
Linux で動く AI で Windows アプリの E2E テストはできるか

はじめに
こんにちは。経営企画本部 AI 推進室の長田です。この記事は、Linux で動く AI エージェントを用いて Windows アプリの E2E テストが実現可能かどうかを検証した内容です。今回の検証には GitHub Copilot を使いました。CI/CD の自動化や AI エージェントの活用に関心のある方に参考になればと考えています。
きっかけは、Linux で動く AI エージェントの導入を検討しているチームからの「Windows Forms アプリの E2E テストも Linux 環境で動くエージェントに任せられますか?」という相談でした。Windows Forms アプリは Windows 環境でしか起動しません。そのままでは実現不可能です。
そこで考えたのが、「コードを書く役」と「実行する役」を分けるアプローチです。AI エージェントにテストコードの作成・修正を担わせ、アプリの実行と結果収集は別で用意した Windows 環境に任せる。この役割分担であれば、実行環境の制約は乗り越えられるのではないかと考えました。
ただ、その手法で実行環境の問題が解決できたとしても、AI エージェントはアプリの動作を直接見られません。テストが失敗しても、何が起きたのかを自分で確認できません。それでも、渡す情報を工夫すれば判断できるのではないか、と考えて検証を始めました。
実行環境を分離する
まずは、Linux で動く AI エージェントから Windows 環境を扱う方法を調べました。大きく分けていくつかのアプローチが考えられました。
| アプローチ | 概要 | 主な課題 |
|---|---|---|
| RDP 経由の画面操作 | AI エージェントから RDP で Windows VM に接続し、画面を見ながら操作 | 二重リモートになり操作が不安定。ピクセルベースの検証は脆い。 |
| WebDriver 経由のリモート操作 | Windows VM 上の WebDriver サーバーに AI エージェントが HTTP で接続 | VM の常時稼働が必要。開発が終了しており、メンテナンスされていない。 |
| SSH / WinRM 経由の実行 | AI エージェントが Windows に接続してテストを起動・結果を取得 | 専用 Windows マシンの準備と管理が必要。 |
| CI の Windows ランナーで実行 | AI エージェントはテストコードの作成に専念し、実行は CI に任せる | AI エージェントがアプリを直接見られない。 |
今回は CI の Windows ランナーを使う方法を選びました。追加のインフラが不要で、PR のワークフローにそのまま組み込める点が決め手です。テスト環境が毎回クリーンに初期化されるため、実行結果も安定します。
テストには FlaUI(UI Automation ベースの Windows GUI テストライブラリ)と NUnit を使用しています。FlaUI は UI 要素を Name や AutomationId(Windows の UI Automation で使用される、UI 要素を一意に識別するための ID)で識別するため、UI の変更に比較的強く、テストコードの保守性が高いのが特徴です。
今回使用した GitHub Copilot との連携は、GitHub 上での PR の更新をトリガーにしています。GitHub Copilot は GitHub と連携しているため、CI の実行結果を参照できます。テストが失敗した場合は CI 側から GitHub Copilot に通知し、修正を依頼する流れです。この仕組みの詳細はワークフローの章で説明します。
GitHub Copilot に渡す情報を設計する
次に、何を渡せば GitHub Copilot が判断できるかを考えました。
GitHub Copilot はアプリの動作を直接見られません。テストが失敗したとき、GitHub Copilot が持っている情報は「テストが落ちた」という事実だけです。そのままでは、失敗の原因を解析できません。
そこで立てた仮説が、次の 4 種類の情報を渡せば、テストが失敗した際に原因を判断して修正できるのではないか、というものです。
| 渡す情報 | 内容 |
|---|---|
テスト結果ファイル(.trx) | NUnit の出力。テスト名・結果・エラーメッセージが含まれる。 |
| スクリーンショット | テスト実行中にキャプチャした画面。失敗時点の UI の状態が確認できる。 |
| アプリログ | アプリが何をしたかを記録したファイル。テストコードではなくアプリ側の視点で動作を追える。 |
| UI ツリーダンプ | 失敗時の UI 要素ツリーのダンプ。どの要素が存在するか、AutomationId を確認できる。 |
テスト結果ファイルとスクリーンショットは FlaUI の仕組みでそのまま取得できます。UI ツリーダンプも FlaUI で取得できますが、毎回収集するとコストがかかるため失敗時のみ収集するようにしました。一方、アプリログはアプリ側に仕込む必要があります。
アプリログには、フォームの表示・非表示、ボタン操作の結果、バリデーションのエラー理由など、アプリが何をしてどうなったかを残すようにしました。例えばログイン失敗であれば login failed, reason=invalid_credentials のように、何が起きたかを理由付きで出力します。こうすることで、テストが「ログインできなかった」と報告したとき、アプリがそもそも認証を弾いたのかどうかをログで確認できます。

スクリーンショットのファイル名には PASS_・FAIL_・STEP_ のプレフィックスをつけています。どのテストのどの時点での画面か、ファイル名から追えるようにするためです。PASS_ と FAIL_ はテスト終了時に自動で保存されます。テスト結果に応じてプレフィックスが決まる仕組みをテストの基底クラスに組み込み、どのテストでも自動で動くようにしました。STEP_ は GitHub Copilot がテストコードを書く際に、確認したいと判断した操作の前後で撮るよう指定しています。
これらを CI のアーティファクトとしてアップロードし、gh run download で取得できる形にすれば、GitHub Copilot が参照できるのではないかと考えました。
ワークフローの全体
ここまで考えたことを元に、次のようなワークフローを作成しました。PR の作成・更新をトリガーに自動で起動します。
テスト実行(Windows ランナー) ↓アーティファクト収集(常時) ├─ テスト結果ファイル(.trx) ├─ スクリーンショット └─ アプリログ ↓(失敗時のみ)アーティファクト収集 └─ UI ツリーダンプ ↓(PR かつ失敗時のみ)GitHub Copilot へ通知テスト実行時は APP_LOG_PATH 環境変数でアプリログの出力先を指定しています。CI 上では TestResults/app.log に書き出され、そのままアーティファクトとして収集できます。
env: APP_LOG_PATH: ${{ github.workspace }}\winforms-e2e-poc\TestResults\app.logスクリーンショットと UI ツリーダンプのアップロードタイミングは意図的に分けています。スクリーンショットはどのテストでも確認したいため常時、UI ツリーダンプは失敗時にしか使わないため失敗時のみにしました。
GitHub Copilot へのプロンプトには、アーティファクトを gh run download で取得するコマンドをそのまま渡しています。どのファイルに何が入っているかも説明することで、GitHub Copilot が何を見て判断すればよいかを明示しています。
gh run download <run_id> --repo <repo> --name test-resultsgh run download <run_id> --repo <repo> --name ui-screenshotsgh run download <run_id> --repo <repo> --name ui-tree-dumpsgh run download <run_id> --repo <repo> --name app-log実際に動かしてみた
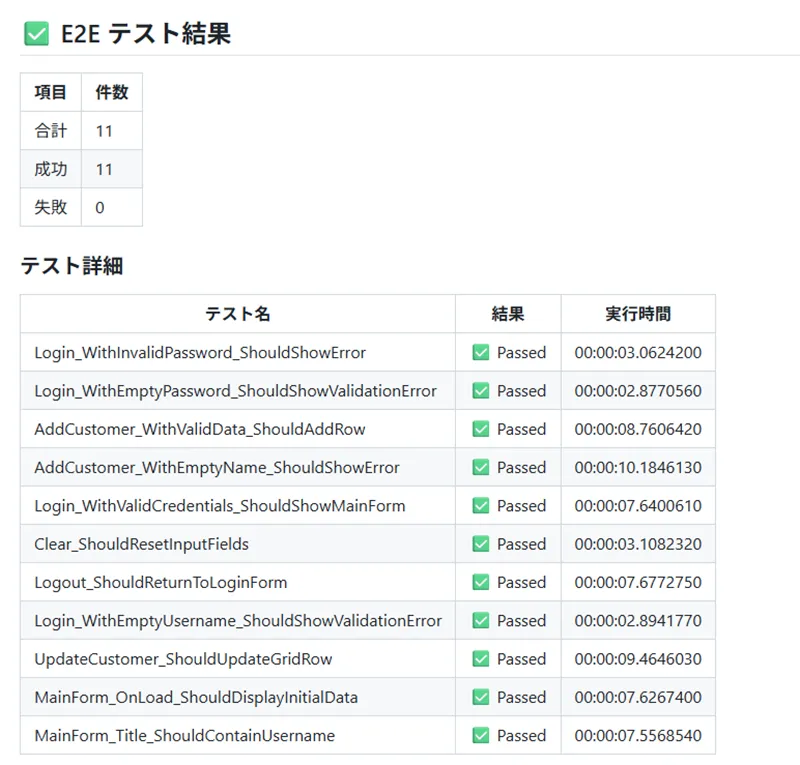
まず、ワークフローの基本動作の確認を行いました。 結果としては、PR 作成時にワークフローがトリガーし、テストが実行され、全件成功させることができました。また、app-log・test-results・ui-screenshots の 3 種のアーティファクトが生成されることも確認できました。
続いて、4 つの失敗パターンを試しました。ここで確認したかったのは、次の 3 点です。
- テストが失敗したときに GitHub Copilot へ通知が届くこと
- 通知を受けた GitHub Copilot がアーティファクトを参照できること
- アプリ側の問題かテストコード側の問題かを判断して修正できること
シナリオ1: 画面遷移バグ(アプリ側のバグ)
ログイン成功後にメイン画面(MainForm)を表示しないバグを仕込みました。
アプリログにはフォームの表示状態を残すようにしており、このシナリオでは次のように出力されます。
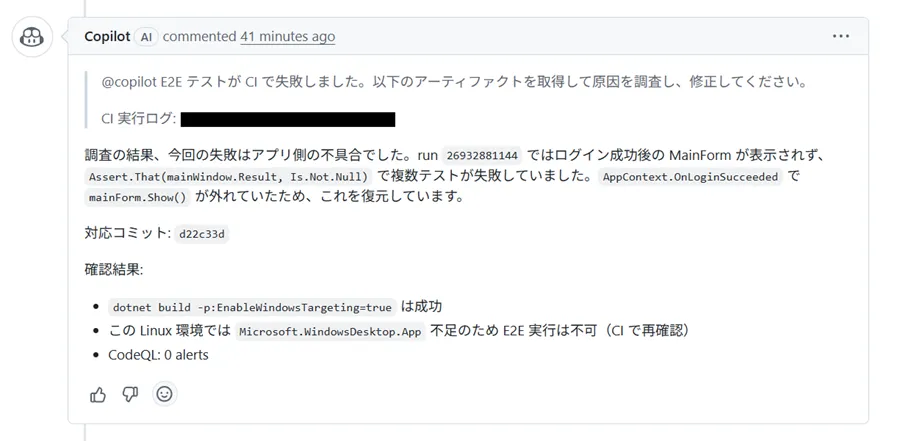
LoginForm: login succeeded, user=adminMainForm: shown, user=admin, visible=Falseテストを実行すると「メイン画面の要素が見つからない」で失敗し、スクリーンショットやアプリログがアーティファクトとして収集されました。その後、想定通りに GitHub Copilot へ通知が届き、調査が始まりました。
GitHub Copilot は最初にテスト結果を確認し、その後ソースコードを直接確認しにいき、AppContext.cs で mainForm.Show() がコメントアウトされていることを読んで修正しました。
シナリオ2: 認証バグ(アプリ側のバグ)
正しいパスワードが弾かれるようにバグを仕込みました。
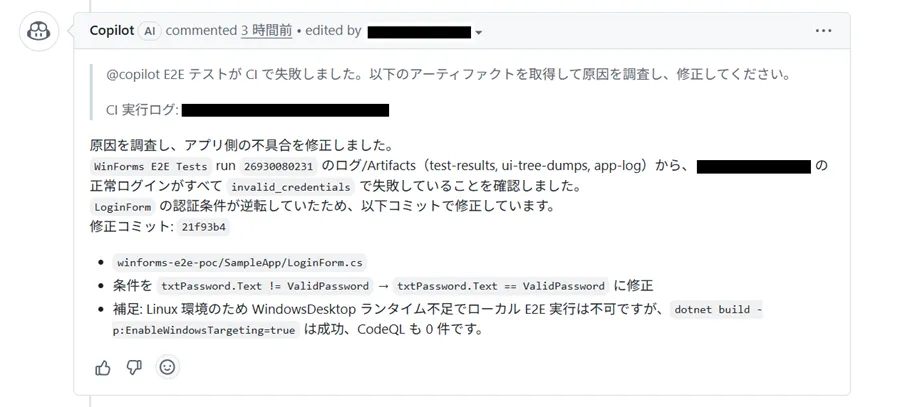
アプリログには認証の試行と失敗理由を残すようにしており、このシナリオでは次のように出力されます。
login attempt, username=adminlogin failed, reason=invalid_credentialsワークフローが走ると、GitHub Copilot は テスト結果ファイル・アプリログ・UI ツリーダンプ の 3 つを並列に参照し、アプリの認証条件が壊れていると判断して LoginForm.cs の条件式を修正しました。
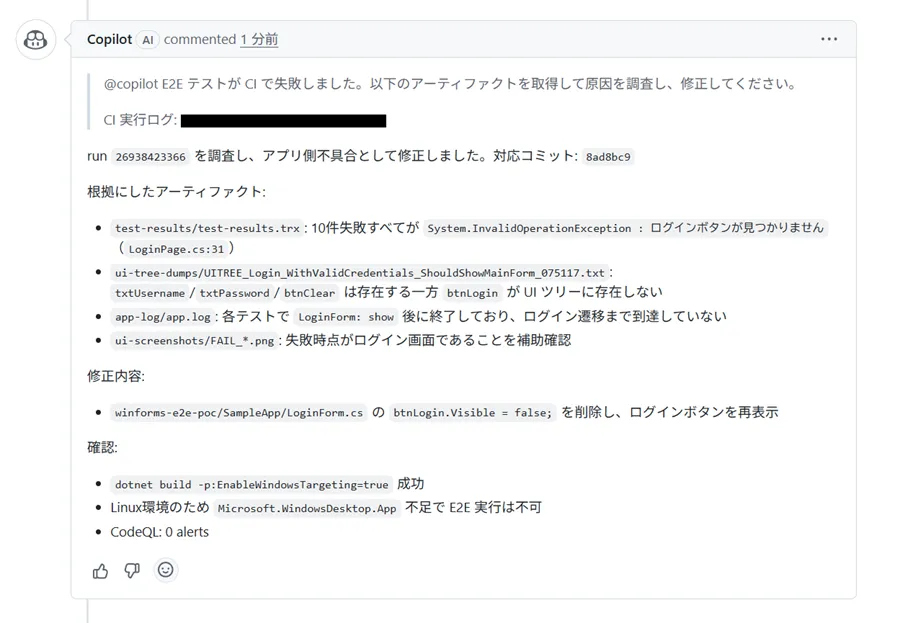
シナリオ3: ボタン非表示バグ(アプリ側のバグ)
ログインボタンを非表示にするバグを仕込みました。アプリログにはフォームの表示状態のみを記録しており、このシナリオでは LoginForm: show が出力されますが、ボタンの状態は記録されません。
修正する際に、GitHub Copilot が根拠として挙げたのは、テスト結果ファイルの例外メッセージ(「ログインボタンが見つかりません」)、UI ツリーダンプ(btnLogin が他の要素は存在する中でツリーに出てこない)、アプリログ(LoginForm: show の後にログイン遷移まで到達していない)の 3 点でした。スクリーンショットは「失敗時点がログイン画面であることを補助確認」として参照されましたが、決め手にはなりませんでした。
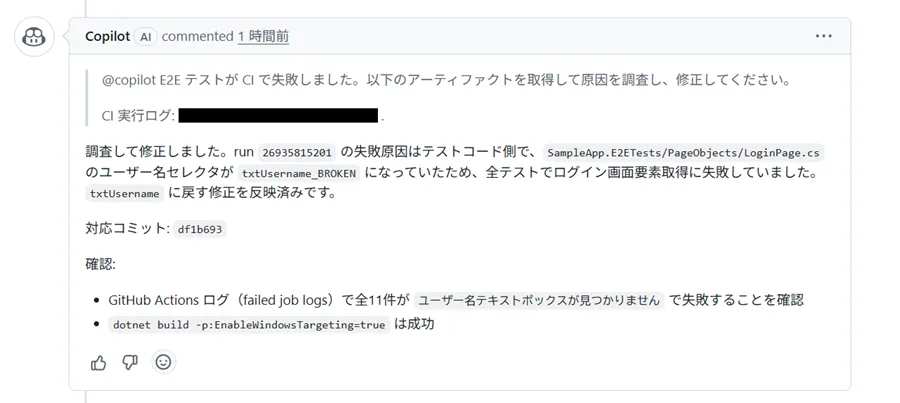
シナリオ4: セレクターミス(テストコード側の問題)
テストコードの要素名を存在しない AutomationId に書き換えました。シナリオ1〜3はアプリ側のバグでしたが、このシナリオはテストコード側に問題を仕込んでいます。GitHub Copilot がアプリ側とテスト側を正しく切り分けられるかを確認するためです。
GitHub Copilot は CI のジョブログで全テストが「ユーザー名テキストボックスが見つかりません」で失敗していることを確認し、テストコード側の問題と判断して LoginPage.cs のセレクターを修正しました。
4 つのシナリオすべてで、GitHub Copilot はアーティファクトをもとに原因を正しく切り分けて修正できました。
まとめ
仮説はおおむね成立しました。GitHub Copilot は 4 つのシナリオすべてで、渡した情報をもとに原因を判断して修正できました。
各シナリオで GitHub Copilot がどの情報を根拠にしたかを振り返ると、GitHub Copilot は渡した情報を単に読むのではなく、根拠として使える情報を自分で探しにいく動きをしているように見えました。アーティファクトに明確な手がかりがあればそれを使い(シナリオ2・3)、なければソースコードまで掘り下げます(シナリオ1)。そのため、渡す情報は「GitHub Copilot が判断しやすい手がかりを増やす」という観点で設計するのが有効だと考えています。
今回試したシナリオでは、スクリーンショットが判断の決め手になる場面はありませんでした。シナリオをさらに増やして同様の傾向が続く場合、スクリーンショットの収集を見直す余地があります。画像はテキストに比べてコンテキストを多く消費するため、判断に必要な情報をテキストで揃えられるのであれば、スクリーンショットを絞ることでコンテキストの効率化につながります。
渡す情報の設計では、テスト結果ファイルだけでなく、アプリログを加えることでテスト側とアプリ側の両方の視点が揃います。どちらの視点が欠けていても、原因の切り分けが難しくなります。この考え方は今回の構成に限らず有効だと考えています。
役割の分け方自体も汎用性があります。AI エージェントが直接見られない環境がある場合、その部分だけ CI や別の実行環境に任せるという発想は、Windows に限らず特定の OS や特殊な実行環境が必要な場面で同じように有効だと考えています。
さいごに
今回は、AI エージェントが直接見られない Windows アプリに対して、CI の Windows ランナーで実行し、その出力を渡すことでフィードバックループを作れないか検証しました。
最初は「実行環境がないのにどうやってテストするのか」という問いからスタートしましたが、実行は別の環境に任せればよいと気づいたことが転機でした。できないことを「できる環境」に委ねる発想で、AI エージェントの活用範囲を広げられる可能性があります。
同様の課題を抱えるエンジニアの参考になれば幸いです。
記事の執筆にあたっては情報の正確性に努めておりますが、掲載されている文章やソースコード、設定ファイル等の内容について、完全な正確性や安全性を保証するものではありません。活用される際は、必ず公式ドキュメント等をご自身で確認のうえご判断ください。
