

[!] この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは。経営企画本部AI推進室の鏡味、窪田です。今回も前々回、前回に引き続き、Microsoft GraphRAG ⧉の記事です。
今回は、GraphRAGを実運用に使えるようにするため機能強化による性能向上、およびRAGの評価の仕組みについて書きました。トピックは以下の通りです。
- GraphRAGの性能向上: RAG UIツールのkotaemon ⧉の機能強化によるもの
- Azure AI Document Intelligence ⧉の導入
- Reasoning methodの導入
- GraphRAGの性能評価: Allganize RAG Leaderboard ⧉のデータセットによるもの
なお、この記事のGraphRAGは、Microsoftが発表したGraphRAG ⧉ を示します。一般的なナレッジグラフとRAGを組み合わせた技術の記載は「Graph RAG技術」と書いて区別します。
GraphRAGについては、当社のテックブログの生成AIに関する記事のほか、2024年10月31日に開催されたFindy社様主催のイベント「進化するRAGの世界 - GraphRAGと評価指標の最新動向」 ⧉の登壇時の資料がSpeakerDeckにあります ⧉ので併せてご参照ください。
背景
生成AIに足りない知識を外部情報で補うRAG技術と、手法の一つであるGraphRAGへの高い期待は続いています。また、最近はMicrosoft以外でもGraph RAG技術を用いた実装も増えてきました。
一方、GraphRAGそれ自体はライブラリとCLIの形で提供されていますが、実運用においては機能的に不足気味で、アプリケーションレイヤーにて足りない部分を補う必要があります。また性能についても向上の余地があります。加えて実運用に向けては性能評価と改善というサイクルを実現することも大切です。
当社では、RAG UIツールであるkotaemonを用いて、上記の課題解決に取り組んでおり、その一部を紹介します。
全体構成
以下は今回のRAG評価の全体像です。外部知識であるPDF資料をインデックス化し、質問から回答を生成して、その内容をLLM-as-a-Judgeで評価する流れです。
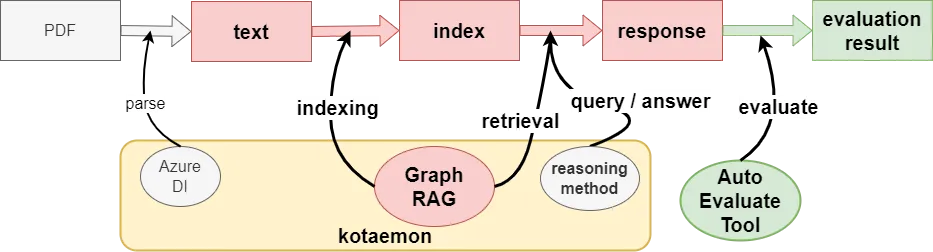
RAG評価環境の構成要素である、kotaemon、GraphRAG、その他の要素について説明します。
GraphRAG
最近、正式バージョンであるv1.0がリリースされました ⧉。インデクシングの効率化など機能拡充がされており、今後の発展も見越してこのバージョンを用います。
kotaemon
Cinnamon社がApache-2.0 licenseで公開している、OSSのRAGツールです。 https://github.com/Cinnamon/kotaemon ⧉
リッチなUIやインデクシング・推論処理についてさまざまなRAG技術が具備されており、加えてGraphRAG・nano-graphrag ⧉・LightRAG ⧉といった最新のGraph RAG技術もいち早く取り入れています。
(画像はkotaemonのGitHubより引用)

GraphRAGのアプリケーションレイヤーについて、MicrosoftはGraphRAG Accelerator ⧉というソリューションを出していますが、AzureのAKS上で動かすなど、若干大がかりです。
一方、kotaemonは比較的コンパクトな実装でアプリケーション部分を実現でき、後述しますがGraphRAGの機能の一部を置き換えて強化しています。具体的にkotaemonにGraphRAGがどのように組み込まれているかについては、後の方で詳しく説明します。
今回のバージョンはv0.9.11を使用します。
Allganize RAG Leaderboard
Allganize社がMIT Licenseで公開しているRAG評価のリーダーボードです。さまざまなRAGソリューションのベンチマーク、データセットと評価ツールが公開されています。 https://huggingface.co/datasets/allganize/RAG-Evaluation-Dataset-JA ⧉
データセットは金融やITなど業種ごとに存在し、文字だけではない表形式や画像を含んだ文書の評価も可能としています。今回はこのデータセットと、評価ツールの仕組みを参考にさせていただきました1 。
Azure AI Document Intelligence(以下 Azure DI)
Microsoftが提供している機械学習モデルを使用するOCRサービスです。 https://azure.microsoft.com/ja-jp/products/ai-services/ai-document-intelligence ⧉
リーダーボードにあるとおりRAGの性能向上のためには表形式や画像などを正確に理解できる仕組みも大切です。Azure DIは表や画像について構造を保持したまま抽出が可能です。kotaemonはAzure DI機能に対応しており、今回性能向上のために使います。
kotaemonによるGraphRAGの機能強化の仕組み
ここでは、kotaemonにGraphRAGが組み込まれることにより、どのような機能強化が行われているかを見て行きます。インデクシングと検索、それぞれにGraphRAGを機能強化する仕組みがあります。
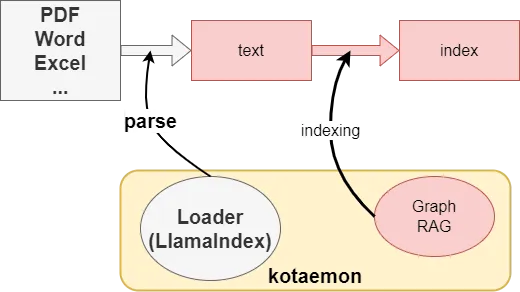
インデクシング
GraphRAGが対応しているフォーマットは現在テキスト・CSVのみで、PDFなどのフォーマットは事前にテキストに変換する必要があります。kotaemonにはLlamaIndexベースのさまざまなドキュメントローダーが用意されているため、ファイルをアップロードするだけで、対応するローダーとGraphRAGのインデクサーとを自動で連携することができます。
kotaemonとGraphRAGの連携は以下のようになります。
検索
kotaemonの検索は、外部情報の取得(Retrieval)と、それらを元にして推論する(Reasoning)処理のモジュールが分離されています。これにより以下のように処理を組み合わせることができます。
- Retrievalではインデックス(GraphRAGではナレッジグラフ)からエンティティやリレーションシップなどの関連情報を取得
- Reasoningではkotaemonに具備されている推論ロジックを使用。GraphRAGに元々備わっている推論処理は使わない
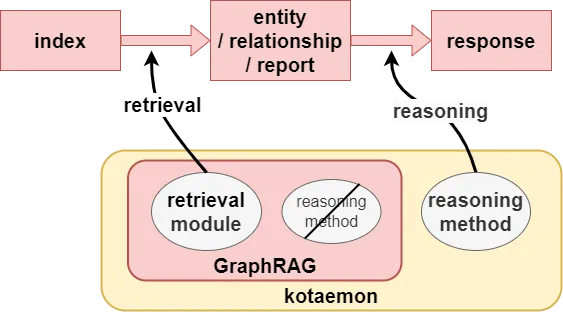
Reasoningについてもkotaemonは多くの機能を持っています。以下は一例です。
- 関連の高い結果をスコア付けして並び替え
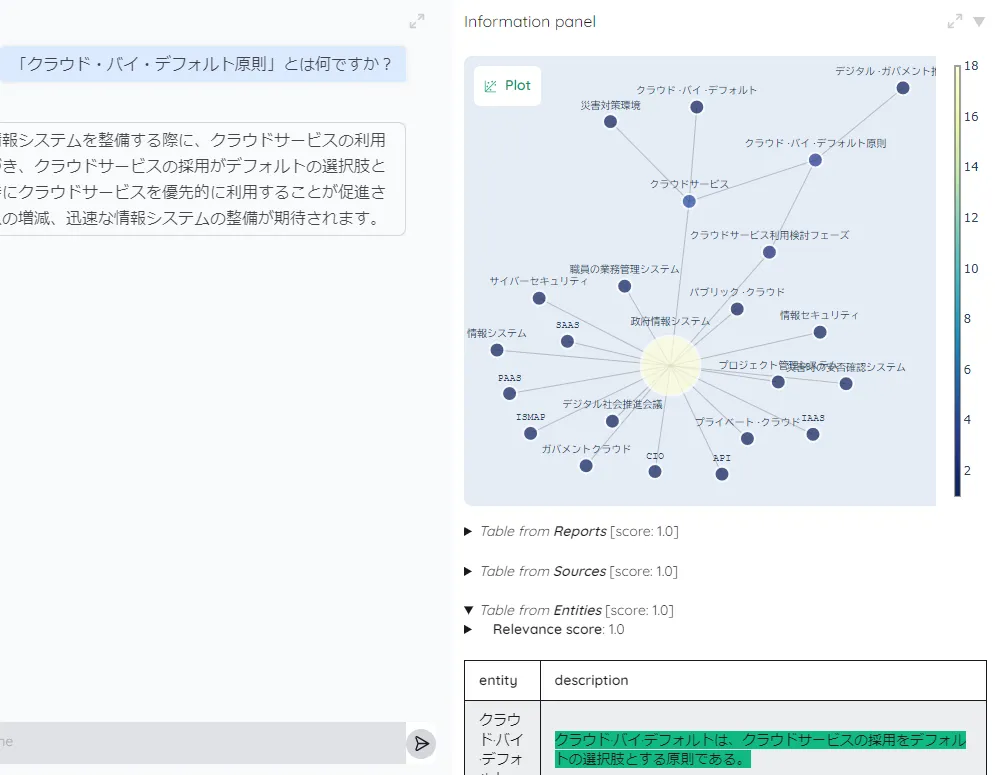
- Retrievalの結果を情報パネルに表示。エンティティやリレーションシップの表示の他、ナレッジグラフをビュー化した表示もできます。
環境構築
kotaemon
ここではWindows上のWSLで構築します。カスタマイズ重視のため、より柔軟なWithout Docker ⧉の環境構築に倣います。conda導入の手順はありますが必ずしも必要としません。
python -m venv venv. venv/bin/activatepip install -e "libs/kotaemon[all]"pip install -e "libs/ktem"パラメータ設定としては、.env.example を.envとしてコピーし、必要な設定を環境変数として定義します。
LLMは比較的小コストのgpt-4o-miniと、埋め込みにはtext-embedding-3-smallを使用します。
Azure DIにも設定をしておきます。
# settings for Azure OpenAIAZURE_OPENAI_ENDPOINT=...AZURE_OPENAI_API_KEY=...AZURE_OPENAI_CHAT_DEPLOYMENT=gpt-4o-miniAZURE_OPENAI_EMBEDDINGS_DEPLOYMENT=text-embedding-3-small
# settings for Azure DIAZURE_DI_ENDPOINT=...AZURE_DI_CREDENTIAL=...GraphRAG
執筆時点でkotaemonはv0.3を利用する想定となっていますが、今回は正式バージョンとなったv1.0を利用したいため、kotaemonにv1.0を利用するための変更が盛り込まれているPull Request承認前のbranchを使用します。 https://github.com/Cinnamon/kotaemon/pull/588 ⧉
pip install "graphrag<=1.0.1" futurekotaemonのパラメータ設定ですが、GraphRAG対応は発展途上のため、設定箇所を複数置けてしまい、かつ状況によって設定が反映されない不具合があるなど、分かりづらい状況です。現時点で最も確実な方法は、必要なパラメータを環境変数としてexportしておくことです。以下に設定方法を示します。
まず、必要なパラメータはすべて.envに記載します。
# settings for GraphRAGGRAPHRAG_API_KEY=...GRAPHRAG_LLM_MODEL=gpt-4o-miniGRAPHRAG_EMBEDDING_MODEL=text-embedding-3-small
# set to true if you want to use customized GraphRAG config file# (カスタマイズされた GraphRAG 設定ファイルを使用したい場合は true に設定します)# ここはtrueにしておきます。USE_CUSTOMIZED_GRAPHRAG_SETTING=true次に、ルートディレクトリ直下にある settings.yaml.exampleを直接編集します(違和感がありますがそのような仕様です)。そこでは .env に書いた値を参照として記入します。
llm: # .envの内容を参照 deployment_name: ${AZURE_OPENAI_CHAT_DEPLOYMENT} api_base: ${AZURE_OPENAI_ENDPOINT} ...kotaemonを起動するときには、.envに書いた値を環境変数に反映させるように、以下のコマンドを実行します。
export $(sed 's/ = /=/g' .env | grep -v '^#' | xargs) && python app.pyこのようにすると、kotaemonからGraphRAGのインデクサーを起動する時に、settings.yamlが所定の位置に配置され、環境変数もGraphRAG側に引き継がれます。
Reasoning/Evaluate tools
リーダーボードで提供されているデータセットのcsvを使い効率的に推論と評価を行うために、以下のようなスクリプトを準備しました。
インデクシング・回答生成のスクリプト
csvファイルを読み込みAPI経由でインデックス登録や推論を行うスクリプトを作りバッチ処理させます。
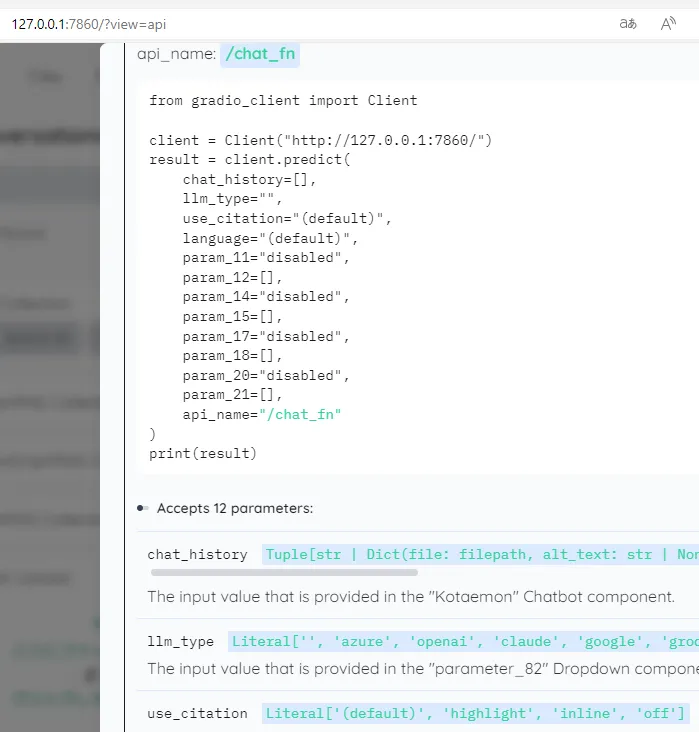
kotaemonには汎用的なAPIは用意されていませんが(提供する意向はあるようです ⧉)、UIにGradioを使っているので、GUIを操作するAPI経由で呼び出し可能です。kotaemonを表示するURLの末尾に'?view=api'でAPI仕様画面になりコード例も提示されているのでそれを流用します。
画面上の API Recorder というツールを実行させれば、実際の操作がPythonなどのコードで記録されるため、スクリプト作成も比較的容易です。
GradioのAPIを用いたコードは若干煩雑となりますが、メリットとしてパラメータを設定するだけで複数のGraph RAG技術やReasoning methodを呼び分けることができます。
評価のスクリプト
Allganize RAG Leaderboardのサイトで紹介されている評価用のnotebook ⧉を参考にcsvをバッチ処理するスクリプトを作りました。ここで説明されてる ⧉ように、複数の評価手法を混在させ公平性を保つような工夫がされています。
評価と改善を行う
評価と改善を実施します。ここからは、地道な実行、分析、改善の繰り返しです。 GraphRAGの分析については今のところツール類の環境が整っていないことは課題ですが、一部はkotaemonのUIを使うことができ、それらを活用しながら進めていきます。 実際のRAGパイプラインの処理にそって、期待した処理がされているかを見て行きます。
インデクシング
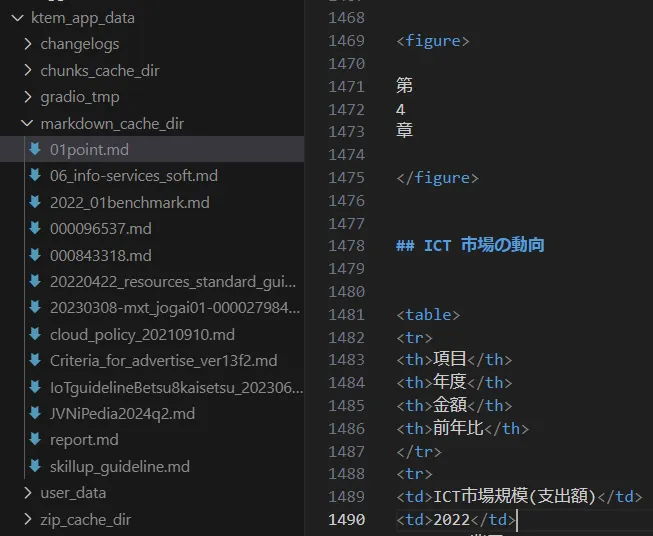
ファイルをパースした内容を確認します。kotaemonは、ktem_app_data 配下にデータを格納しています。File loader はデフォルトのパーサーの場合はチャンク化されたテキストのキャッシュがktem_app_data/chunks_cache_dir、Azure DIでスキャンした場合はMarkdown形式のキャッシュがktem_app_data/markdown_cache_dir に置かれます。ここで期待したパースが出来ているかを確認します。
実際にAzure DIでスキャンした資料と結果を以下に示します。画像から文字が抽出され、表形式は<table>構造であることが分かります。
取得したい情報がGraphRAGとして正しくインデクシングされているかも確認します。GraphRAGに関するデータは、ktem_app_data/user_data/files/graphragに置かれています。データの構造については前々回のブログに詳細があるので参考にしてください。
検索
実際にUI画面から質問を入力し、informationパネルから得られる情報を確認しています。エンティティ一覧やその優先度といった取得情報を参考に、期待した情報が高スコアとなっているか、低いスコアの場合GraphRAGのインデクシングによるものか、kotaemonに具備された機能の活用により改善の余地があるかを確認していきます。
kotaemonに具備された機能の活用の場合、例えば、推論の質問形式が、
企業のAIサービスの導入を阻害する主な要因は何ですか?調査結果をもとに説明してください。
(期待する回答は「AIを利用する環境が整っていない」)
という質問は、
企業のAIの利用を許可しない一番の要因は何ですか?調査結果をもとに説明してください。
にすると上手くいくことがあります。原因はベクター検索の類似度計算によるものであり、対処法の一つとして、Reasoning methodをより高度なものに変更することで上手くいく場合があります。以下はcomplexにした場合の説明です(日本語部分はMicrosoft Edgeの翻訳)。
なおcomplexの他に、Agent指向によるReasoning methodも用意されているのですが、GraphRAGでは残念ながら上手く動きませんでした。今後の改善に期待です。


その他
改善作業を効率的に行うために留意した点をあげます。
- ベンチマーク全体から傾向を把握する: NGの場合データセットのどの種別(Paragraph/Table/Image)が顕著か、また、情報が誤り(Hallucinations)なのか、取りこぼし(Omissions)なのかを見て行きます。kotaemonはスコアリング時に閾値を設け、関連性の低いスコアについては「分かりません」と回答するように作られているため、一つの判断材料となります。また今回利用させていただいたデータセットは、正解の場合の該当する資料の記載場所や種別が整理されており、とても有益でありがたいと感じました。
- 理解度の高い業務ドメインのデータセットに絞り母数を少なくしてから始める: 当社はIT技術者の会社のためデータセットのドメインも'it'から評価し始めました。GraphRAGの解析を進めると適切なエンティティとリレーションが存在するかを見て行くことになり、ある程度のドメインの知識は必要です。また母数を少なくすることは迅速な改善ループの実現につながります。
評価結果
以下の組み合わせで、ベンチマークを取得してみました。
- Resources:
GraphRAG Collection - Retrieval settings/File loader:
Azure AI Document Intelligence (figure+table extraction) - Reasoning options:
simple
| RAG | 金融 | 情報通信 | 製造業 | 公共 | 流通・小売 | Average |
|---|---|---|---|---|---|---|
| kotaemon + GraphRAG 1.0.1 (gpt-4o-mini) | 0.550 (33/60) | 0.633 (38/60) | 0.467 (28/60) | 0.533 (32/60) | 0.500 (30/60) | 0.537 (161/300) |
ここまで来て期待に添えず残念な結果ですが、スコアは同等のLLMを用いたと思われるLangchain (gpt-4o-mini) や OpenAI Assistant (gpt-4o-mini)には届かずでした(スコアの比較については脚注1を参照)。スコアが低い原因を考察します。
- リーダーボードで高スコアを獲得しているOpenAI Assistantは、画像を解釈できる機能をRAGに適用していると推測されます。特に「グラフ」などの図形の読み取りには、単なるテキスト抽出だけでなくグラフの解釈が必要なため、このような差がでていると思われます。このような図形への対策としてはコストはかかりますが、独自のFile loaderを作成し、Azure DIとLLMのマルチモーダルAPIを組み合わせるようにすると性能向上が見込まれます。
- GraphRAGの特長に「全体概要に関する回答ができる(グローバル検索)」「文書の距離があっても情報を拾える」がありますが、リーダーボードの質問にそのような特性を持つ質問が少ないということも関係しそうです 2 。
- LLM-as-a-Judgeの難しさも関係している可能性があります。GraphRAGによる回答量は比較的多めでパラグラフを構成しながら網羅的に回答する傾向があり、それが「余計な情報がある」と判定されてしまっている感触を持ちました。この状況は
Reasoning options: complexの場合はより顕著で、simpleの時よりもむしろスコアが下がっています。LLMによる判定の難しさを感じる結果となりました。 - kotaemonは、Reasoningでハルシネーションを避けるしくみとして、関連度のスコアが低い場合「申し訳ありませんがその質問にはお答えできません」という意味の回答拒否をします。今回それらが過度に作用した状況も散見されました。なお今回GraphRAGではない通常のRAGの動作も確認しましたが、回答拒否が多くかなりの低スコアとなりました。
その他
その他、検証を進めていくうちに幾つか気づいたことです。
- kotaemonのGraphRAGはv0.3をベースとしており、そのため実運用に適用するには以下の課題があります。GraphRAGv1.0ではこれらが改善できそうな機能拡充がされており、今後に期待です。
- 差分更新ができない
- 複数文書に対する検索に対応していない(ベンチマーク取得には障害となったためこの部分 ⧉を暫定的にコメントアウトして対応しました)
- インデクシングが別プロセスで行われ、エラー処理が不十分
- kotaemonにある別のGraph RAG技術の実装である
LightRAG,nano-graphragの計測は上手く行きませんでした。今回のGradioのAPIを用いることで異なる実装も比較的簡単に計測の実行はできました。しかしながら性能比較を試みたもののインデクシングに時間がかかりすぎたりタイムアウトエラーを起こしたりして完遂できませんでした。kotaemonは今後インデクシングの仕組みを改善しようとしている様子もあり、そのうち解決するかもしれません。 - GraphRAGにはPrompt Tuning ⧉と呼ばれる、インデックス作成用のプロンプトをカスタマイズできる仕組みがあります。適用すれば性能向上するかと思いAuto Tuning ⧉を試したのですが性能はほぼ変わりませんでした。推測ですが、今回のデータセットについては独自のプロンプトを明記するほどの専門用語の出現は少なかったと考えています。
さいごに
GraphRAGをkotaemonにより機能強化し性能検証を行いました。本文中の結果にもあるとおり、ベンチマークからはあまり性能向上は見込めず、実運用に向けての課題は残る結果となっています。しかしながら現状のGraphRAGの性能や機能強化の可能性、さまざまな手法を組み合わせたものを同一の方法で評価できる仕組みについて、少しでも何かの糧になればと思い、執筆しました。
GraphRAGとkotaemonの組み合わせについては、小回りの利く高機能のRAGツールとして当社では引き続き注目していきたいプロダクトです。 皆さまも今回の記事を参考に是非試していただけたらと思います。
Footnotes
-
注意: データセットに指定されているファイルが一部入手できなかったため、RAG Benchmark ⧉よりもその分(-6点ほど)低い基準となります。また評価に使用するLLMもリーダーボードと異なり、それが原因か当社の評価ツールは全体的に低スコアの傾向でした(例: Langchain(gpt-4o-mini)は当社では0.613(184/300)で-32点の開きあり)。したがいまして、点数のみの正確な比較は参考程度としていただきますよう了承ください。 ↩ ↩2
-
効果のほどは未検証なので脚注に書きますが、適切な評価のためにはLLMにGraphRAG用の質問を探してもらう方法が上手くいくかもしれません。データセット内容とGraphRAGの論文にある例題をFew Shotとして与え質問を幾つか作成してもらう方法が考えられます。 ↩
