

はじめに
この記事では、Kubernetesの可用性を高めるために重要な二つの機能として、ヘルスチェックとグレースフルシャットダウンについて、それぞれの役割や使用時に注意するべきポイントをご紹介します。
ヘルスチェック
ヘルスチェックとは、システムやアプリケーションなどが正常に動作しているかを、外部から定期的に監視する仕組みです。
Kubernetesに限らず、アプリケーションを運用する中でヘルスチェックは可用性を確保する重要な機能となります。
そのヘルスチェックの機能ですが、Kubernetesには以下の三種類の設定が存在しています。
- Liveness Probe
- Readiness Probe
- Startup Probe
それぞれ使用目的が異なり、誤った使い方をしてしまうと想定外の挙動となってしまう恐れがあります。 そのため、まずはそれぞれの役割について理解を深めていきましょう。
Liveness Probe
Liveness Probeは、そのアプリケーションが正常に動作しているかどうか、つまり 生存状況の確認 を行うヘルスチェックになります。 クラッシュやハングアップが発生していないかなどを検出するために使用するものです。
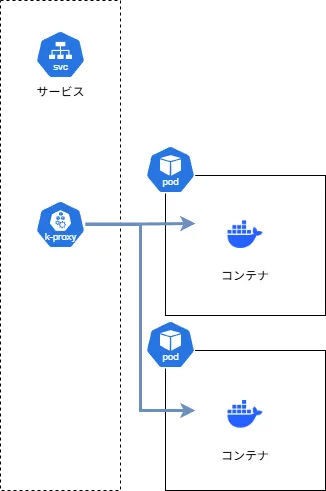
Podが正常な状態を以下のように図示します。 青色の線はトラフィック経路を示しています。
Liveness Probeのチェックステータスが失敗となった場合、Kubernetesは以下のような動作をします。
- コンテナの再起動を行う
- Service(kube-proxy)から切り離しを行い、アクセスできないようにする
図中の上のPodだけが異常となった場合を、以下のように図示します。
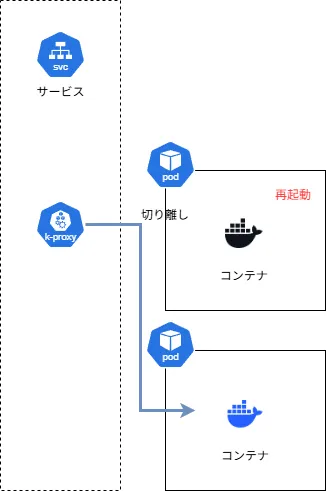
再起動が完了し、Liveness Probeおよび後述するReadiness Probeのステータスが正常になり次第再び上のPodへアクセスできるようになります。
Readiness Probe
Readiness Probeは、そのアプリケーションが正常にリクエストを処理する準備ができているかどうか、つまり 準備状況の確認 を行うヘルスチェックになります。
例えば、アプリケーションが起動時の初期化中であったり、重い処理中など一時的にリクエストを受け付けられない場合などの検知をするために使用するものです。
Readiness Probeのステータスが失敗になった場合、Kubernetesは以下のような動作をします。
- Service(kube-proxy)から切り離しを行い、アクセスできないようにする
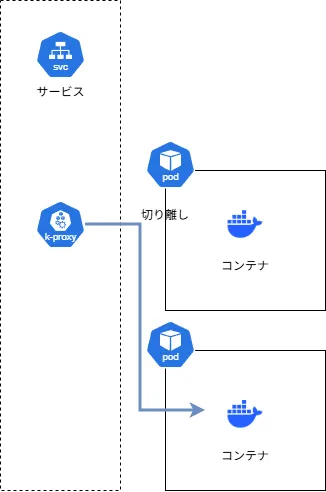
Liveness Probeの失敗時とは異なり、アプリケーションは動いたままなので、リクエストを処理する準備ができてReadiness Probeのステータスが正常に戻り次第、すぐに上のPodへアクセスできるようになります。
Startup Probe
Startup Probeは、そのアプリケーションが正常に起動したかどうか、つまり 起動の確認 を行うヘルスチェックになります。 これまでの二つのヘルスチェックとは異なり、1回成功したらこのヘルスチェックは行われなくなるという特徴があります。
また、Startup Probeが有効な場合、Startup Probeが成功するまでLiveness ProbeおよびReadiness Probeは行われません。
用途としてはJavaなど起動が遅いアプリケーションで、起動中にLiveness Probeがエラーにならないようにするために使用します。 Startup Probeを使用しない場合以下のループが発生するためです。
- コンテナの起動
- Liveness Probeの実行
- Liveness Probeのタイムアウト
- コンテナの再起動開始
後述するLiveness ProbeのパラメータであるinitialDelaySecondsの設定にてLiveness Probeの初回実行時間を遅らせるという手段でも回避はできますが、設定値が短すぎると上記のループが発生し、逆に長すぎるとLiveness Probeが成功するまでに無駄な待機時間が発生してしまうので、Startup Probeの使用が推奨となります。
Startup Probeのチェックステータスが失敗となった場合、Kubernetesは以下のような動作をします。
- コンテナの再起動を行う
使い分けの整理
三種類あるヘルスチェックを、まとめると以下のようになります。
| 特徴 | Liveness Probe | Readiness Probe | Startup Probe |
|---|---|---|---|
| 目的 | コンテナが生きているかの確認 | コンテナがリクエストを受け付けているかの確認 | コンテナが起動しているかの確認 |
| 検知内容 | デッドロックやハングアップなど | 初期化中、重い処理の実行中など | 起動の遅いアプリケーションの起動確認 |
| 検知後の動作 | サービスから切り離したうえ、コンテナ再起動する | サービスから切り離す | コンテナ再起動する |
これらの違いをしっかりと認識した状態でアプリケーション側もKubernetes側も設計を行う必要があります。
ヘルスチェックの実装例
では、実際にManifestにどのように書けばよいのかを見ていきます。
Deploymentの場合、 spec.template.spec.containers 内に記載します。
apiVersion: apps/v1kind: Deploymentspec: template: spec: containers: - name: xxxxx image: xxxxx ports: - containerPort: 80 livenessProbe: httpGet: path: / port: 80 initialDelaySeconds: 3 periodSeconds: 3 readinessProbe: httpGet: path: /ready port: 80 initialDelaySeconds: 3 periodSeconds: 3 startupProbe: httpGet: path: / port: 80 failureThreshold: 30 periodSeconds: 3設定値
また、ヘルスチェックの方法にはHTTP接続、TCP接続、コマンド実行の三種類があり、上記の実装例のものはHTTPリクエストによるものです。
三種類に共通して設定できるパラメータは以下になります。
| 設定名 | 内容 | デフォルト値 | 補足 |
|---|---|---|---|
| initialDelaySeconds | コンテナが起動してからヘルスチェックが開始されるまでの秒数 | 0 | |
| periodSeconds | 実行間隔の秒数 | 10 | |
| timeoutSeconds | タイムアウト判定の秒数 | 1 | これを超えると失敗扱いとなる |
| successThreshold | 一度Probeが失敗した後、次のProbeが成功したとみなされるための最小連続成功数 | 1 | Liveness Probeは1で固定 |
| failureThreshold | 動作するまでの連続失敗回数 | 3 |
HTTPリクエストのパラメータは追加で以下の設定が可能です。
| 設定名 | 内容 | デフォルト値 | 補足 |
|---|---|---|---|
| host | 接続先ホスト名 | PodのIP | |
| scheme | 接続で使用するスキーマ | HTTP | HTTPかHTTPSのみ |
| path | アクセスする際のパス | ||
| port | アクセスするポート | ||
| httpHeaders | カスタムヘッダー | nameとvalueでネストする |
livenessProbe: httpGet: path: /healthz port: 8080 httpHeaders: - name: Custom-Header value: Awesome以下は、コマンドでヘルスチェックを行う方法と、TCP確立でヘルスチェックを行う方法のサンプルです。
livenessProbe: exec: command: - cat - /tmp/healthy readinessProbe: tcpSocket: port: 8080ヘルスチェックに関する話は以上となります。
グレースフルシャットダウン
グレースフルシャットダウンとは、システムやアプリケーションを停止する際に稼働中の処理やリクエストを、安全に完了させてから停止する仕組みです。
Kubernetesでは、アプリケーションのバージョンアップ時などはDeploymentの更新によるPodのローリングアップデートを行うことが最も一般的です。
その更新の際に、グレースフルシャットダウンを行わないと、リクエスト中の処理が終わる前にPodが強制終了してユーザーに影響を及ぼす場合があります。
まずは、KubernetesにおけるPodの削除時の挙動について解説していきます。
Podの削除処理の挙動
まず、Podの終了命令が行われると、「Serviceとkube-proxy」、「Pod」、「コンテナ(アプリケーション)」の三つのリソースがそれぞれ並列して終了処理を行い始めます。
- Serviceとkube-proxy: PodのServiceからの切り離しとiptablesの更新によって削除するPodに通信が流れないようにする。
- Pod: Terminating状態に移行し、terminationGracePeriodSecondsの設定値の時間経過後に強制終了する。
- コンテナ: アプリケーションを終了する。
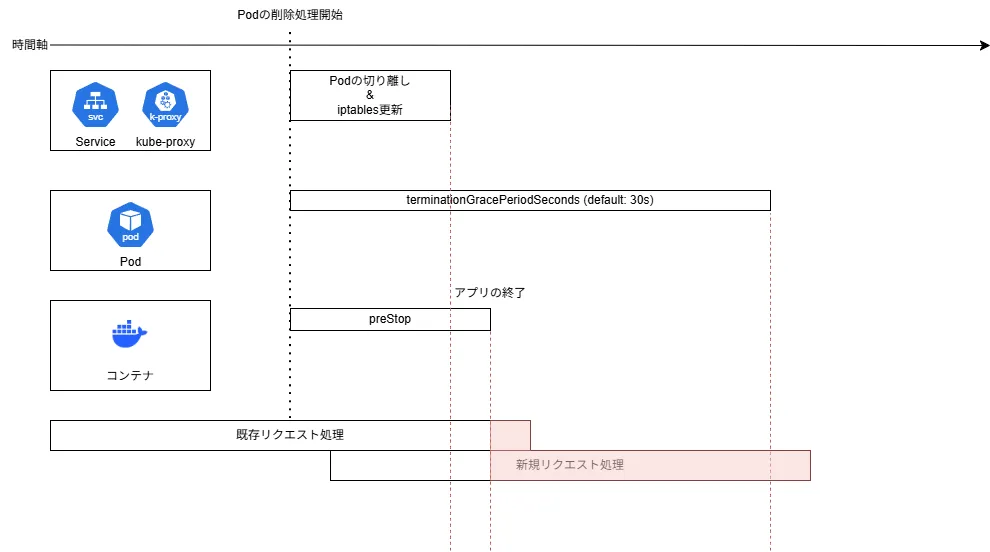
各々並列で処理されるということが重要であり、もし特に何も設定しないまま行うと以下の図のようになってしまいます。
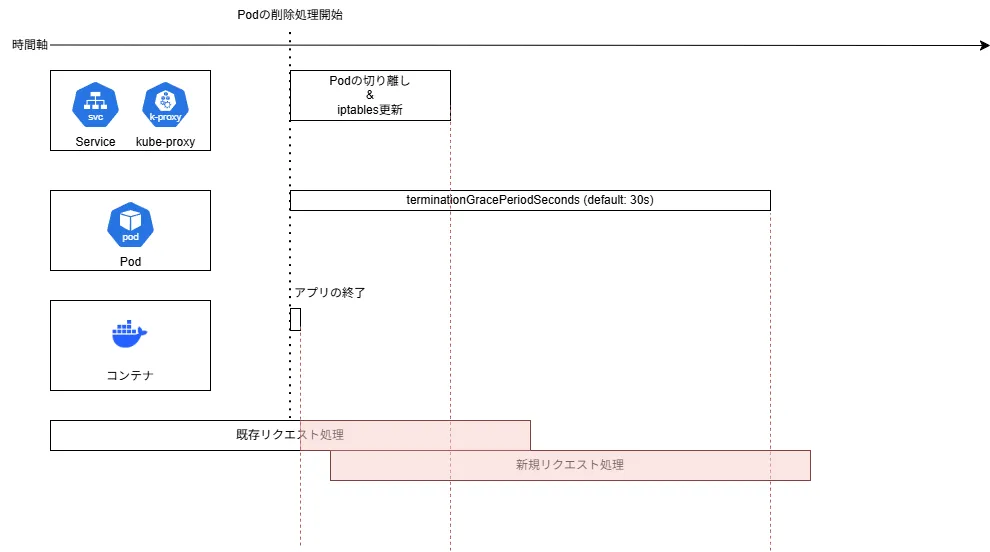
アプリケーションがPodの終了命令と同時に落ちることになり、既存リクエストの処理は強制停止され応答エラーになってしまいます。
また、終了命令直後に流れてくる新規リクエストの処理はiptables変更前のため、落としたPodにリクエストが流れる可能性があります。その場合、接続エラーとなります。
この問題を解消するためにグレースフルシャットダウンが必要なのです。 それでは、設定を一つずつ見ていきます。
PreStop
一つ目は PreStop と呼ばれる設定で、コンテナの終了処理が開始されるまでに行うコマンドを定義できるものです。
以下のように、PreStopの設定でsleepコマンドを用いることでコンテナの終了命令の開始を遅延させることができます。
spec: containers: - name: xxxxx lifecycle: preStop: exec: command: ["/bin/sh", "-c", "sleep 10"]遅延する秒数としては、iptablesの更新にかかる時間よりも長い時間を設定しておけばOKです。 iptablesの更新は明確な値はありませんが約5秒ほどなので、PreStopはそれ以上の値にしましょう。
これで、ServiceからPodが切り離された後にアプリケーションが終了するようになるため、新規リクエストの接続エラーはなくなります。
しかし、この段階ではリクエストを処理しきる前にアプリケーションが落ちてしまうため、依然として応答エラーは残ってしまいます。
アプリケーションのグレースフルシャットダウン
二つ目は アプリケーションのグレースフルシャットダウン です。アプリケーションに残っている応答の処理やリソースの開放を行ってからアプリケーションを終了させる機能になります。設定方法はアプリケーションで使用している言語やフレームワークによって異なるため、ここでは割愛します。
グレースフルシャットダウンの時間はアプリケーションの処理タイムアウトより長くしていれば問題はありません。 アプリケーションのグレースフルシャットダウンを設定すると、以下のようになります。
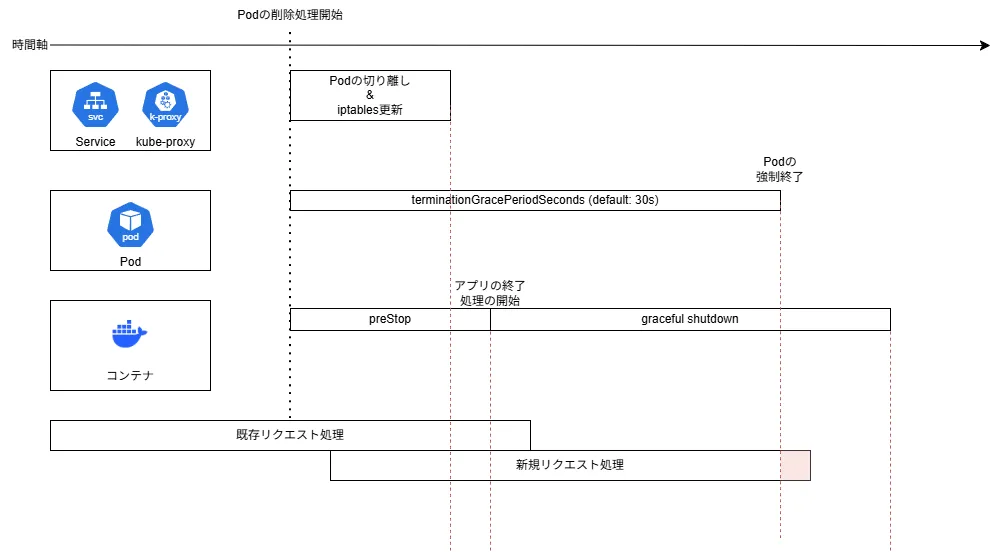
これでアプリケーション自体は、リクエストを処理しきれる時間を確保できるようになりましたが、今度はPodの終了が先に来てしまい強制終了となった場合に応答エラーが発生する可能性が残ってしまっています。
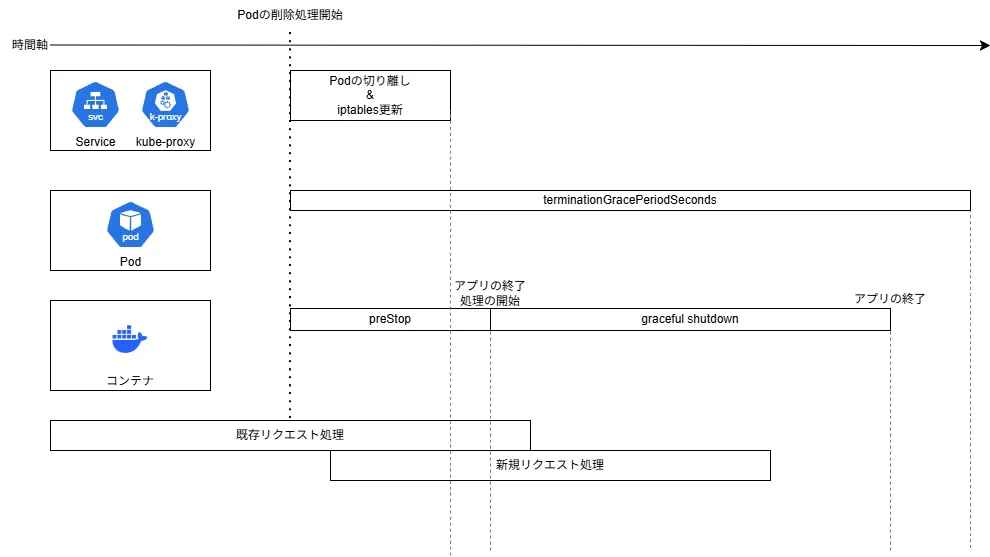
terminationGracePeriodSeconds
三つ目は terminationGracePeriodSeconds という設定で、Podが終了命令を受けてから強制終了するまでの時間を定義するものです。
デフォルト値は30秒が設定されています。
この設定の値は、preStop + アプリケーションのグレースフルシャットダウン を超える設定にする必要があります。
以下のサンプルは90秒に設定をする例です。
spec: terminationGracePeriodSeconds: 90 containers: - name: xxxxx lifecycle: preStop: exec: command: ["/bin/sh", "-c", "sleep 10"]この三つの設定をすることで、ようやくPodの終了時にすべてのリクエストを正常に処理することが可能になります。
グレースフルシャットダウンのまとめ
ローリングアップデート時などにリクエストエラーが起きないようにするために、以下の三つを設定する必要があり、それぞれの設定値をまとめると以下のようになります。
| 設定名 | 内容 | デフォルト値 | 補足 |
|---|---|---|---|
| PreStop | コンテナの終了処理開始までの時間 | 0 | iptablesの更新(約5秒)より長くする |
| アプリケーションのグレースフルシャットダウン | コンテナの終了処理開始から終了までの時間 | - | アプリケーションの処理タイムアウトより長くする |
| terminationGracePeriodSeconds | Podが終了命令を受けてから強制終了するまでの時間 | 30 | PreStop + アプリケーションのグレースフルシャットダウン より長くする |
おわりに
Kubernetesの可用性に関わるヘルスチェックの機能とグレースフルシャットダウンの機能について解説しました。
要点をまとめると以下になります。
-
ヘルスチェック
- Liveness Probe(生存確認) と Readiness Probe(準備確認) と Startup Probe(起動確認) の 三種類が存在する。
- それぞれ失敗時の挙動が異なるので注意する。Liveness ProbeはServiceから切り離したうえでコンテナを再起動、Readiness ProbeはServiceからの切り離しのみ、Startup Probeはコンテナの再起動を行う。
- Startup Probeは起動時のみの確認のために用いられ、成功後にStartup Probeは停止し、Liveness ProbeとReadiness Probeが開始する。
-
グレースフルシャットダウン
- アプリケーションの終了時に正常に落とすための設定。
- PreStop、アプリケーションのグレースフルシャットダウン、terminationGracePeriodSeconds の三つの設定を組み合わせて実現する必要がある。
可用性は情報システムにおいてシステムの信頼性を保証する重要な指標のひとつであり、この記事で紹介した機能はKubernetesを用いるうえで理解が必須となります。Kubernetesでシステムを構築する際に、この記事が少しでもお役に立てれば幸いです。
記事の執筆にあたっては情報の正確性に努めておりますが、掲載されている文章やソースコード、設定ファイル等の内容について、完全な正確性や安全性を保証するものではありません。活用される際は、必ず公式ドキュメント等をご自身で確認のうえご判断ください。
