

[!] この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
以前、当社では、サーバーのシステムログをクラウドに収集する仕組みを構築しました。この「ログ管理システム」の構成を変更して、ストリーミングデータの中継サービスであるAmazon Kinesis Data Firehose(以下、Firehose)を外してみました。この記事では、経緯と考慮した点について紹介します。
サマリー
主な構成変更点は、以下の通りです。
- Firehoseを外し、アグリゲーターからAmazon S3へ直接ログデータを送る
- Firehoseを外した影響を考慮し、ETL処理(ログ分類、ログ圧縮、ログ整形)を見直し
課題:高額になってしまったFirehose、必須かどうか
Firehoseはストリーミングデータを中継・変換し、様々なサーバーやサービスへ配信するサービスです。データレイクなどの仕組みで使われることが多いです。データ処理量単位の課金体系なので、特定のサービス・システムのログを対象とするのであれば、かなり安く使える点もメリットです。
しかし、当社のログ管理システムは100台規模のシステムログを対象としているためか、Firehoseによる1ヶ月のデータ処理量が10TBの水準となりました。特にWebプロキシやファイアウォールのログは、昨今のリモートワークやWeb会議の増加により、さらに増加傾向です。結果としてFirehoseの料金が高額になり、システム全体のコストの約3分の2近くを占めるようになりました。
この水準のデータ量を安定して中継してくれる点で、Firehoseは素晴らしいサービスですが、データの変換はあらかじめアグリゲーターで行い、Firehoseからの送信先がS3に限られる当社の構成では、Firehoseの安定性以外のメリットを活かしていたとは言えませんでした。
そこでAWSに技術相談してみたところ、アグリゲーターからFirehoseを経由せずにS3へ直接送信するアプローチを提案していただきました。S3のPUTリクエスト性能が向上 ⧉したことで、ログファイルをS3へ短時間に大量に送れるようになったそうです。このため、Firehoseを思い切って外してみることにしました。
なお、変更前の構成は、以下のとおりです。詳しくは、「サーバーのシステムログをクラウドに収集する仕組み」をご覧ください。
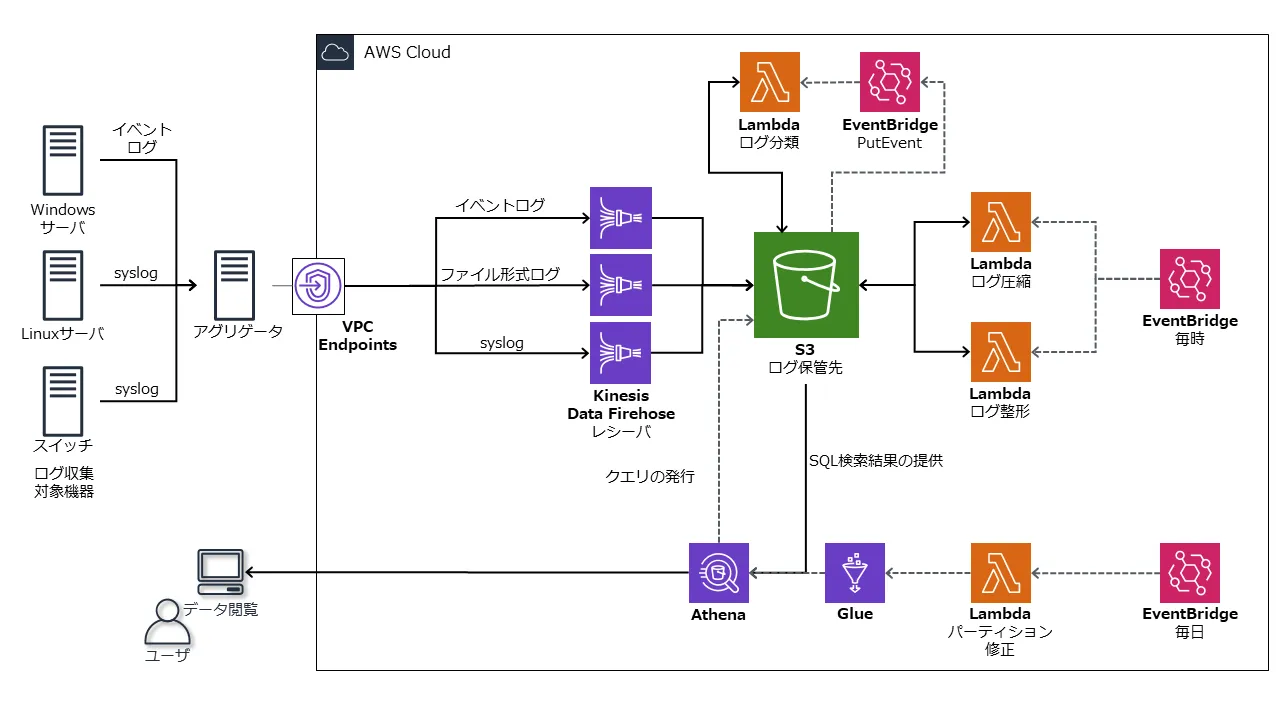
Firehoseを使わない構成における考慮点
アグリゲーターの調整
今回の構成変更では、アグリゲーターからS3への送信をインターネット経由としました1。そこで、社内のWebプロキシの可用性や、S3のPUTリクエスト上限(秒間3,500リクエスト以内)を考慮して、アグリゲーターであるFluentdのバッファー設定を見直しました。
下の図のように、Fluentdはクライアントから受け取ったレコードを、バッファー内のステージにChunkという単位で蓄積します。Chunkは満杯になるか時間が経過するとEnqueueされ、キューはChunkを順次送信していきます。小さいChunkを頻繁に処理するとCPU負荷がかかり、大きいChunkを蓄積しすぎるとメモリから溢れる懸念があります。
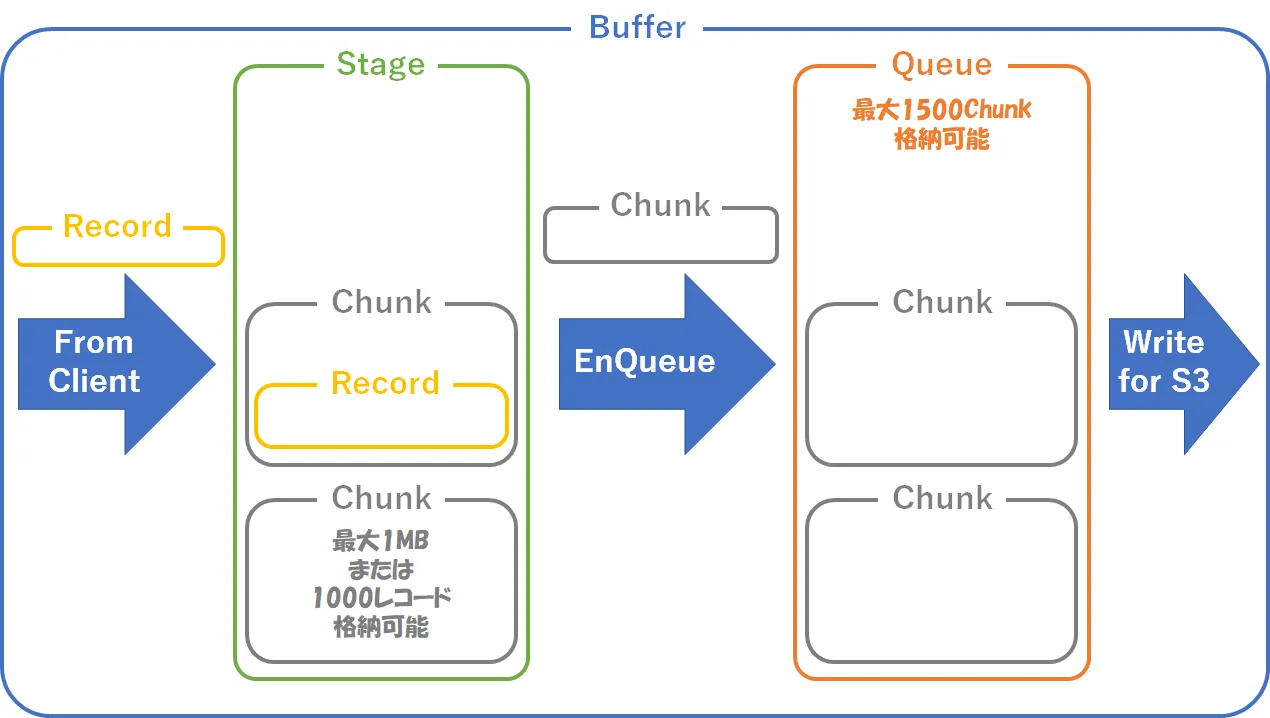
Fluentdサーバーのスペックは仮想4コア、メモリ4GBです。試験運用の結果、100台規模のシステムログを受け取ってS3へ送信する今回のケースでは、CPUのほうがボトルネックになりやすくメモリに余裕がありました。このため上の図のパラメーターのように、Chunkサイズを大きめに、キューに格納可能なChunk数も多めに設定しました。
ETL処理の見直し
Firehoseは、アグリゲーターから送られてくるログを1分間溜めて、1つのファイルにまとめてからS3に保管する役割を担っていました。Firehoseを構成から外したことにより、AWS Lambdaで実行している処理も見直すことになりました。こちらについては、検討段階から明確だった問題ではなく、15分(Lambdaで設定可能な最大タイムアウト時間)以内に終わらなかった関数を解析して対応していきました。
Lambdaで実行しているETL処理は、ログ分類、ログ圧縮、ログ整形の3つで構成されています。このうち、生ログ圧縮処理と整形処理では、S3に格納されている複数のログファイルを1つのファイルに結合していました。しかし、S3に格納されるファイル数の増加により時間がかかるようになりました。
この点について、複数ファイルを1つに結合する処理は、ログ分類にオフロードさせました。これに伴い、実行タイミングもS3のPUTイベントから10分間隔に変更しました。この変更により、ログ圧縮処理は長くても5分程度で終わるようになりました。
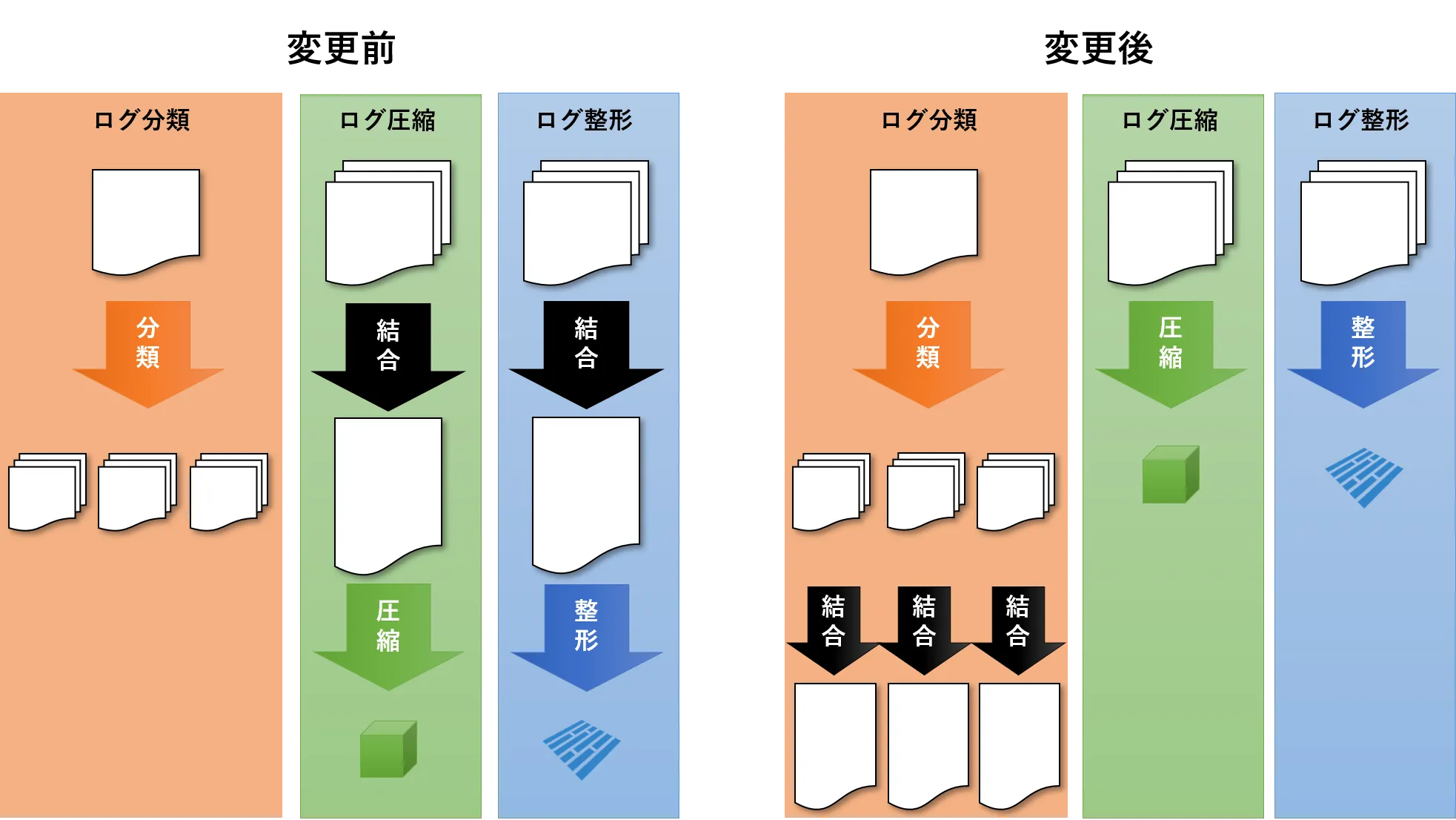
整形処理は依然としてタイムアウトすることがあったため、ファイルサイズの大きいログを別のLambda関数に分けて処理することにしました。具体的には、Webプロキシのログが該当します。この対応で、整形処理のほとんどが10分以内に収まるようになりました。
なお、ETL処理のあり方について「そもそもLambdaに任せるのが適切なのか」という点から、マネージドなETLサービスであるAWS Glueも検討しました。Pythonのコードを移植しやすいのですが、毎時処理を前提とすると高コストになるため、見送りました。日次処理であればリーズナブルなので、どれくらい直近のログを扱えればいいかの要件次第ではフィットしそうです。今回は、処理能力とコストの両面でLambda以上Glue未満な乗り換えやすいサービスが見つからず、LambdaをETLで使う方向性を維持しました。
まとめ
クラウドベースのログ管理システムにおける構成変更を紹介しました。変更後の構成は、以下になります。
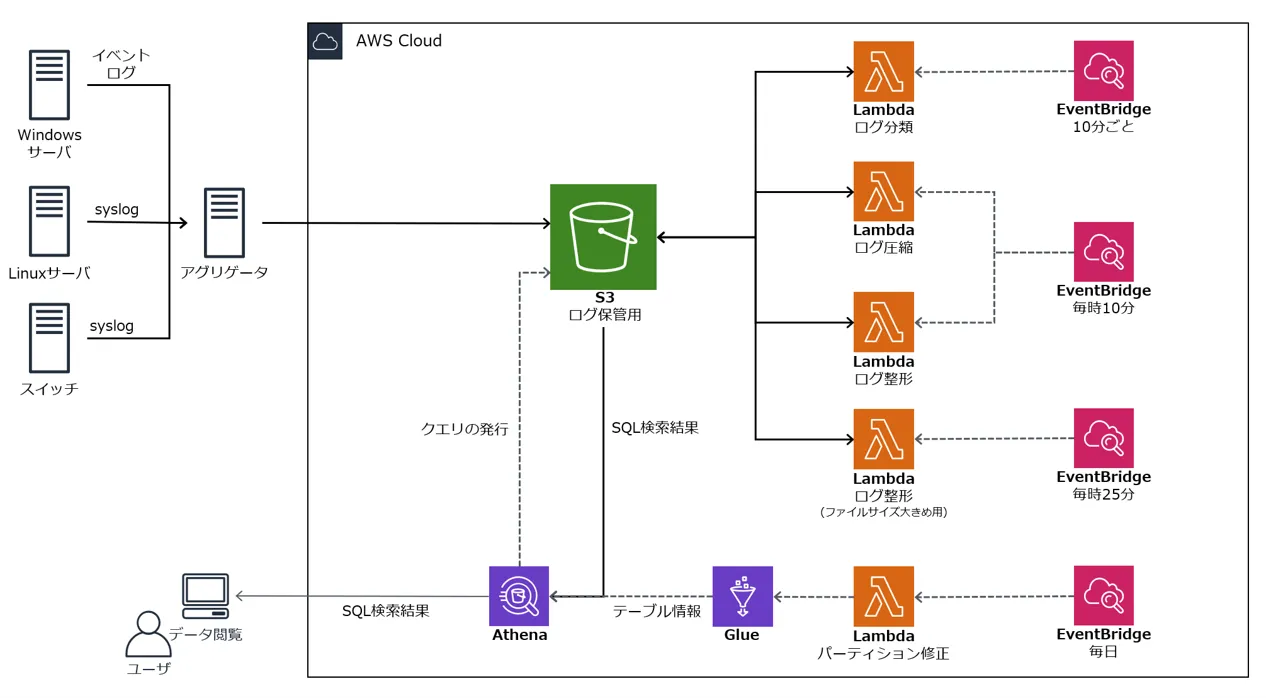
ログを集めるためにもっとも重要な存在だと思い込んでいたFirehoseがそうとも限らないと知ったときは驚きました。そして実際にFirehoseを外したことで、スケーラブルで安定したバッファー役であったことを再認識しました。
とはいえ、なくなった要素を他のサービスでカバーしやすいのも、アーキテクチャ全体を見直すことで改善の余地が見出しやすいのも、クラウドの醍醐味です。ログ管理システムも、システムとユーザーの抱える課題を解消するために、今後も形を変えるのかもしれません。コストの観点も然ることながら、可用性やログの扱いやすさを重視して改善していきたいところです。
Footnotes
-
検討時点ではS3がPrivateLinkに未対応で、オンプレミスのアグリゲーターからVPN経由でS3に送信できませんでした。送信データの暗号化がHTTPSのみで十分かどうかは、悩ましいところです。Webプロキシの負荷やネットワーク構成等の要素も考慮して、今後VPN経由で送信する構成に戻る可能性もあります。 ↩
記事の執筆にあたっては情報の正確性に努めておりますが、掲載されている文章やソースコード、設定ファイル等の内容について、完全な正確性や安全性を保証するものではありません。活用される際は、必ず公式ドキュメント等をご自身で確認のうえご判断ください。
