポートから: 「アカウントレベルでの引き上げをリクエスト」ボタンがない場合はサポートケースを作成して申請(「アカウントと請求」を選択し、サービスは「Service Quotas」を選択)
実装手順
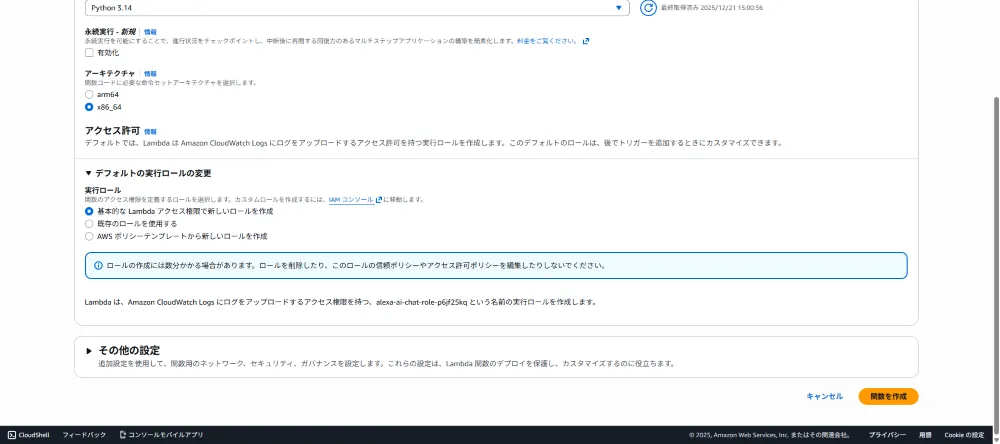
1. Lambda関数の作成
AWSコンソールからLambda関数を作成します。
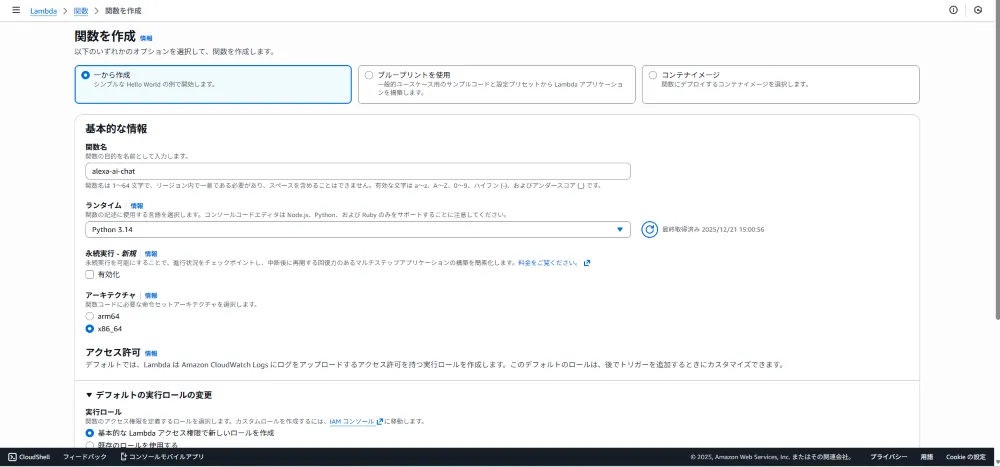
| 項目 | 値 |
|---|---|
| 関数名 | alexa-ai-chat |
| ランタイム | Python 3.14 |
| アーキテクチャ | x86_64 |
| 実行ロール | 基本的なLambdaアクセス権限で新しいロールを作成 |
2. Lambda関数の基本設定
Bedrockの呼び出しには数秒かかるため、タイムアウトを30秒に変更します。
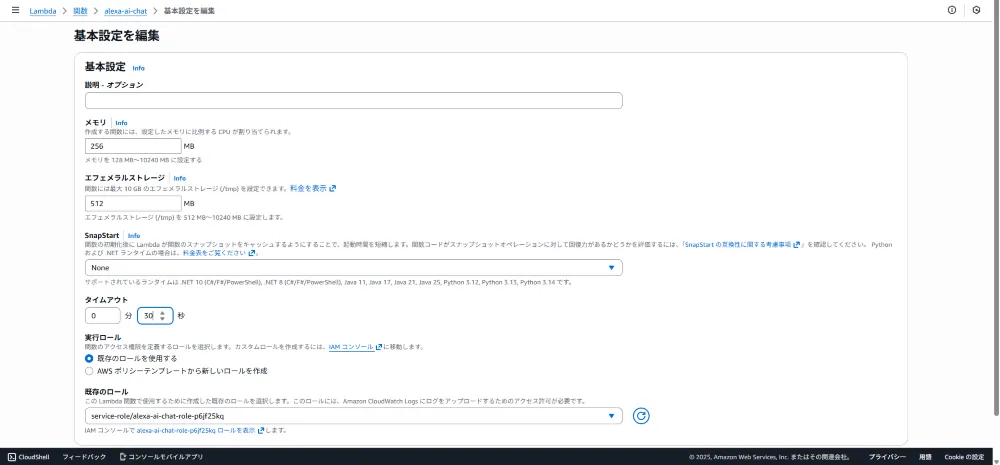
| 項目 | 値 |
|---|---|
| メモリ | 256 MB |
| タイムアウト | 30秒 |
3. IAMポリシーの追加
Lambda関数の実行ロールには、デフォルトでCloudWatch Logsへの書き込み権限が付与されています。これに加えて、BedrockとCloudWatchメトリクスの権限を追加します。
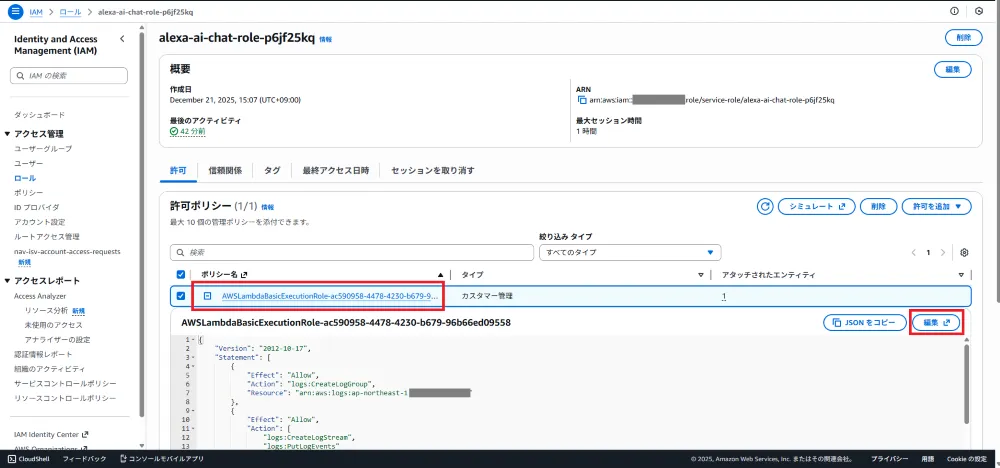
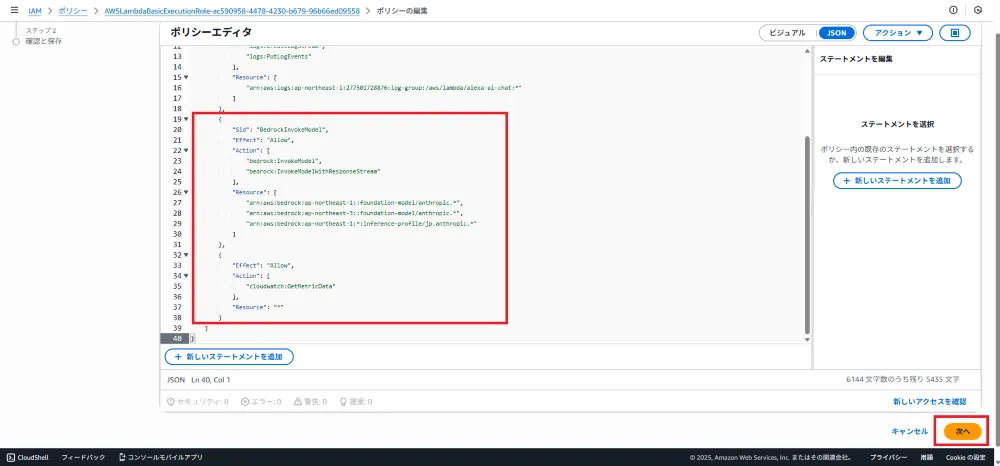
Bedrock呼び出し権限
JP Cross-Region Inferenceを使用するため、推論プロファイルと東京・大阪両リージョンの基盤モデルへのアクセス権限が必要です。
{ "Sid": "BedrockCrossRegionInference", "Effect": "Allow", "Action": [ "bedrock:InvokeModel", "bedrock:InvokeModelWithResponseStream" ], "Resource": [ "arn:aws:bedrock:ap-northeast-1:*:inference-profile/jp.anthropic.*", "arn:aws:bedrock:ap-northeast-1::foundation-model/anthropic.*", "arn:aws:bedrock:ap-northeast-3::foundation-model/anthropic.*" ]}CloudWatchメトリクス取得権限(コスト管理用)
{ "Effect": "Allow", "Action": [ "cloudwatch:GetMetricData" ], "Resource": "*"}4. Lambda関数のコード
主な機能は以下の通りです。
- 会話履歴の保持: 同一セッション内で直近30往復まで保持し、文脈を踏まえた応答が可能(スキル終了で履歴はリセット)
- JP Cross-Region Inference対応: 日本国内リージョンで推論を実行
- コストチェック: スキル起動時に月間コストをチェックし、上限超過時はブロック
処理フロー
Alexaスキルでは、ユーザーの操作に応じて異なる種類のリクエストがLambdaに送信されます。
| リクエスト種別 | 発生タイミング |
|---|---|
| LaunchRequest | スキル起動時(「〇〇を開いて」と呼びかけた時) |
| IntentRequest | スキル起動後にユーザーが発話した時 |
| SessionEndedRequest | セッション終了時(タイムアウトなど) |
IntentRequestには「何をしたいか」の情報が含まれており、発話内容に応じてConversationIntent(ユーザーの自由な発話を受け取るカスタムインテント)やAMAZON.StopIntent(スキル終了)などのインテントに振り分けられます。
flowchart TD
A[Alexaからリクエスト] --> B{リクエスト種別}
B -->|LaunchRequest| C[コストチェック]
C --> D{上限超過?}
D -->|Yes| E[利用停止メッセージ]
D -->|No| F[起動メッセージ]
B -->|ConversationIntent| G[ユーザー発話取得]
G --> H[会話履歴に追加]
H --> I[Bedrock呼び出し]
I --> J[AI応答を履歴に追加]
J --> K[音声で応答]
B -->|StopIntent| L[終了メッセージ]
B -->|HelpIntent| M[ヘルプメッセージ]
B -->|FallbackIntent| N[再発話を促すメッセージ]
Lambda関数コード
# lambda_function.py# Alexa × AWS Bedrock Claudeトーク
import jsonimport boto3import loggingimport timefrom datetime import datetime
# ログ設定logger = logging.getLogger()logger.setLevel(logging.INFO)
# Bedrock クライアントbedrock = boto3.client('bedrock-runtime', region_name='ap-northeast-1')
# CloudWatch クライアント(コストチェック用)cloudwatch = boto3.client('cloudwatch')
# モデル設定MODEL_ID = "jp.anthropic.claude-sonnet-4-5-20250929-v1:0"
# コスト設定# 月間利用上限(USD)- この金額に達するとスキルを一時停止COST_LIMIT_USD = 5.00
# AWS Bedrock JP Regional 料金(1トークンあたりの単価)INPUT_TOKEN_PRICE = 0.0033 / 1000 # $0.0033 / 1K tokensOUTPUT_TOKEN_PRICE = 0.0165 / 1000 # $0.0165 / 1K tokens
# システムプロンプトSYSTEM_PROMPT = """あなたはAlexaの音声アシスタントです。
【回答の長さルール】- 雑談・挨拶: 1-2文(50文字程度)- 質問への回答: 3-5文(150文字程度)- 説明・解説を求められた場合: 5-10文(300文字程度)- 「詳しく」「もっと教えて」と言われたら: 長めに回答
【基本ルール】- 音声で聞きやすいよう、箇条書きは避ける- 「〜ですね」「〜ですよ」など話し言葉で- 長くなりそうなら「続きを聞きますか?」と確認"""
def lambda_handler(event, context): """Lambda メインハンドラー""" logger.info(f"Received event: {json.dumps(event, ensure_ascii=False)}")
request_type = event['request']['type']
# スキル起動時(「アレクサ、クロードトークを開いて」) if request_type == 'LaunchRequest': return handle_launch_request(event) # ユーザーが何か話しかけた時 elif request_type == 'IntentRequest': return handle_intent_request(event) # セッション終了時(タイムアウトやエラー) elif request_type == 'SessionEndedRequest': return handle_session_ended_request(event) else: return build_response("すみません、よく分かりませんでした。")
def handle_launch_request(event): """スキル起動時の処理""" # コストチェック(起動時のみ) cost_check = check_monthly_cost()
if cost_check['is_exceeded']: return build_response( f"申し訳ありません。今月の利用上限{COST_LIMIT_USD}ドルに達したため、クロードトークは一時停止中です。現在の利用額は{cost_check['current_cost']:.2f}ドルです。来月またお話しましょう。", should_end_session=True )
speech = "クロードトークを起動しました。何でも話しかけてください。" return build_response(speech, should_end_session=False)
def handle_intent_request(event): """インテント処理""" intent_name = event['request']['intent']['name']
# 会話インテント(ユーザーの発話を処理) if intent_name == 'ConversationIntent': return handle_conversation_intent(event) # ヘルプ(「ヘルプ」「使い方を教えて」) elif intent_name == 'AMAZON.HelpIntent': return handle_help_intent() # 終了(「終了」「ストップ」「キャンセル」) elif intent_name in ['AMAZON.CancelIntent', 'AMAZON.StopIntent']: return handle_stop_intent() # 聞き取れなかった時 elif intent_name == 'AMAZON.FallbackIntent': return handle_fallback_intent() else: return build_response("すみません、よく分かりませんでした。", should_end_session=False)
def handle_conversation_intent(event): """会話インテントの処理""" try: # ユーザー入力を取得 slots = event['request']['intent'].get('slots', {}) user_input = slots.get('UserInput', {}).get('value', '')
if not user_input: return build_response( "すみません、聞き取れませんでした。もう一度話しかけてください。", should_end_session=False )
logger.info(f"User input: {user_input}")
# セッション属性から会話履歴を取得(初回は空) session_attributes = event.get('session', {}).get('attributes', {}) or {} conversation_history = session_attributes.get('history', [])
# 会話履歴にユーザー入力を追加 conversation_history.append({ "role": "user", "content": user_input })
# Bedrockで応答を生成 start_time = time.time() ai_response = get_bedrock_response(conversation_history) elapsed_time = time.time() - start_time logger.info(f"Bedrock response time: {elapsed_time:.2f}s")
# 会話履歴にAI応答を追加 conversation_history.append({ "role": "assistant", "content": ai_response })
# 履歴が長くなりすぎたら古いものを削除(直近30往復まで) if len(conversation_history) > 60: conversation_history = conversation_history[-60:]
# セッション属性を更新 session_attributes['history'] = conversation_history
return build_response( ai_response, should_end_session=False, session_attributes=session_attributes )
except Exception as e: logger.error(f"Error in conversation: {str(e)}", exc_info=True) return build_response( "すみません、エラーが発生しました。もう一度話しかけてください。", should_end_session=False )
def get_bedrock_response(conversation_history): """Bedrockを呼び出してAI応答を取得""" try: response = bedrock.invoke_model( modelId=MODEL_ID, body=json.dumps({ "anthropic_version": "bedrock-2023-05-31", "max_tokens": 500, "system": SYSTEM_PROMPT, "messages": conversation_history }), contentType='application/json' )
# レスポンスからAIの応答テキストを取得 response_body = json.loads(response['body'].read()) ai_response = response_body['content'][0]['text']
logger.info(f"AI response: {ai_response}") return ai_response
except Exception as e: logger.error(f"Bedrock error: {str(e)}", exc_info=True) raise
def handle_help_intent(): """ヘルプインテントの処理""" speech = "クロードトークでは、何でも話しかけることができます。質問したり、雑談したり、自由に会話を楽しんでください。" return build_response(speech, should_end_session=False)
def handle_stop_intent(): """停止インテントの処理""" speech = "クロードトークを終了します。またお話ししましょう。" return build_response(speech, should_end_session=True)
def handle_fallback_intent(): """フォールバックインテントの処理""" speech = "すみません、うまく聞き取れませんでした。もう一度話しかけてください。" return build_response(speech, should_end_session=False)
def handle_session_ended_request(event): """セッション終了時の処理""" logger.info("Session ended") return build_response("", should_end_session=True)
def calculate_cost(input_tokens, output_tokens): """トークン数からコスト(USD)を計算""" input_cost = input_tokens * INPUT_TOKEN_PRICE output_cost = output_tokens * OUTPUT_TOKEN_PRICE return input_cost + output_cost
def check_monthly_cost(): """CloudWatchメトリクスから月間コストを計算""" logger.info(f"Starting cost check. Limit: ${COST_LIMIT_USD}")
try: # 月初から現在までの期間を設定 now = datetime.now() start_of_month = datetime(now.year, now.month, 1)
# トークン数を取得 total_input_tokens = get_metric_sum(MODEL_ID, 'InputTokenCount', start_of_month, now) total_output_tokens = get_metric_sum(MODEL_ID, 'OutputTokenCount', start_of_month, now)
# コスト計算 current_cost = calculate_cost(int(total_input_tokens), int(total_output_tokens)) is_exceeded = current_cost >= COST_LIMIT_USD
logger.info(f"Monthly cost check: ${current_cost:.4f} / ${COST_LIMIT_USD} (Input: {int(total_input_tokens)}, Output: {int(total_output_tokens)})")
if is_exceeded: logger.warning(f"Cost limit exceeded! ${current_cost:.2f} >= ${COST_LIMIT_USD}")
return { 'is_exceeded': is_exceeded, 'current_cost': current_cost, 'limit': COST_LIMIT_USD }
except Exception as e: logger.error(f"Error checking cost: {e}", exc_info=True) # エラー時は安全のため続行を許可 return {'is_exceeded': False, 'current_cost': 0, 'limit': COST_LIMIT_USD}
def get_metric_sum(model_id, metric_name, start_time, end_time): """CloudWatchメトリクスの合計値を取得""" try: response = cloudwatch.get_metric_data( MetricDataQueries=[ { 'Id': 'token_count', 'MetricStat': { 'Metric': { 'Namespace': 'AWS/Bedrock', 'MetricName': metric_name, 'Dimensions': [ {'Name': 'ModelId', 'Value': model_id} ] }, 'Period': 2592000, # 30日 'Stat': 'Sum' } } ], StartTime=start_time, EndTime=end_time )
# 取得した値を合計して返す(データがなければ0) values = response['MetricDataResults'][0].get('Values', []) return sum(values) if values else 0
except Exception as e: logger.warning(f"Failed to get metric {model_id}/{metric_name}: {e}") return 0
def build_response(speech, should_end_session=True, session_attributes=None): """Alexa応答を構築""" response = { "version": "1.0", "response": { "outputSpeech": { "type": "PlainText", "text": speech }, "shouldEndSession": should_end_session } }
if session_attributes: response["sessionAttributes"] = session_attributes
# 会話を続ける場合はリプロンプトを追加(無言時にユーザーの発話を促す音声) if not should_end_session and speech: response["response"]["reprompt"] = { "outputSpeech": { "type": "PlainText", "text": "何か話しかけてください。" } }
return response5. コスト管理について
Bedrockのコストは低めですが、使いすぎ防止のためコスト管理機能を実装しています。
AWS Budgetsを使わない理由: AWS BudgetsのBudget Actions機能では、予算超過時にEC2やRDSを自動停止できますが、Bedrockは対象外です。また、コスト反映までに8〜12時間の遅延があるため、「予算を超えたら即座に制御」という用途には向きません。
そこで、CloudWatchメトリクスからトークン使用量を直接取得し、単価を掛けてコストを計算する方式を採用しました。スキル起動時にリアルタイムでチェックでき、シンプルに実装できます。
なお、コストチェックはスキル起動時(LaunchRequest)のみ実行しています。会話中は毎回チェックしないため、処理負荷を抑えられます。
6. CloudWatchメトリクスの確認
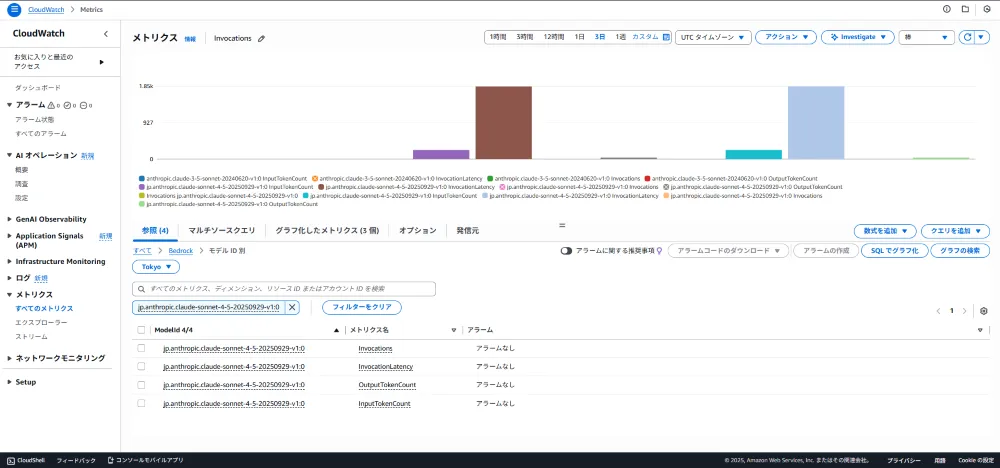
コード内で使用しているInputTokenCountやOutputTokenCountなどのメトリクスは、CloudWatchコンソールの「メトリクス」→「Bedrock」→「モデルID別」で確認できます。
7. Alexaスキルの作成
Alexa Developer Console ⧉でスキルを作成します。Alexa Developer Consoleは、Alexaスキルの作成・管理ができるWebコンソールです。
「スキルの作成」をクリックし、以下の設定で作成します。
Step 1: 名前、ロケール
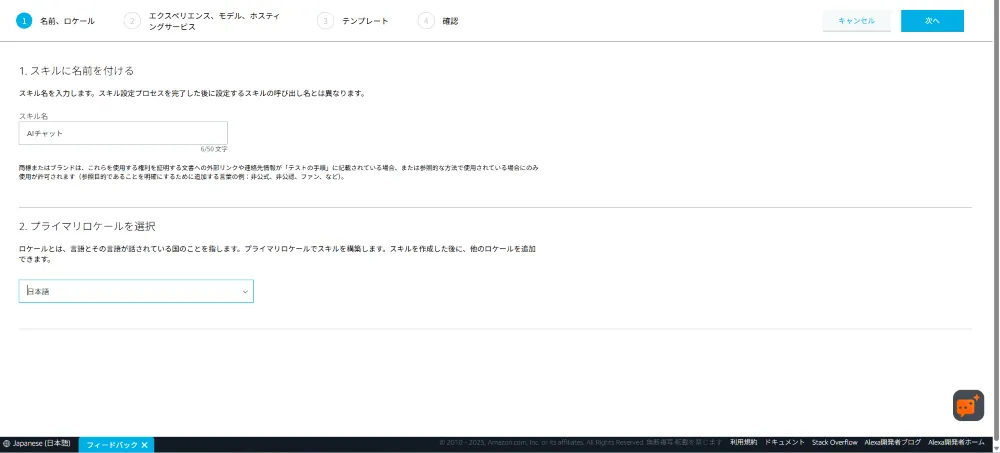
| 項目 | 値 |
|---|---|
| スキル名 | AIチャット |
| プライマリロケール | 日本語 |
Step 2: エクスペリエンス、モデル、ホスティングサービス
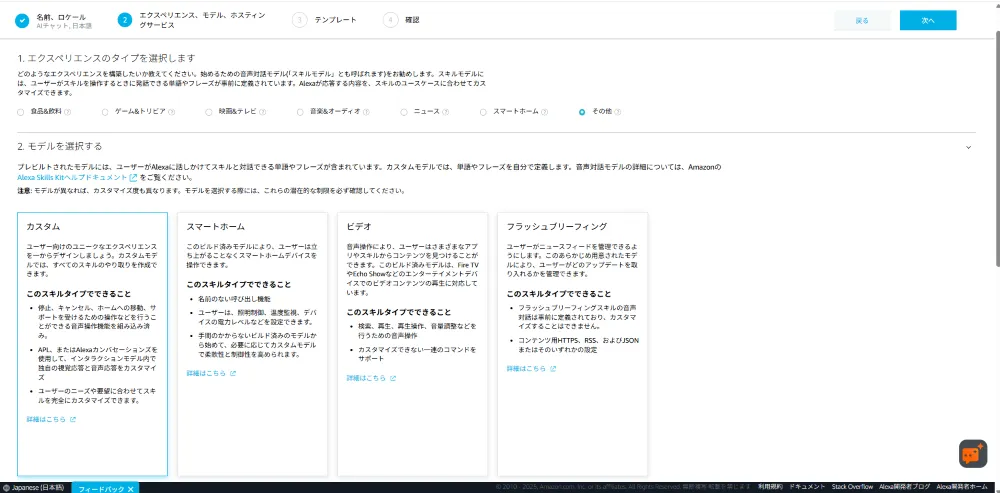
| 項目 | 値 |
|---|---|
| エクスペリエンスのタイプ | その他 |
| モデル | カスタム |
| 項目 | 値 |
|---|---|
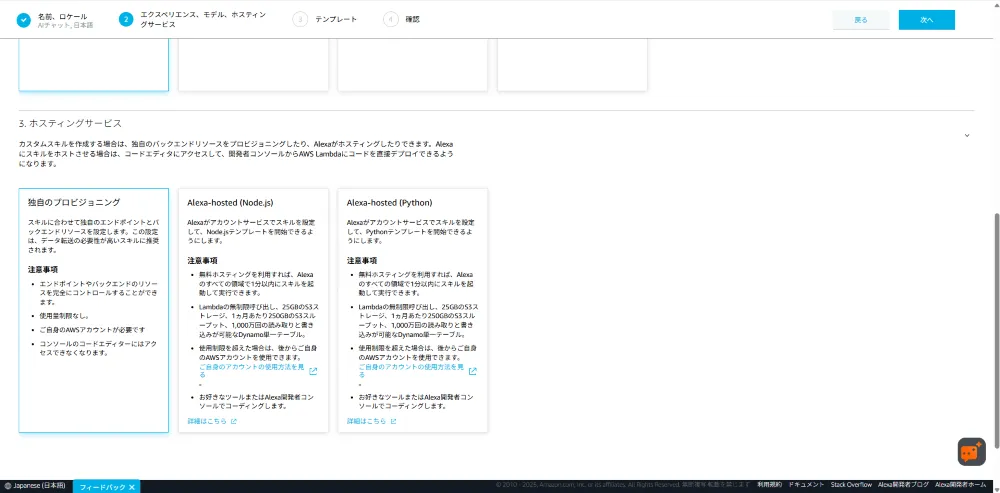
| ホスティングサービス | 独自のプロビジョニング |
個人のAWSアカウントのLambdaを使用するため「独自のプロビジョニング」を選択します。
Step 3: テンプレート
| 項目 | 値 |
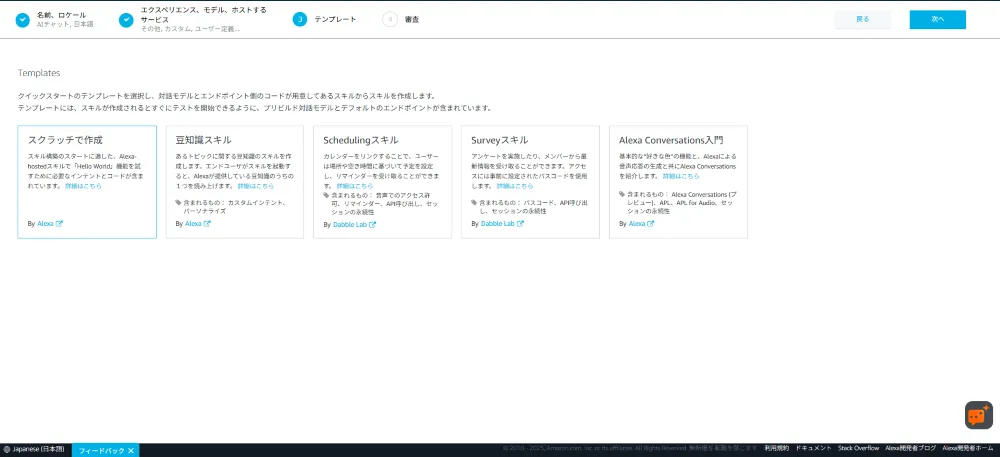
|---|---|
| テンプレート | スクラッチで作成 |
8. Interaction Modelの設定
スキルの対話モデルを設定します。
呼び出し名の設定
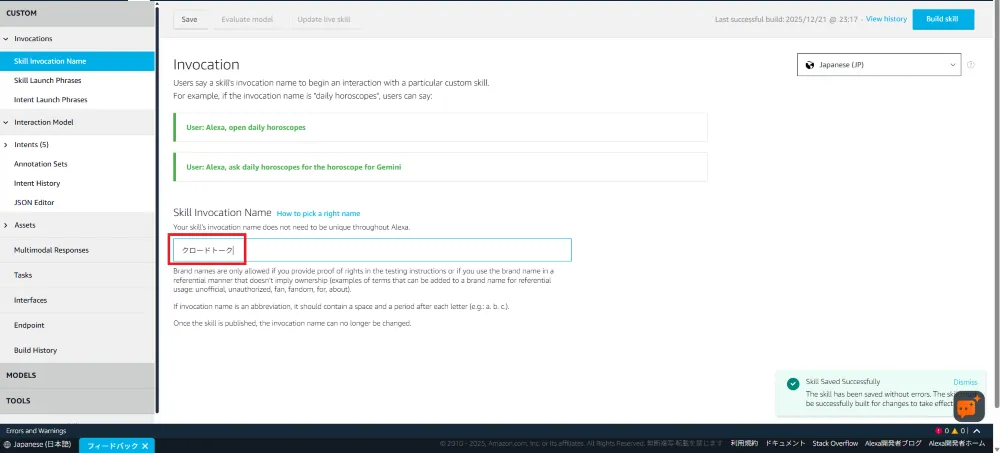
呼び出し名を「クロードトーク」に設定します。「アレクサ、クロードトークを開いて」で起動できます。
補足: 最初は「AIチャット」にしていましたが、発音が似ている曲名があるようでSpotifyが起動してしまうことがありました。そのため、固有名詞的な呼び出し名にすることで解決しました。
JSON Editorでの設定
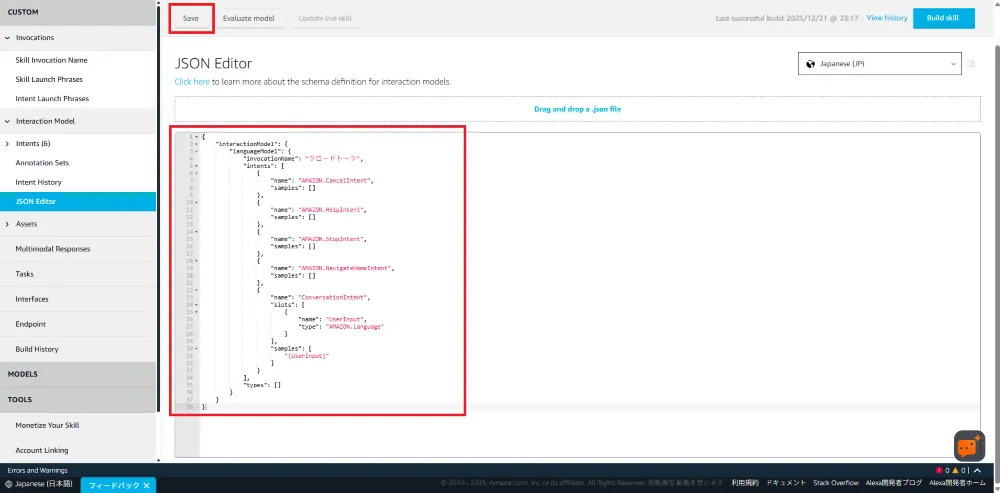
左メニューの「JSON Editor」を開き、以下のInteraction Model JSONを貼り付けて「Save」を押下します。
AMAZON.Languageスロットタイプを使用して、ユーザーの発話を受け取ります。
なぜAMAZON.SearchQueryではなくAMAZON.Languageを使うのか
Alexaスキルで自由入力を受け取る場合、一般的にはAMAZON.SearchQueryというスロットタイプを使用します。しかし、このスロットには以下の制約があります。
- サンプル発話にキャリアフレーズ(「〇〇を検索」など固定フレーズ)が必要
- 他のスロットタイプと同時に使用できない
今回のスキルでは、スキル起動後に何を言ってもAIが応答するようにしたいため、キャリアフレーズなしで{UserInput}だけを登録できるスロットタイプが必要でした。
AMAZON.Languageは言語名のリスト(「日本語」「英語」など)を定義したスロットタイプですが、リスト型スロットはサンプル発話にスロットのみを含めることが許可されています。この仕組みを利用して、ユーザーの自由な発話を受け取れるようにしています。
Interaction Model JSON
{ "interactionModel": { "languageModel": { "invocationName": "クロードトーク", "intents": [ { "name": "AMAZON.CancelIntent", "samples": [] }, { "name": "AMAZON.HelpIntent", "samples": [] }, { "name": "AMAZON.StopIntent", "samples": [] }, { "name": "AMAZON.NavigateHomeIntent", "samples": [] }, { "name": "ConversationIntent", "slots": [ { "name": "UserInput", "type": "AMAZON.Language" } ], "samples": [ "{UserInput}" ] } ], "types": [] } }}9. LambdaとAlexaスキルの連携
Lambda側の設定
Lambda関数にAlexaトリガーを追加します。
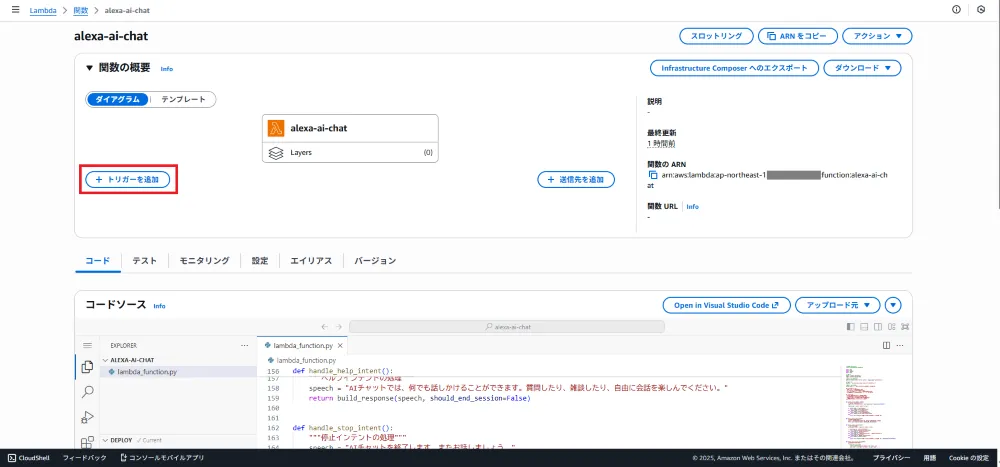
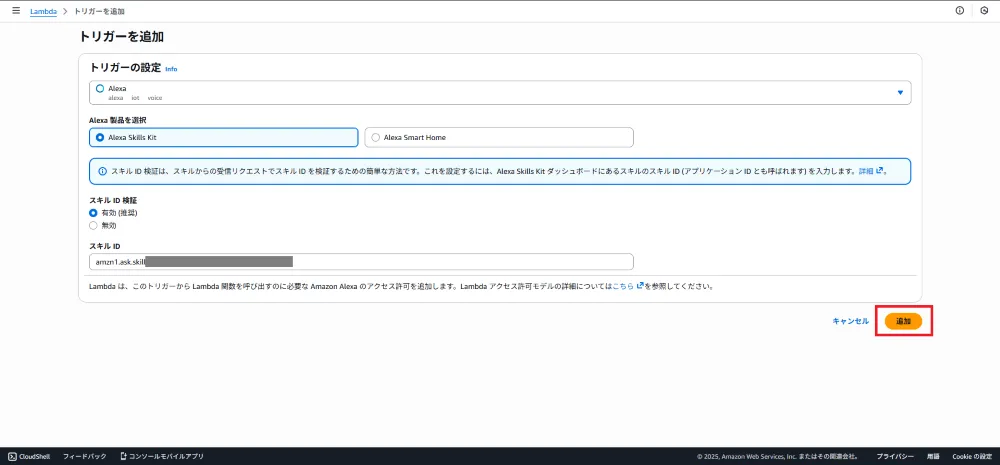
| 項目 | 値 |
|---|---|
| ソース | Alexa |
| Alexa製品 | Alexa Skills Kit |
| スキルID検証 | 有効 |
| スキルID | Alexa Developer ConsoleのEndpoint設定画面「Your Skill ID」で確認 |
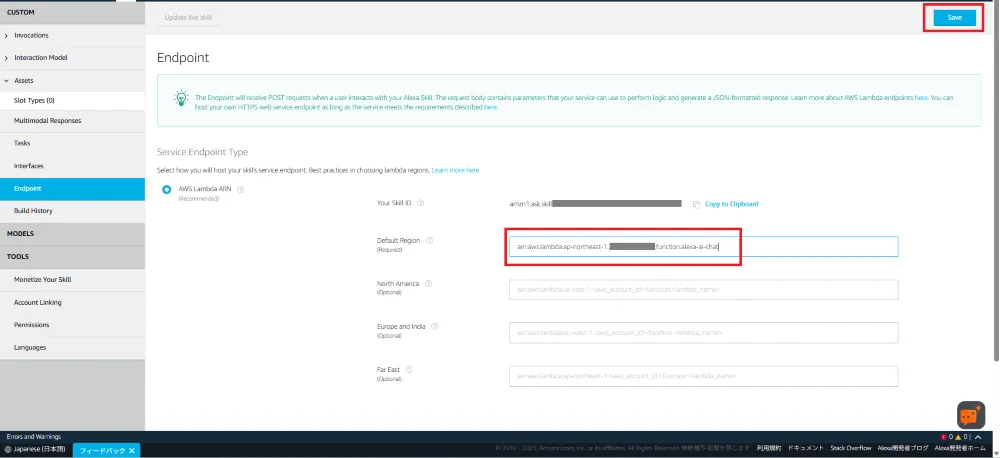
Alexaスキル側の設定
Endpoint設定で、Lambda関数のARNを設定します。
10. スキルのビルドとテスト
設定が完了したら、画面右上の「Build skill」ボタンを押下してスキルをビルドします。
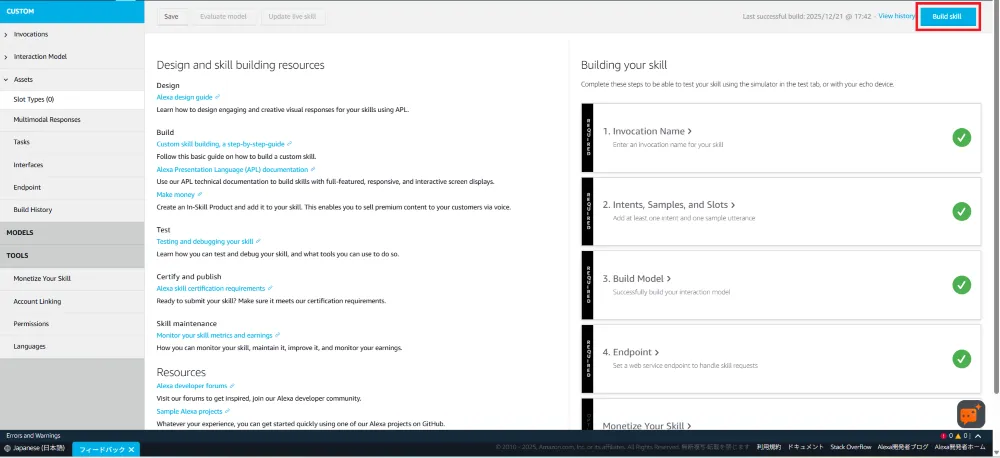
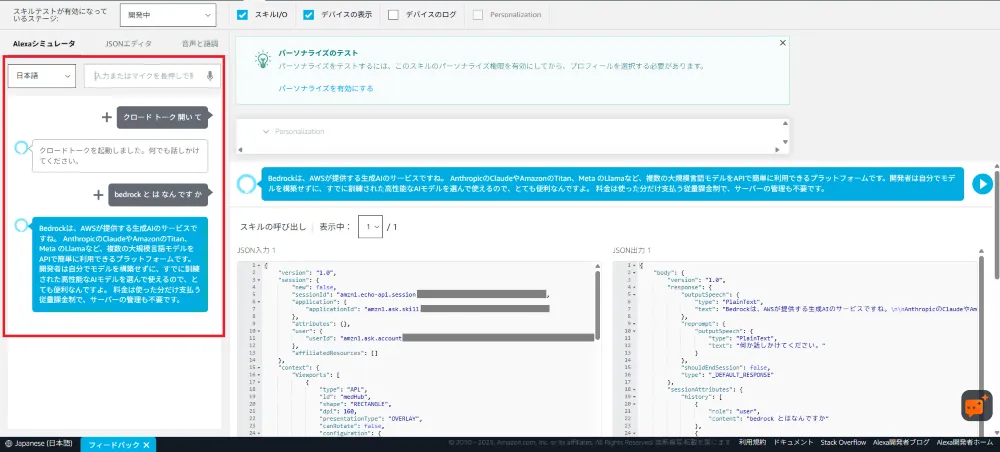
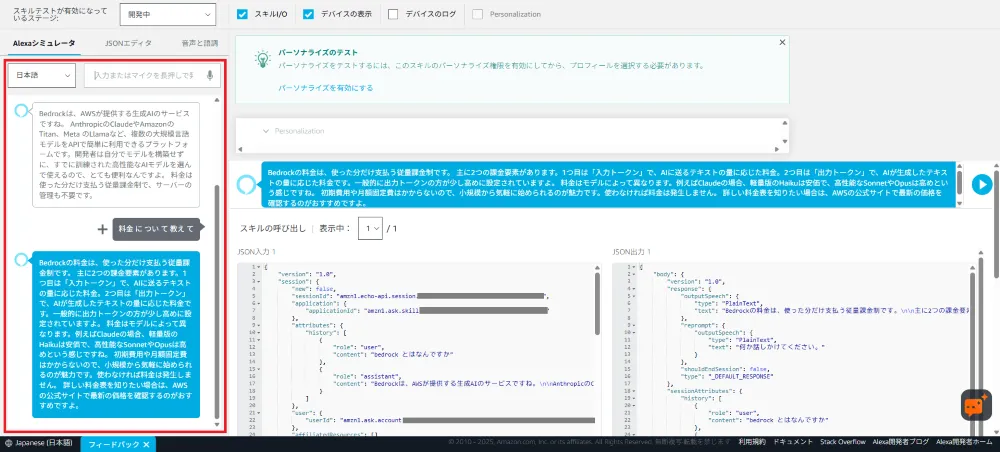
テストタブでシミュレーターを使ってテストできます。
おわりに
Amazon BedrockのClaude Sonnet 4.5を使って、Alexaと音声で会話できるスキルを作成しました。
実際に作ってみることで、以下の理解が深まりました。
- Bedrockの呼び出し方法とJP Cross-Region Inference
- Alexaスキルの構造とLambdaとの連携
- IAMポリシーの設計
- CloudWatchメトリクスを使ったコスト計算
短い会話であれば100回行ったとしても$0.50(約75円)程度で収まるため、気軽に試せます。
