
[!] この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
初めまして。経営企画本部AI推進室の鏡味、窪田、小林と申します。当社は本年度、AI推進室という新組織を発足させ、主に生成AIについての社内の利用促進、およびユーザーへ生成AIを活用したソリューションの提供を進めるべく、新技術の展開や検証を行っています。
今回は、最近話題となっている、Microsoftが発表したRAG(Retrieval Augmented Generation)技術であるGraphRAG ⧉について、元となる論文やブログ記事、GitHubのコードを元に内部の構造を解析し、さらに現時点でどの程度実用的かを考察していきます。
GraphRAGとは
GraphRAGは、ナレッジグラフと生成AIの技術を組み合わせることで、従来のRAGでは対応が難しかった問い合わせに回答できるようになったRAGです。2024年2月にMicrosoftによって発表 ⧉され、その後、2024年7月にリファレンス実装がGitHubに公開 ⧉されました。
ナレッジグラフのイメージをつかみやすくするため、この記事でGraphRAGの検証に使用している「歴史上の人物に関するWikipedia記事の検索インデックス」を視覚化してみました。視覚化にはgraphragのGitHubにあるgraph-visualization.ipynb ⧉を使用しています。直接役立つかどうかはさておき、未来感のイメージがワクワクしますね!


このような構造のデータをどう作るか、どのようにして良い回答ができるRAGに結びついていくのか、これから説明していきます。
従来のRAGと課題
RAGは、検索エンジンと生成AIの組み合わせで大規模な文書から情報を取得して要約し、生成AIが持っていない知識を回答する仕組みです。RAGのシンプルな実現方法であるナイーブRAGの処理手順は以下です。
- データのインデクシング時: 文書をチャンクと呼ばれる短めのテキストに分割し、それぞれの意味をベクトルに変換しベクター機能を持つDBに格納
- 利用者からの質問時: 質問内容と意味的に近い情報をDBから取り出し、生成AIに要約させて回答を生成
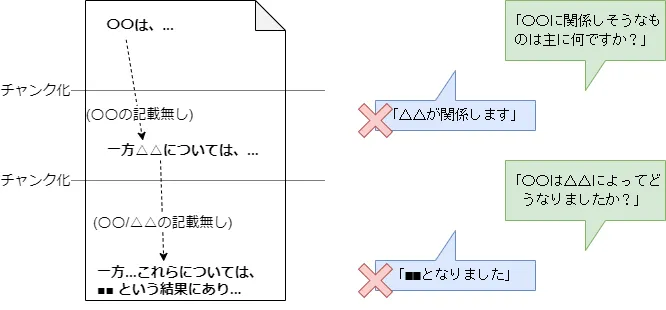
この「意味的に近いものを取り出す」は、一見うまく動作するようで苦手分野があります。以下のような質問です。
- 「〇〇に関係しそうなものは主に何ですか?」(〇〇は知っている情報だが、何が関係しているかは不明)
- 「〇〇は△△によってどうなりましたか?」(〇〇と△△はゆるいつながり)
期待した回答が得られるかは「〇〇(および△△)と意味的に近いチャンク化されたテキストが検索にヒットし、その付近に知りたい情報が入っているか」によります。「関係はするけど主な(頻出する)情報ではない」「〇〇と△△双方に関係するテキストがヒットしない」場合、期待した回答が得られません。つまり、以下のような状況ではうまく行きません。
- 回答につながる手掛かりが質問に含まれていない
- チャンク化されたテキスト内に、関係する情報が入っていない
この問題は、チャンクサイズを大きくしたり、オーバーラッピング(重複を持たせて分割)しても解決には限界があります。極論を言えば、文書の先頭と最後尾に書かれている情報が、実は何かしらのキーワードの連鎖により関連しており、それらがチャンク化により分断されるかもしれません。
ナレッジグラフとRAG
RAGの課題を解決するために、アドバンストRAG、モジュラーRAGといった改善アプローチが多く見られますが、より本質的な解決のために、インデクシングしたデータのありかたから見直すアプローチがあります1。その一つがナレッジグラフで、文書から以下のように「トリプル(Subject, Predicate, Object)」の三要素を取り出し、ノードやエッジといったグラフ構造にすることで、関連する情報を結びつけます。
例:「日本の首都は東京である」
graph LR
日本 -->|首都| 東京
- トリプル: 日本、首都、東京
- ノード: 日本、東京
- エッジ: 首都
この構造により、前述のRAGの課題である「関係するものを取り出しにくい」の解決が期待できます。
ナレッジグラフとRAG組み合わせて回答精度を上げることへの期待は高く、最近はナレッジグラフを取り扱うことに特化した「グラフDB」とその代表格であるNeo4j ⧉の動向などが改めて注目されています。一方で、存在するすべてをトリプルにしてしまうと細かすぎたりするため、主要な情報をトリプルにして、それ以外はトリプルに付随する属性情報にするとか、そのバランスをどうするかなど、設計の工夫が必要となります。最近はLLMの台頭によりトリプルの抽出をLLMに任せるようになり、GraphRAGでも用いています。またTriplex ⧉などトリプルの抽出に特化するLLMも出てきています。
そしてGraphRAGへ
ナレッジグラフ+RAG自身も十分魅力的ですが、ここにきてMicrosoftの研究チームがGraphRAGを出したことで、さらに注目が集まるようになりました。従来のRAGの課題をナレッジグラフで解決しつつ、さらにLLMが得意な「情報のまとめや要約」をうまくインデクシングに組み込むことで、ドキュメントの全体的・包括的な質問について、より詳しく正確に回答できるというものです。具体的には以下のような質問回答の強化です。
- 「〇〇の概要は?」
- 「△△の主なトピックを列挙してください」
GraphRAGの特徴的なふるまいは以下です。
- インデックス作成時
- グラフ作成時にLLMを使用し、ノードやエッジについての要約を同時に作成します。
- 近い位置にあるグラフをアルゴリズムにより検出・グループ化し、さらに要約を作成します。GraphRAGではこのグループの単位を「コミュニティ」と呼び、コミュニティの要約を「コミュニティレポート」と呼んでいます。
- 検索時
- インデックス時に作った要約を頼りに従来のRAGのように質問に近い対象を探します2。この対象がGraphRAGではノードやコミュニティとなります。
- 全体把握を目的とした検索は、コミュニティを探し周って回答を作っていきます(グローバル検索)。
- 特定の話題を探索する検索は、ナレッジグラフを使って関連するエッジや元となるテキストを探していきます(ローカル検索)。
ナレッジグラフにおけるノードやエッジに付随する情報をどうデータ構造にするかと言う課題も、要約テキストという形で付与することにより、厳密な構造を豊富な表現力で補うことができます。
GraphRAGを動作させる
GraphRAGを実際に動作させてみましょう。素早く動作させる方法は以下の2通りがあります。
- graphrag ⧉のCLIで動かす方法
- GraphRAG Accelerator ⧉を使い、Azure上にデプロイしてエンドポイントから動かす方法
他にも(本ブログでは扱いませんが)ライブラリをAPIから呼び出す方法が examples ⧉やexamples_notebooks ⧉にあります。
graphragのCLIによる実行
公式ドキュメントのGet Started ⧉に沿って実行します。
事前準備
graphragのリポジトリ ⧉からプロジェクトをクローンします。graphragのプロジェクト直下でgraphrag実行用のフォルダを作成します。
mkdir -p ./ragtest/inputinputフォルダではgraphragの検索対象とするデータを配置します。
リポジトリでは英語の記事や小説を題材にしていますが、ここでは日本のRAGの検証でよく使われる歴史上の人物の情報(いわゆる「武将シリーズ」)をWikipediaから取得して使います。
- 織田信長
- 明智光秀
- 豊臣秀吉
- 徳川家康
情報の取得はこの記事 ⧉を参考にしました。別リポジトリのGraphRAG Acceleratorにあるget-wiki-articles.py ⧉の内容を改変して取得します。
後述しますが、GraphRAGは大量のLLMのトークンを消費します。動作確認だけなら少量のデータから始めた方が良いでしょう。
作業環境の作成
以下のコマンドで作業環境ファイル群を生成します。いくつかのデフォルトプロンプトや環境設定ファイルが作られます。
python -m graphrag.index --init --root .作成された設定ファイルsettings.yamlにLLMのエンドポイントやモデルを設定していきます。
デフォルトプロンプトはpromptsフォルダにテキスト形式で作成されます。GraphRAGでは、入力情報に合わせてプロンプトをチューニングすることを強く推奨しています。手動でファイルを編集するほか、コマンド実行によりある程度自動で補正できます。ただし完全ではないので手作業の補正は必要です。日本語対応もここで指定できます。
# input の内容を元にアレンジし、日本語対応python -m graphrag.prompt_tune --root . --language Japanese武将シリーズの情報を置いて上記コマンドを実行すると、プロンプトにhistorical_figure(歴史上の人物)やbattle(戦い)という文言が現れ、チューニングされたことが分かります。
...
-Steps-
1. Identify all entities. For each identified entity, extract the following information:
- entity_name: Name of the entity, capitalized
- entity_type: One of the following types: [historical_figure, event, battle, political_maneuver, dynasty, title, region, policy, cultural_development, alliance]
インデックスの作成
graphragのプロジェクト上で以下のコマンドを実行して入力データに対するインデックス処理を実行します。
python -m graphrag.index --root .outputフォルダにインデックスが生成されます。
動作確認
動作確認をするため、CLIから任意のクエリを指定し検索を実行します。graphragでは検索方法が、前述の「ローカルサーチ」と「グローバルサーチ」の2種類に分けられており、CLIではオプションで指定します。
グローバルサーチ
実行コマンドです。
python -m graphrag.query \--root . \--method global \"この時代の日本の統一過程において、武将たちはそれぞれどのような役割を果たしましたか?"実行結果です。
SUCCESS: Global Search Response: ### 日本の統一過程における主要な武将たちの役割
日本の戦国時代から江戸時代にかけての統一過程において、複数の武将たちが重要な役割を果たしました。以下に、主要な武将たちの役割とその影響をまとめます。
#### 織田信長 織田信長は、戦国時代において天下統一を目指した大名であり、数々の戦闘や政治的戦略を通じて権力を拡大しました。彼は桶狭間の戦いで今川義元を撃破し、松永久秀の反乱を鎮圧するなどして勢力を強化しました [Data: Reports (233, 161, 260, +more)]。信長の政策や戦略は後の豊臣秀吉や徳川家康に大きな影響を与え、彼の死後もその影響力は続きました [Data: Reports (227, 267)]。
#### 豊臣秀吉 豊臣秀吉は、信長の死後に権力を掌握し、豊臣政権を確立しました。彼の施策には、全国的な土地調査である太閤検地や、農民の収穫高に基づいて税を課す石高制の導入が含まれ、これらは日本の社会構造に大きな影響を与えました [Data: Reports (266, 125, 75, +more)]。また、秀吉は朝鮮出兵を行い、国際的な軍事行動を展開することで豊臣政権の維持と強化に努めました [Data: Reports (199, 126)]。
#### 徳川家康 徳川家康は、関ヶ原の戦いで東軍を指揮し、勝利を収めることで江戸幕府を樹立する基盤を築きました [Data: Reports (247, 43, 102, +more)]。彼の戦略的な指導力は日本の統一に大きく寄与し、江戸幕府の設立へとつながり、約260年にわたる平和な江戸時代をもたらしました [Data: Reports (193, 103, 107)]。
#### 明智光秀 明智光秀は織田信長の家臣として仕えましたが、1582年に本能寺の変で信長に対して反乱を起こしました。この事件は日本の歴史における重要な転換点となり、信長の死後の権力闘争に大きな影響を与えました [Data: Reports (132, 92, 121, +more)]。
#### 武田信玄と上杉謙信 武田信玄は戦国時代の有力な大名であり、徳川家康との対立を通じて家康の軍事的な成長に影響を与えました [Data: Reports (217, 64)]。一方、上杉謙信は信玄と敵対する大名として知られ、特にその軍事力は非常に強力でした。彼の戦術は後の時代にも影響を与えました [Data: Reports (217, 262)]。
### 結論 これらの武将たちは、それぞれの戦略や政策を通じて日本の統一過程に大きな影響を与えました。織田信長の革新的な政策と軍事的成功、豊臣秀吉の全国的な施策と国際的な軍事行動、徳川家康の戦略的な指導力と江戸幕府の設立、明智光秀の反乱、そして武田信玄と上杉謙信の軍事的対立は、戦国時代から江戸時代にかけての日本の歴史を形作る重要な要素となりました。
質問に武将の名前は一つも上げてなくても、このような網羅的な結果がでるのが、GraphRAGの強みです。
ローカルサーチ
実行コマンドです。
python -m graphrag.query \--root . \--method local \"キンカン頭に討たれた殿の仇を討った人はその後色々禁止したようですが?"実行結果です。
SUCCESS: Local Search Response: # キンカン頭に討たれた殿の仇を討った人のその後
## 信長と光秀の関係
織田信長は、家臣である明智光秀を「キンカ頭」と呼び、満座の中で侮辱することがありました。このような非情な扱いが、光秀の反乱の一因とされています [Data: Relationships (562)]. 光秀は信長の命令で比叡山焼き討ちを実行し、その武功を上げましたが [Data: Relationships (173, 4)], 最終的には本能寺の変で信長に反旗を翻し、信長を討ちました [Data: 信長とその時代の重要な関係 (20)]。
## 豊臣秀吉の政策
信長の死後、豊臣秀吉が権力を掌握し、日本の統一を進めました。秀吉は信長の政策を引き継ぎつつも、自身の政権を強化するためにいくつかの重要な政策を実施しました。例えば、秀吉はバテレン追放令を発布し、キリスト教徒の追放を目指しました [Data: Relationships (1781, 2340, 2339, 2338)]. また、人身売買を禁止する命令を出しましたが、実際には追放令にその文が削除されていたこともあります [Data: Relationships (1782)]。
## 徳川家康の政策
秀吉の死後、徳川家康が権力を握り、江戸幕府を開きました。家康もまた、キリスト教の布教を禁止する禁教令を発布し、国内の安定を図りました [Data: Relationships (1417, 2250, 2251, 2252, 2253)]. 家康はまた、殉死を嫌い、これを禁じる政策を実施しました [Data: Relationships (1437)]。
## まとめ
信長を討った光秀の後を継いだ秀吉と家康は、それぞれの時代において重要な政策を実施し、日本の歴史に大きな影響を与えました。特にキリスト教の布教禁止や人身売買の禁止などの政策は、彼らの政権の安定と権力強化を目的としたものでした。
「キンカン頭→明智光秀→謀反→織田信長→仇討ち→豊臣秀吉→バレテン追放」を期待した質問でしたが、ちゃんと出てくれました!ナレッジグラフ素晴らしいですね。
GraphRAG Accelerator
前述のGraphRAGをAzureで簡単に動かすためのツールとして、GraphRAG Acceleratorが存在します。GraphRAG AcceleratorにはGraphRAGの動作に必要なリソース一式をAzure上にデプロイするためのIaCツールが用意されており、手順に従うだけで簡単に試すことが可能です。
GraphRAG Acceleratorのリポジトリ ⧉からプロジェクトをクローンし、DEPLOYMENT-GUIDE.md ⧉の内容に従い、Azure上に環境を構築します。インデクシングやグローバルまたはローカル検索の手順は1-Quickstart.ipynb ⧉にまとめられています。ノートブックでは以下を実演できます。
- インデクシングファイルをBlobストレージにアップロード
- WebAPI経由でインデックスを作成し知識グラフを構築
- インデクシングが完了後、グローバルクエリとローカルクエリの2種類の検索をAPI経由で実行
GraphRAGの内部構造
内部構造を見ることでGraphRAGに関する理解がより深まります。先ほどの「武将シリーズ」データのインデックスを見て行きます。
まず、今回説明するインデックスのデータ構造を図にしました。
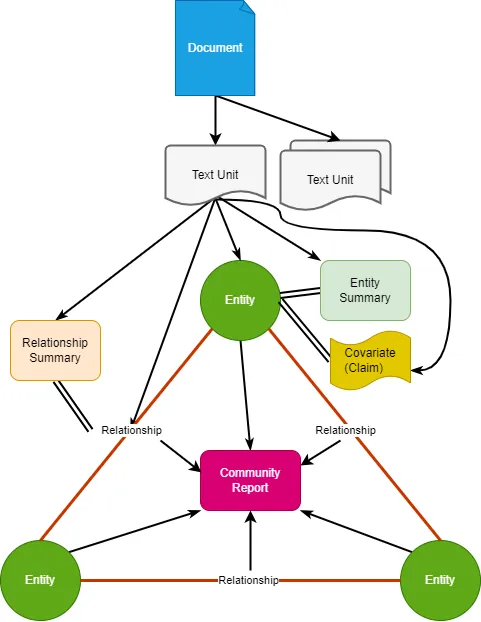
RAGのDBとしてみても、ナレッジグラフとしてみても、あまりなじみのない言葉が出てきます。Community Report, Covariateなど…。
このインデックスは先ほど説明したインデックスの作成のコマンド実行で作成されます。実行時のログを見やすいように改行しました。
15:29:38,638 graphrag.index.workflows.load INFO Workflow Run Order: [ 'create_base_text_units', 'create_base_extracted_entities', 'create_summarized_entities', 'create_base_entity_graph', 'create_final_entities', 'create_final_nodes', 'create_final_communities', 'join_text_units_to_entity_ids', 'create_final_relationships', 'join_text_units_to_relationship_ids', 'create_final_community_reports', 'create_final_text_units', 'create_base_documents', 'create_final_documents']インデックスデータはParquet形式でoutputフォルダに出力されます。ファイル名に _final_ を含むファイルが最終成果物です。
主だったものについて、実際にParquetファイルを覗いていきましょう。全体の図を部分的に切り取りながら説明していきます。Parquet可視化には、VSCodeではMicrosoftが作成したData Wrangler ⧉を使うと便利で、以降の説明でも使用します。
テキストユニット(create_final_text_units)
ドキュメントのテキストを一定サイズのチャンクに分割したものがここに格納されます。
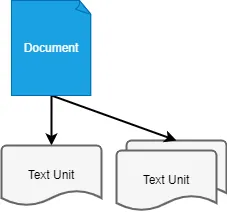
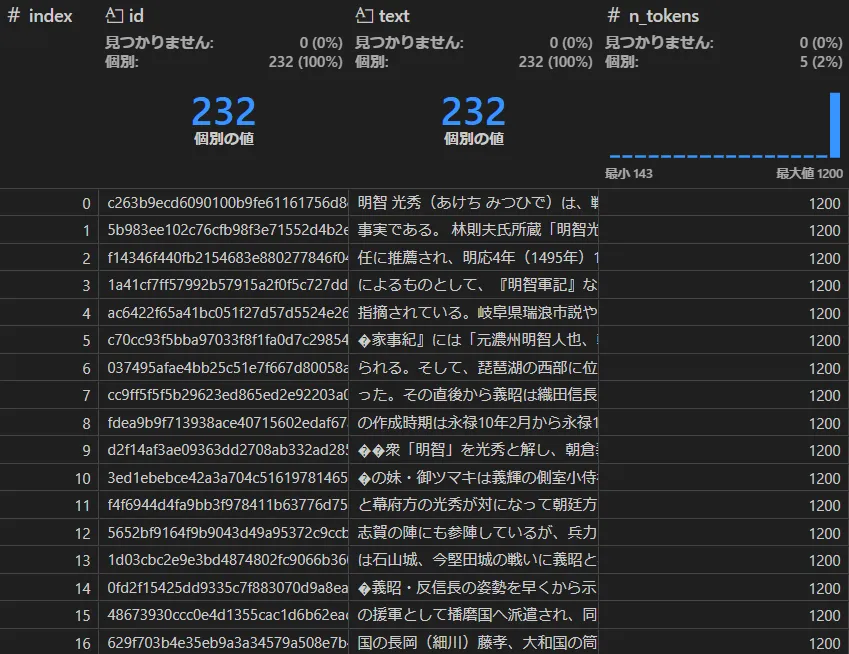
テキストチャンクと結びつくものとして、後述する、「エンティティ(Entity)」、「関係(Relationship)」、「共変量(Covariate)」の情報もあります。ハルシネーション防止のために元情報との関連を保持することは、RAGを含めLLMの運用において大切です。
エンティティ(create_final_entities)
テキストチャンクを、LLMで解析してトリプルを取り出します。LLMに渡すプロンプトはデフォルトで、GraphRAGの初期化コマンドで作成する(内容はここを参照 ⧉)entity_extraction.txtを使います。
トリプルのうち、主にSubject, Objectに相当するものが、Entityとしてここに作られます。
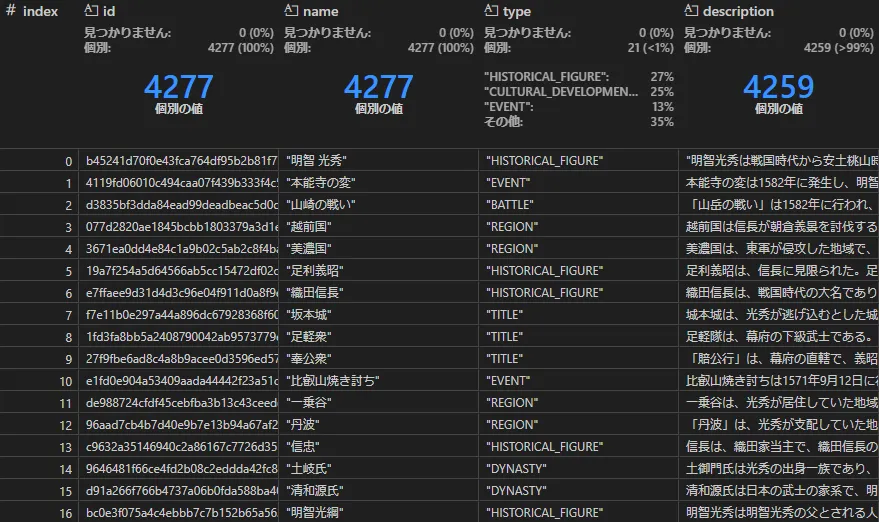
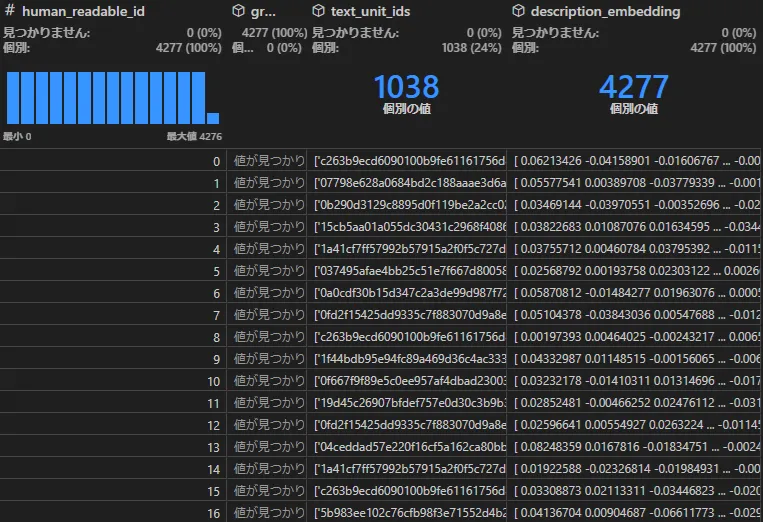
GraphRAGを特徴づけるものとして、エンティティの要約とそのテキストの埋め込み(description, description_embedding)があります。要約や埋め込みはLLMのAPI呼び出しで作成します。以下は「本能寺の変」エンティティのdescriptionです。要約列は他にも色々な場面で出てきます。
本能寺の変は、1582年に起こった歴史的な出来事である。この事件は、明智光秀が信長に対して反乱を起こしたことに起因し、信長の死をもたらした。信長の死は、彼の生涯の終焉を意味し、彼の名声を歴史に刻むこととなった。この事件は、信長の権力の変遷に大きな影響を与え、彼の後継者たちにとっても重要な転換点となった。
本能寺の変は、信長が明智光秀に裏切られた結果として発生し、光秀は信長の死後、彼の名を歴史に刻むことを意図していた。信長の死は、彼の権力基盤に大きな影響を与え、彼の後継者たちの運命にも影響を及ぼした。この事件は、信長の死後の日本の歴史においても重要な出来事として位置づけられている。
また、本能寺の変は、信長の死を引き起こした重要な事件であり、彼の権力の変遷に大きな影響を与えた。信長の死は、彼の後継者たちにとっても重要な転換点となり、彼の名声を歴史に刻むこととなった。この事件は、信長の生涯の終焉を意味し、彼の名を歴史に刻むこととなった。
エンティティで問題になるのが、自然言語の文章に含まれるノイズにより発生する重複データです。
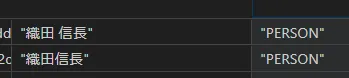
ナレッジグラフの品質を良くするためにはマージ処理が必要とされます。GraphRAGでもマージ処理を想定した設定はありますが、v0.2ではまだ実装されてないようです。ただ、GraphRAGの性質上、ある程度はマージ処理は吸収することができます。これについては後述します。
ノード(create_final_nodes)
ノードはエンティティと似ており紛らわしいです。イメージとしてはノードは「エンティティを図に書けるぐらいまで実態化したもの」という感じです。
graph TD;
subgraph 概念
Entity[エンティティ]
Relation[リレーション]
end
subgraph 実態
Node[ノード]
Edge[エッジ]
end
Entity -->|インスタンス化| Node
Relation -->|インスタンス化| Edge
エンティティには無いdegree(次数=他のノードとの接続数)や、メタ属性として#x, #yの座標系があります。
リレーション(create_final_relationships)
ノードとノードをつなぐ線(エッジ)の情報を格納します。
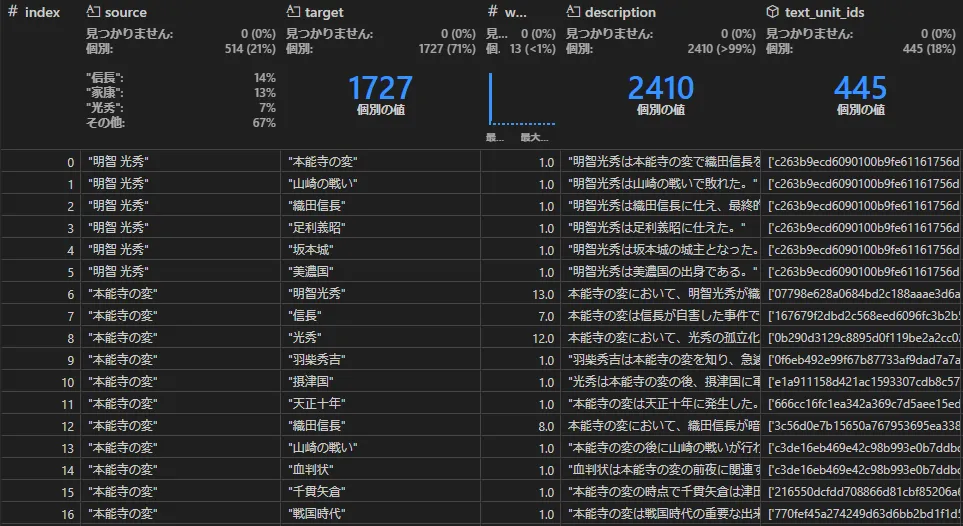
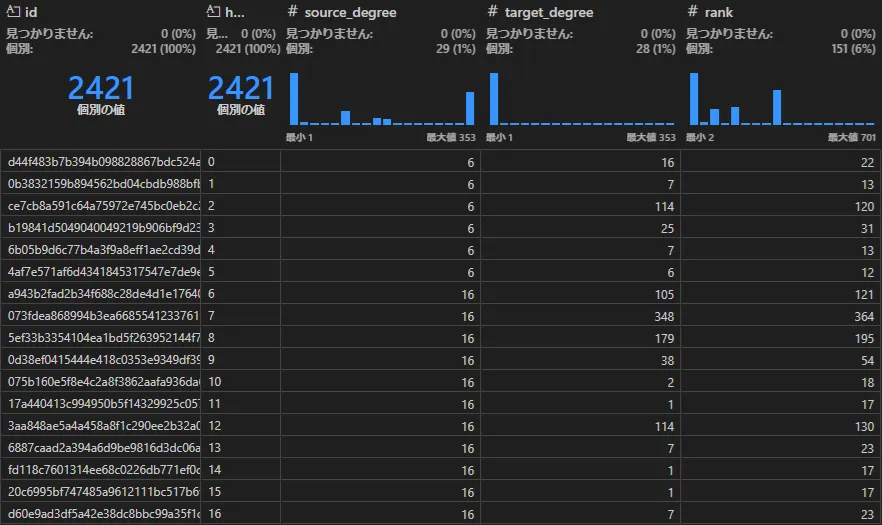
エッジにもdescription属性があり、LLMによって要約が作られる徹底っぷりです。rank属性の値は、隣接する2つのノードのdegreeの合計値としています。「徳川家康と豊臣秀吉」のように強いもの同志を結びつける関係は最強ということです。
コミュニティ(create_final_communities, create_final_community_reports)
GraphRAGのキモである「コミュニティ」です。具体的に何を作るか見てみましょう。
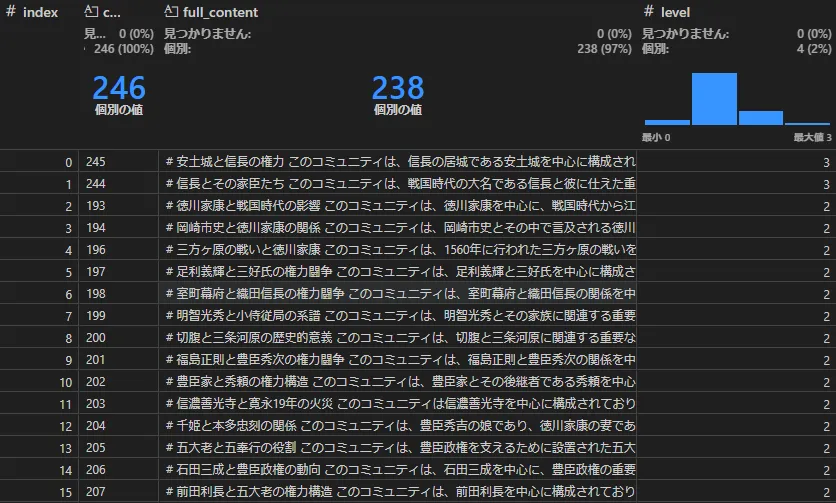
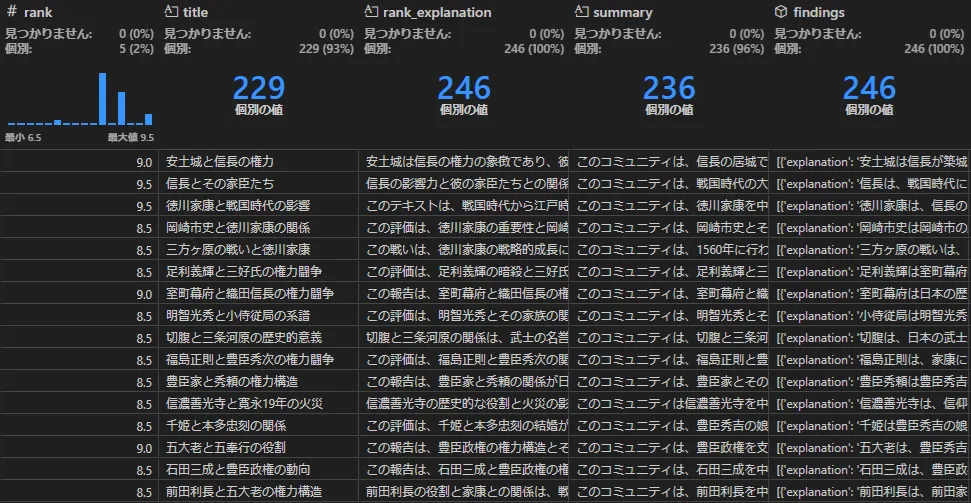
一つの話題について、タイトルと詳しい内容が一つのテキストにまとまっているのが見えます。
# 明智光秀と織田信長の歴史的関係
このコミュニティは、明智光秀と織田信長の複雑な関係を中心に構成されており、光秀の忠誠、裏切り、軍事的成功、そして本能寺の変が重要な要素となっています。光秀の行動は信長の権力に大きな影響を与え、> 戦国時代の歴史において決定的な役割を果たしました。
## 光秀の忠誠と裏切りの歴史
明智光秀は織田信長の家臣として忠誠を誓い、数々の軍事行動を通じて信長の権力を支えました。しかし、最終的には本能寺の変で信長を裏切ることになります。この複雑な関係は、信長の政策に従いながらも、光秀の内心の葛藤を反映しています。信長は光秀の軍功を評価し、彼を重用していましたが、信長の非情な行動が光秀の反発を招く結果となりました。[Data: Relationships (289, 488, 18)]
## 丹波攻めの軍事的成功 ...
GraphRAGではLeiden ⧉というアルゴリズムを使い、類似したノードをコミュニティという単位にクラスタリングします。集めたノード全体についてLLMにより要約を作成しておき、後の検索で使うことで、従来のRAGでできなかった「全体把握」ができる、というからくりです。どことなく「DBであらかじめ導出項目を作っておき処理速度を上げる」に似ていますね。当然ながら導出項目における課題と同じく「データ更新時にはコミュニティレポートも更新」もついて回ります。ついでにfinding列で、Entity, Relationshipの導出元も保持しています。
[{'explanation': '織田信長は足利義昭を奉じて上洛し、後に義昭を追放して独自の中央政権を確立しました。彼の政権は畿内を中心に展開され、戦国時代の終焉と中世社会の最終段階を象徴するものでした。信長の政策は革新的とみなされていましたが、近年の歴史学界ではその前時代性も指摘されています。 [records: Entities (6, 24, 65, 66, 70, 74, 75), Relationships (22, 24, 29, 30, 33, 39, 40)]', 'summary': '織田信長の中央政権確立'} ]
コミュニティは階層構造を持っており、インデクシング時に参照先の内部のエンティティを見て、似ている話題はさらにサブコミュニティとして作成、といったことをしています。階層はlevel列で示されてます。なおコミュニティのParquet内部の参照先は、ノードやエッジが見当たらずリレーションシップだけですが、それさえあれば隣接ノードもまとめて取れるからと考えられます。
コミュニティを作ることによる副次的な利点として、エンティティの章で述べた「同じ意味を持つエンティティが重複して存在する」問題を多少は解決するようです。コミュニティの構築過程において意味的に近いものが集まるため、実質マージと同じような処理となり、比較的ノイズに強い構造となることが期待できます。
共変量/クレーム(create_final_covariates)
なにやら分かりづらい言葉が出てきました。
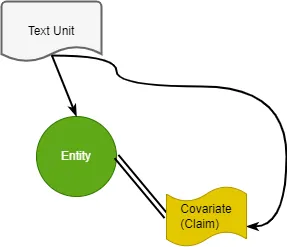
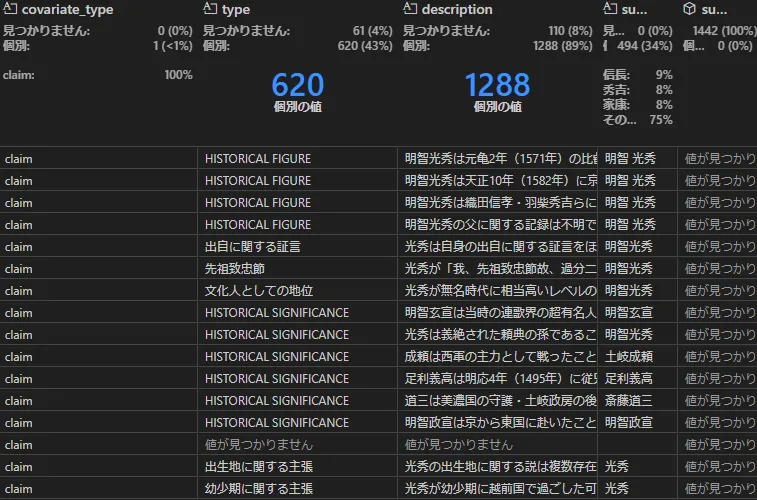
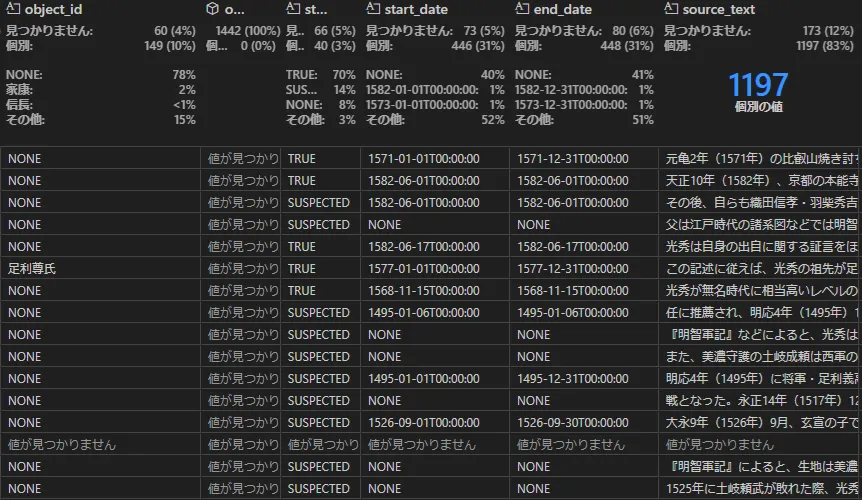
Covariateは日本語で「共変量」と訳され、ノードやエッジなどグラフの要素に関連する性質や特徴を追加的に示すパラメータのようなものです。付加パラメータの一つにクレームがあり、これは事実や状況を付加的に説明するという意味を持ちます。
まだ分かりにくいですね。クレームを抽出するプロンプトの中に「クレームを抽出する例」のFew-Shotプロンプトが書かれているので、それを見てみましょう。
例1: エンティティ仕様: 組織 クレームの説明: エンティティに関連する危険信号 本文:2022年1月10日の記事によると、A社は政府機関Bが公表した複数の公共入札に参加した際に談合を行ったとして罰金を科せられた。この会社は2015年に汚職行為に関与した疑いのあるC氏が所有している。
出力:(A社{tuple_delimiter}政府機関B{tuple_delimiter}反競争的行為{tuple_delimiter}TRUE{tuple_delimiter}2022-01-10T00:00:00{tuple_delimiter}> 2022-01-10T00:00:00{tuple_delimiter}2022/01/10に公開された記事によると、A社は政府機関Bが公開した複数の公共入札で談合を行ったとして罰金を科せられ、反競争的行為に関与していたことが判明しました{tuple_delimiter}2022/01/10に公開された記事によると、A社は政府機関Bが公開した複数の公共入札に参加した際に談合を行ったとして罰金を科せられました。) {補完区切り文字}
注目するのは「時制」です。ファイルにもstart_date, end_dateが設けられており、事象の発生を時系列に記録しようという意図が見えます。ノードやエッジに直接属性を設けるのと何が異なるかと考えると「グラフに対して時制などの付加的要素」といった位置づけから、以下のような整理ができそうです。
- 構造(静的):ノードやエッジ
- イベント(動的):共変量/クレーム
問い合わせ時の活用方法としては「〇年以降の…」といった絞り込みに使用することになるでしょう。
以上、主要なインデックス構造を説明しました。実運用ではこのファイルを検索しやすいプラットフォームにロードすることになるでしょう。AzureにデプロイするGraphRAG Acceleratorにおけるデータの配置方法についても、いずれ解析して説明したいと思います。
振る舞い
ここではインデックスを使った検索処理の振る舞いを見て行きます。
動作確認にてグローバルサーチ、ローカルサーチを動かした結果について記載しましたが、実際にGraphRAGがインデクシングとクエリーを受けて、各サーチ方法でどのように応答を返しているのかについて説明します。
プロンプトテンプレート
グローバルサーチ、ローカルサーチではそれぞれLLMに渡すプロンプトのテンプレートが用意されています。ユーザが入力したクエリーと、会話履歴の2つを用いて、テンプレートの内容をフォーマットし、LLMに渡すためのプロンプトが作成されています。グローバルサーチでは使用するテンプレートが2つ用意されています。詳細については下記の「グローバルサーチ」に記載します。
グローバルサーチの処理の流れ
グローバルサーチの処理の流れは下記となります。(参考:GraphRAG -> Query -> Global Search ⧉)
- ユーザが入力したクエリーと会話内容を取り出す。
ベクトル検索で、意味的に近いコミュニティレポートを取り出す。(2024/8/21修正:グローバルサーチではベクトル検索は実行しません)- コミュニティレポートをテキストチャンクに分割し、それを元にして質問に対する中間応答と重要性を示すスコアを、並列で出力させる(map)。
- 中間回答の中で最も重要なポイント(スコアの高いもの)を選び出し、LLMを使って統合する(reduce)。
- 最終的な応答を返す。
ローカルサーチの処理の流れ
ローカルサーチの処理の流れは下記となります。(参考:GraphRAG -> Query -> Local Search ⧉)
- ユーザが入力したクエリーと会話内容を取り出す。
- ベクトル検索で、意味的に近いエンティティを抽出する。
- エンティティから、ナレッジグラフを用いて関連するエンティティ、関係性、共変量の候補を抽出する。関連するテキストのチャンク情報から別のエンティティを取り出す。
- 候補となるテキストのチャンク情報、エンティティ、関係性、共変量に対し、それぞれ優先付けする。
- 優先度付けされた情報をもとに、LLMに回答作成を依頼する。
- 最終的な応答を返す。
実用に向けての考察と現時点の課題
GraphRAGの実用性について考察してみます。
プロダクトとしての考察
graphragリポジトリのコードを見るに、まだ実験段階ではあるものの、実用的なRAG構築に必要とされるカスタマイズ可能なワークフローの仕組みや、最初からチューニング前提なプロンプトテンプレートがコードと独立して配置されるなど柔軟性は高いです。以下、主なアーキテクチャ構成要素です。
- インデクシングのパイプラインは、MicrosoftのOSSであるDataShaper ⧉というライブラリを使用
- パイプラインのデータの受け渡しは、Pandas DataFrame を使用
- 表構造の Pandas DataFrame とグラフ構造のナレッジグラフとの相性が当初気になりましたが、Microsoftが主張するように ⧉、Pythonのデータ処理で良く使われている豊富なエコシステムを活用できる点は魅力です。
- Graph操作ライブラリとしてNetworkX ⧉を使用
- LeidenといったGraphアルゴリズムライブラリとしてgraspologic ⧉を使用
ユースケースについて考察
まず、従来の検索エンジンやベクトル検索を用いたRAGの得意とする分野、キーワード検索やセマンティック検索を用いた直接的な質問(例:「〇〇について教えてください」)の回答に対しては、GraphRAGの論文内でもナイーブRAGの方が優れているとされています。 ⧉後述するコストとの兼ね合いから、そのようなQAの使い方をするユースケースでは従来のRAGが良い結果となりそうです。
一方、RAGへ求める期待をもっと広く「LLMのモデルが持つ能力の補完」とする場合があります。生成AIの豊富な知識をもって人間が理解を深めることを目的としたもので、調べたいことが明確な検索とは趣が異なります。理解を深める行為においては、以下のように概念的に物事を理解していく、センスメイキングというプロセスが大切とされています。
- 水平展開により関連する事象を発見すること
- 共通のパターンを認識すること
- 背景の文脈を理解すること
- 多角的な視点に気づくこと
このような調査はナレッジグラフを発展させたGraphRAGの得意とするところです。つまりは「人手不足の領域にて、初学者が生成AIを活用して専門的なドメイン知識を獲得していく」といったようなユースケースがフィットしそうです。また、関連を辿ったり概要から詳細への深堀など、ドリルダウンのような探索を行う調査のユースケースにも有効に思えます。
課題
GraphRAGのリポジトリの位置づけは2024年8月時点において、ナレッジグラフ活用論を紹介するリファレンス実装でありMicrosoftが品質を保証するものではないとされています。また、機能的にもまだ未実装な部分や改良が必要な部分、本質的な課題もあります。主だったものを列挙します。
- エンティティ重複: 解消のための設定の定義は存在するものの3、まだ実装はされていないようです。
- ドキュメントの追加・更新・削除: Github Issue ⧉で話題に上がっていますがまだ実装されてはいません。ただしキャッシュをうまく使って既に処理済みのものを効率化する仕組みは有ります。
- 時制の問い合わせなど: 時制は前述のCovariateで述べたようにインデックス内に情報はありますが、それを質問から取り出す方法については未実装です。これによらず質問に対してクエリを切り替える実装、例えば質問の内容からローカル・グローバルの検索を判別すると言った実装もできそうではありますが、それはGraphRAGライブラリの呼び出し側で工夫しましょうということでしょう。
- 構造データ: ナレッジグラフの挑戦はテキストなどの非構造データをグラフ構造に落とし込むことでありGraphRAGの売りでもあるのですが、そもそも最初からある程度整理された構造データをナレッジグラフ化すればより便利と考えられます。GraphRAGはテキストのほかCSVにも対応しており、今後JSONやXML対応などができれば、稼働システムのJSONのexportデータを読み込むといったことが可能となり、より利便性が高まるでしょう。
コストや処理速度の課題
GraphRAGがリリースされて以降、よく聞かれる課題はトークン量にまつわるコストです。武将シリーズのテキストファイルの合計は、約21万文字(600KB)程ですが、どれだけのエンティティやリレーション、要約が作成されるかの概算を以下に示します。環境はAzure OpenAI上のGPT-4o-miniで実施しています。
- インデックスの生成量
parquetファイル 行数 テキストユニット 230 エンティティ 3,600 ノード 3,600 リレーション 2,480 コミュニティ 270 クレーム 1,300
(2024/8/21修正:ノードの数に誤りがあり修正しました)
- トークン量の合計:GPT-4o miniは約560万トークン(入力:440万、出力120万)、embedは約26万トークン。 GPT-4o miniだと約200円といったところです。(2024/8/21 金額誤りを修正しました)
- APIリクエスト数:GPT-4o miniは約2,200回、埋め込み用のembeddingは230回
処理時間については、実行する環境におけるレートリミットによるのであくまで一例ですが、
- インデクシング作成には、30分~1時間程度かかりました。
- 問い合わせは、グローバルサーチ1分半、ローカルサーチは20秒ほどでした。
コストが気になったりやレートリミットが発生するような状況であれば、今回のようにGPT-4o-miniのような低コストのLLMを使う方法や、ローカルLLMを用いて解決する方法が考えられます。またTriplex ⧉のように、ローカルLLMでトリプルを効率的に抽出する専用のLLMと組み合わせる方法は有効と思われます。ローカルLLMについては対象となるドメインの知識をチューニングすれば、コストやトリプルの抽出精度を同時に向上できるかもしれません。いずれにせよトリプルの抽出や要約の精度がどれほど許容できるかの評価は必要です。
また、Neo4j社のテックブログ ⧉に書かれているGraphRAGの解析を見ると、子が一つだけのコミュニティ階層による要約など、全部に要約を適用するのは冗長 ⧉という意見もあり、今後の処理の効率化が期待されます。
さいごに
GraphRAGについて説明しました。まだ発展途上ですが次世代のRAGとして注目するにふさわしいポテンシャルは持っていると感じます。今後は実業務に適用を試みつつ、コストなどの課題をどのように克服したかについて情報展開できればと考えます。
参考文献
- GraphRAGのドキュメントサイト ⧉: ブログや論文やGitHubはここから辿れます。
- Implementing ‘From Local to Global’ GraphRAG with Neo4j and LangChain: Constructing the Graph ⧉: Neo4j社によるGraphRAGの考察とNeo4jによる実装例の紹介。異なる視点からの考察として参考になりました。
- Triplex — SOTA LLM for Knowledge Graph Construction ⧉: ナレッジグラフのトリプル抽出に特化したLLMとそれを用いたR2R RAG engine ⧉ の紹介
- GraphRAG 第一弾 ~ Azureで動かしてみる ~ ⧉: 武将シリーズの取り出し方の参考にさせていただきました。
- LLMによるナレッジグラフの作成とハイブリッド検索 + RAG - ゆめふく ⧉: ナレッジグラフによるRAGを、LangChainとNeo4Jにより検証した記事。今後この組み合わせも流行りそうですね。
- AIのRAGが「GraphRAG」に進化! Microsoftが公開したツールでその性能を試す - Internet Watch) ⧉: GraphRAGについて図やプロンプト例を用いて分かりやすく説明されています。
Footnotes
記事の執筆にあたっては情報の正確性に努めておりますが、掲載されている文章やソースコード、設定ファイル等の内容について、完全な正確性や安全性を保証するものではありません。活用される際は、必ず公式ドキュメント等をご自身で確認のうえご判断ください。
