

こんにちは。経営企画本部AI推進室の窪田です。今までAI推進室で複数回取り上げてきたMicrosoft GraphRAG ⧉ですが、昨年の12月に公式リリースが発表 ⧉されました。
今回は前回Microsoft GraphRAGの内部構造について取り上げた内容から新規に追加された機能や改善された点を、前回と同様に元となる論文やブログ記事、GitHubのコードをもとに内部の構造を解析し、比較しながら紹介していきます。
今回調査した公式リリースのGraphRAGは、執筆時点の最新版であるv1.2を使用しています。
プレリリース版のGraphRAGとの違い
公式リリースを発表したブログ記事を見ると、GraphRAGを利用するユーザ目線の使い勝手の関わる修正が多く盛り込まれています。
具体的には、
- 新規プロジェクト作成時のセットアップ手順の改善
- CLIの改善
- データモデルの簡素化
- 差分更新機能の追加
などが挙げられます。
今回はこの中で、開発プロジェクトで利用する場合に影響が高いと思われる「差分更新機能の追加」と「データモデルの簡素化」について取り上げます。 また、前回の記事でGraphRAGを扱った際には紹介されてなかった検索手法「DRIFTサーチ」についてもGraphRAGにおいて重要な機能であるためあわせて取り上げます。
DRIFTサーチ
GraphRAGの検索方法として、従来はグローバルサーチとローカルサーチの2種類の検索方法が用意されていましたが、新たに「DRIFTサーチ」という検索方法が追加されました。 DRIFTサーチの「DRIFT」は(Dynamic Reasoning and Inference with Flexible Traversal)の頭文字を取ったもので、DRIFTサーチについて説明しているドキュメント ⧉によると、「グローバルサーチとローカルサーチの両方の特性を組み合わせてコストと応答の質のバランスを取りつつ、詳細な回答を生成する方法」と記載されています。 実際、どのように両方の特性を組み合わせているかを処理を見ながら確認していきます。
処理の流れ
以下がDRIFTサーチの処理の流れです。

DRIFTサーチの処理は大まかに、
- コミュニティレポートの選定とフォローアップ質問の生成
- 生成されたフォローアップ質問への回答
- 回答の集約と最終回答の生成
の3つに分かれています。さらにこの3つの処理について詳細に説明します。
コミュニティレポートの選定とフォローアップ質問の生成
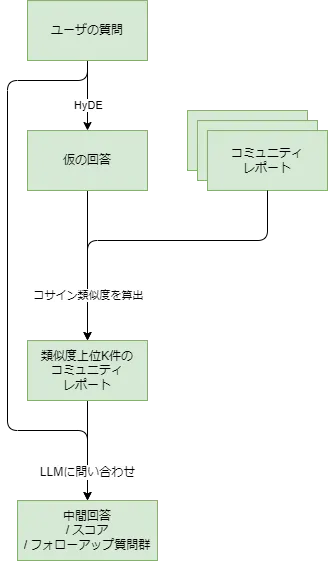
この処理はPRIMERと呼ばれており、ユーザーの質問(クエリ)をもとにHyDE(Hypothetical Document Embeddings)を利用して仮の回答を生成し、コミュニティレポートとの類似度を求め、上位K件のみを選定します。
その後、選定されたコミュニティレポートと元のユーザが入力したクエリをもとに中間回答、スコア、さらに中間回答に対して詳細な情報を引き出すためのフォローアップ質問群を生成するように、LLMに以下のプロンプトで指示しています。
プロンプトの内容を日本語に翻訳し、要約したものが以下となります。
- スコア: 中間的な回答の関連性を0から100の範囲で評価します。
- 中間的な回答: コミュニティレポートに沿った詳細で長さが2000文字の回答を、マークダウン形式で提供します。この回答の冒頭に、内容がクエリとどう関わっているかを説明する見出しを入れます。
- フォローアップクエリ: トピックをさらに探るための質問リストを少なくとも5つ作成します。
これらの情報を駆使して、報告書に登場するエンティティについて詳細な情報が必要かどうかを判断し、一般知識を基に回答を強化するためのエンティティを考えることができます。
最後に、指定したクエリ及びコミュニティレポートに基づいて中間的な回答とスコアをJSON形式で提供します。
実際にPRIMERの処理結果を見るために、DRIFTサーチを実行してみます。DRIFTサーチの実行は、以下のコマンドで行うことができます。
python -m graphrag query --root ./ragtest --method drift --query "各武将のやったことをまとめて"検索用のデータですが、今回も前回と同様に歴史上の人物の情報をWikipediaから取得して使用しています。 (今回も前回記事との比較のために実在する歴史上の人物を情報として利用しましたが、こちらのブログ ⧉に記載されているように、GraphRAGの効果を確認するには、LLMのトレーニングデータに存在しない架空のデータを利用する方が良いです。)
PRIMERの処理結果が返却されると、以下のような情報を見ることができます。 具体的なソースの位置はここ ⧉です。
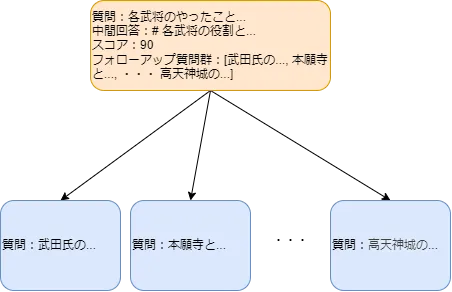
{ 'intermediate_answer': '# 各武将の役割と歴史的背景\n\nこのテキストでは、日本の戦国時代における各武将の行動や役割につい て概説します。武田氏、特に高天神城は、武田家の重要な拠点として知られ、彼らの敵である織田氏との戦闘において重要な役割を果たしました。武田氏は、その軍事的能力だけでなく、戦略的な同盟関係を築くことで競合する多くの大名と対戦しました。この時代、武田氏は他のクランとの争いを通じて日本の歴史に深く影響を与えた重要な存在でした。\n\nまた、木曾義昌は武田氏の策略の中で重要な役割を果たしました。彼の軍事的貢献は、武田氏が敵を打ち破るために必要な指導力と戦略的洞察を提供したことを示しています。加えて、本願寺は、信長に対抗するための政治的および軍事的抵抗において重要な役割を果たしました。この寺院は、武将との同盟を形成し、織田氏の勢力に立ち向かいました。\n\nさらに、上杉氏は、戦国時代の重要な武士であり、徳川家康に対抗するために戦いました。彼らの軍事行動は、関ヶ原の戦いにおける重要な戦略を形作り、その後の日本の政局にも影響を及ぼしました。彼らの動きは、戦国時代の権力闘争の中での断固たる反抗の象徴でもあります。これらの武将たちの行動は、戦国時代の歴史的背景を理解する上で欠かせない要素であり、彼らの戦術や戦略は、それぞれの武将が直面した挑戦を反映しています。', 'score': 90, 'follow_up_queries': [ '武田氏の戦術について詳しく教えてください', '本願寺と信長の関係はどのようなものでしたか?', '木曾義昌に関する詳細 な情報はありますか?', '上杉氏と徳川家康の対立について知りたい', '高天神城の歴史的意義と役割は何ですか?' ]}※ 実際はこのオブジェクトが複数ある場合があります。
JSONの中身を見ると中間回答(intermediate_answer)とスコア(score)、そしてフォローアップ質問群(follow_up_queries)が一組として生成されていることがわかります。
最後に、上記の情報をまとめたものを親ノードとし、子ノードとしてフォローアップ質問群をぶら下げます。 グラフの管理には、NetworkX ⧉ライブラリを使用しています。
PRIMERの処理後のグラフは以下のようになります。
生成されたフォローアップ質問への回答
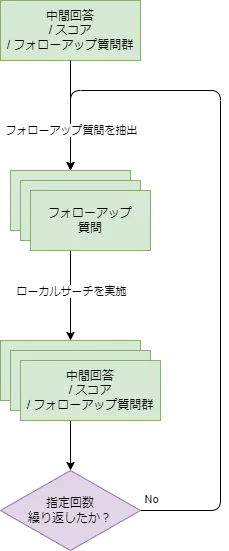
PRIMERで作成したグラフの中で、中間回答の情報を持っていないノードに対してローカルサーチを実施し、回答を生成します。 対象のすべてのノードに対して回答を生成するのではなく、指定された個数をピックアップして回答するようになっています。 ここで、ピックアップされるフォローアップ質問はランダムに選ばれます。
その後、選ばれたフォローアップ質問に対してローカルサーチを実行しますが、ここでもPRIMERと同様に中間回答、スコア、フォローアップ質問群の生成を行うプロンプトになっています。
プロンプトの内容を日本語に翻訳し、要約したものが以下となります。
あなたは、提供されたデータテーブルに関する質問に答えるアシスタントです。ユーザーの質問に基づいて、テーブルの情報を要約し、応答を生成することが目的です。データに基づくポイントは、明示的にデータの参照を含めてリストする必要があります。特に 「Sources」テーブルが重要で、文脈を維持しながら回答することが求められます。
応答は特定の形式で作成し、0から100のスコアとフォローアップ質問のリストを提供する必要があります。
こちらも処理結果の中身を表示すると以下のような情報が見れます。
query: 本願寺と信長の関係はどのようなものでしたか?answer: # 本願寺と信長の関係
本願寺と織田信長の関係は、戦国時代の日本において非常に重要なものでした。信長は、彼の権力を確立する過程で本願寺と対立し、同時にその影響力を利用しようとしました。
## 対立の背景信長は、彼の政権を強化するために、宗教勢力である本願寺との対立を避けることができませんでした。特に、信長が本願寺に対して攻撃を行ったのは、彼の権力を脅かす存在と見なしていたからです。天正元年から天正十年にかけて、本願寺との戦争が続き、信長はこの戦争を通じて本願寺の力を削ぐことを目指しました。特に、天正8年には本願寺との和睦が成立し、信長は一時的に天下の静謐を 達成しましたが、これは長期的な解決には至りませんでした[Data: Sources (72, 73, 86, 79, 75)].
## 和睦とその後信長は、天正8年に本願寺との和睦を結びましたが、これは本願寺側の抵抗感が強く、教如が大坂に留まって戦闘を続けるなど、完全 な解決には至りませんでした。この和睦は、信長が「天下一統」を目指す過程での一つの画期的な出来事とされています[Data: Sources (72, 73, 86)].
## 信長の宗教観信長は、宗教に対して複雑な態度を持っていました。彼は神仏に対して信仰心を持ちながらも、迷信を嫌い、合理的な考え方を重視しました。このため、信長は本願寺との関係においても、宗教的な側面だけでなく、政治的な側面を重視していました[Data: Sources (72, 73, 86)].
## 結論信長と本願寺の関係は、対立と和睦を繰り返しながら、信長の権力基盤を形成する上で重要な役割を果たしました。信長の本願寺に対する攻撃は、彼の天下統一の野望を実現するための一環であり、宗教と政治の複雑な関係を示しています。score: 85.0follow-ups:本願寺との戦争の具体的な経緯は?信長の宗教観について詳しく知りたい。本願寺の教義と信長の政策の関係は?信長の他の敵対勢力との関係はどうだったのか?本願寺との和睦の影響はその後の歴史にどう影響したか?queryにはPRIMER処理で生成されたフォローアップ質問が設定されており、対応する中間回答(answer)とスコア(score)、フォローアップ質問群(follow_ups)が生成されていることがわかります。
最後に、上記の情報でノードを更新し、子ノードとしてフォローアップ質問群をぶら下げます。 図にすると、以下のようにPRIMERで生成したノードを根(root)とした樹形図のような形になります。
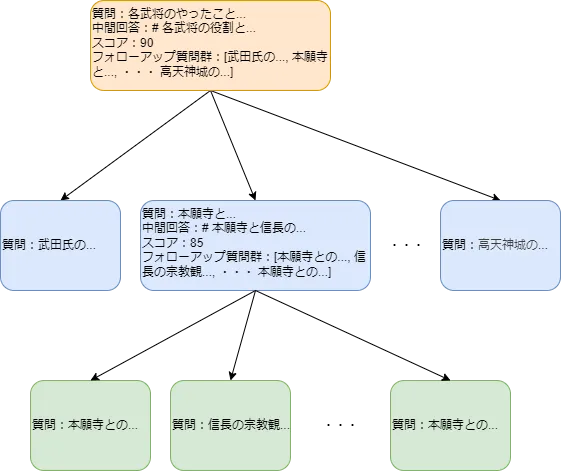
ここまでの処理をまとめて1回とし、設定値で決められた回数(デフォルトは3回)分繰り返し実行します。 繰り返し実行することで、フォローアップ質問への回答に対するフォローアップ質問が生成され、樹形図がどんどん深くなり、元のユーザの質問からさらに深堀りした回答が得られる仕組みとなっています。
回答の集約と最終回答の生成(reduce)
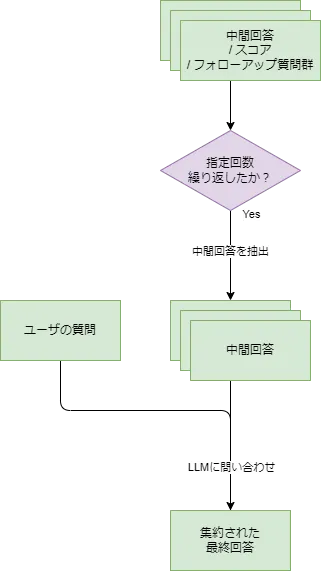
グラフ内に存在する中間回答を集約して、最終的な回答を生成します。 この処理は、グローバルサーチのreduce処理と似ており、以下のプロンプトで生成しています。
今までのプロンプトと同様に、日本語に翻訳と要約を行ったものが以下です。
提供された報告書のデータに基づいて質問に答えるアシスタントの役割があります。このアシスタントは、ユーザーの質問に対する応答を生成する際、報告書の情報を要約し、応答の形式と長さに応じた適切な内容を盛り込むことを目指します。また、必要に応じて一般的な知識を使用し、正確かつ簡潔な表現を心がけます。
データによって裏付けられた情報は、必ず明示的なデータ参照とともに提供し、同一の参照に5つ以上のレコードIDを含めないようにします。さらに、一般的な知識を用いる場合には、データで支持されていないことを明示する必要があります。最後に、応答はセクションとコメントを追加し、マークダウン形式で整理することが求められます。
今回の質問に対する回答は以下のように出力されました。
SUCCESS: DRIFT Search Response:# 各武将のやったことのまとめ
日本の戦国時代は、多くの武将たちが権力を争い、歴史を形作った重要な時期です。以下に、主要な武将たちの行動とその影響をまとめます。
## 毛利元就毛利元就は、多々良浜の戦いを通じて地域の権力構造に影響を与え、自らの名声を高めました。彼の戦略や戦術は後世の武将に多大な影響を与え、特に外交交渉や連携の重要性を示しました [Data: Sources (1, 2, 3)]。
## 武田信玄武田信玄は甲斐国を拠点に、徳川氏との激しい対立を通じて戦略的リーダーシップを示しました。彼の軍事的才能は、領土を守るだけでなく、周辺諸国における権力均衡にも影響を与えました [Data: Sources (1, 2, 3)]。
## 豊臣秀吉豊臣秀吉は、信長の後を継いで日本を統一しました。彼は特に、関ヶ原の戦いにおいて重要な役割を果たし、また、土地の測量や税制の整備を行い、経済基盤を強化しました。彼の文化政策も、茶道や能楽の振興を通じて日本文化に大きな影響を与えました [Data: Sources (1, 2, 3)]。
## 徳川家康徳川家康は、関ヶ原の戦いでの勝利を経て、江戸幕府を開きました。彼の治世は、平和な時代である江戸時代の基盤を築くものであり、商業や文化の発展を促進しました。家康は、戦闘よりも政治的な駆け引きを重視し、同盟を結ぶことで敵を分断する戦略を採用しました [Data: Sources (1, 2, 3)]。
## 明智光秀明智光秀は、織田信長に仕えた武将であり、彼の反乱(本能寺の変)は日本の歴史において重要な転機となりました。光秀の行動は、信長の死後の権力争いを引き起こし、最終的には豊臣秀吉の台頭を助ける結果となりました [Data: Sources (1, 2, 3)]。
## 結論これらの武将たちの行動は、戦国時代の日本における軍事的および政治的動向に大きく寄与しました。彼らの戦略や信念は、後の歴史に多くの教訓を残し、日本の過去の複雑さを知るために不可欠な要素となっています。今回の質問は「各武将」や「やったこと」など抽象的な内容でしたが、結果から意図通りの回答が得られたことがわかります。
さらに、比較のために同じ質問内容でローカルサーチとグローバルサーチも動作させてみました。
ローカルサーチ
SUCCESS: Local Search Response:# 各武将の業績まとめ
## 織田信長
織田信長は日本の戦国時代における重要な武将であり、特にその軍事的な才能と政治的な手腕で知られています。彼は、戦国時代の混乱を背景に、強力な大名として台頭しま した。信長の主な業績には、以下のようなものがあります。
- **軍事的勝利**: 信長は、桶狭間の戦いで今川義元を破るなど、数々の戦闘で勝利を収めました。この戦いは、彼の名声を高める重要な出来事でした [Data: Reports (2); Relationships (931)]。- **中央集権化の推進**: 信長は、戦国時代の分裂した日本を統一するために、他の大名との同盟や敵対を駆使しました。彼の政策は、後の徳川幕府の基盤を築くことに寄与 しました [Data: Reports (2); Entities (890)]。- **文化の振興**: 信長は、茶道や芸術の発展にも寄与し、特に安土城の建設は彼の文化的影響を象徴しています [Data: Reports (2)]。
## 豊臣秀吉
豊臣秀吉は、信長の死後に日本を統一した武将であり、彼の業績は多岐にわたります。
- **日本の統一**: 秀吉は、信長の後を継ぎ、戦国時代の終焉を迎えるために多くの戦闘を指揮しました。特に、山崎の戦いでの勝利は彼の地位を確立する重要な要素でした [Data: Reports (5); Relationships (78)]。- **朝鮮出兵**: 秀吉は、朝鮮半島への侵攻を試みましたが、これは彼の軍事的野心を示す一方で、長期的には日本にとっての負担となりました [Data: Reports (5)]。- **文化政策**: 秀吉は、聚楽第を政治の中心として文化の振興にも力を入れ、茶道や芸術の発展を支援しました [Data: Reports (5); Entities (219)]。
## 明智光秀
明智光秀は、信長の家臣でありながら、彼に対する反乱を起こしたことで知られています。
- **本能寺の変**: 光秀は、1582年に信長を本能寺で討つという大胆な行動に出ました。この事件は日本の歴史において重要な転換点となりました [Data: Relationships (1889)]。- **軍記の記録**: 光秀に関する記録は『明智軍記』に残されており、彼の生涯や業績を知る上で貴重な資料となっています [Data: Entities (1329); Relationships (1764)]。
## 結論
これらの武将たちは、戦国時代の日本においてそれぞれ異なる役割を果たし、歴史に大きな影響を与えました。信長の軍事的才能、秀吉の統一と文化政策、光秀の反乱は、い ずれも日本の歴史の重要な一部を形成しています。彼らの業績は、今日の日本の文化や社会においても影響を与え続けています。DRIFTサーチの内容と比較すると、各武将ごとの内容は詳細に記載されていますが、出力されている武将の人数は3人と少ないです。
グローバルサーチ
SUCCESS: Global Search Response:# 日本の戦国時代における主要武将の業績
日本の戦国時代は、数多くの武将たちが権力を争い、国を統一するために戦った tumultuous な時代でした。以下に、主要な武将たちの業績をまとめます。
## 織田信長 (Oda Nobunaga)織田信長は、戦国時代における日本の統一に重要な役割を果たしました。彼は革新的な軍事戦略を用い、特に桶狭間の戦いでの勝利が有名です。信長は、他の大名との同盟を 形成し、彼の支配下での政治的安定を図りました。彼の死は、さらなる権力闘争を引き起こし、後の徳川幕府の台頭につながりました [Data: Reports (1, 8, 15, 240, +more)]。
## 豊臣秀吉 (Toyotomi Hideyoshi)豊臣秀吉は、織田信長の死後に権力を握り、日本の統一を進めました。彼は山崎の戦いで明智光秀を打ち破り、権力を確立しました。秀吉の軍事的な成功は、朝鮮への侵攻な ど、国際的な影響力を拡大することにもつながりました。彼の改革は日本の政治的安定に寄与し、彼の影響は今も続いています [Data: Reports (6, 8, 10, 12, +more)]。
## 徳川家康 (Tokugawa Ieyasu)徳川家康は、関ヶ原の戦いでの勝利を経て、徳川幕府を樹立しました。彼の戦略的な同盟と軍事行動は、戦国時代の終焉と江戸時代の始まりをもたらしました。家康の統治は 、250年以上にわたる平和と安定をもたらし、江戸時代の文化的な繁栄を支えました [Data: Reports (2, 5, 11, 18, +more)]。
## 明智光秀 (Akechi Mitsuhide)明智光秀は、織田信長の忠実な家臣でありながら、彼を裏切り本能寺の変を引き起こしました。この行動は日本の歴史において重要な転機となり、光秀は裏切りの象徴として 知られるようになりました。彼の行動は、信長の死後の権力の空白を生み出しました [Data: Reports (14, 16, 9)]。
## 武田信玄 (Takeda Shingen)武田信玄は、戦国時代の強力な軍事力を持つ大名であり、特に徳川軍との戦闘での戦略的勝利が知られています。彼の軍事的手腕は、当時の権力バランスに大きな影響を与え ました。信玄の戦略は、彼の領土拡大と他の大名との競争において重要な役割を果たしました [Data: Reports (12, 15)]。
## 結論これらの武将たちは、日本の歴史において重要な役割を果たし、それぞれの戦略や行動が後の時代に大きな影響を与えました。彼らの業績は、戦国時代の複雑な権力闘争を理 解する上で欠かせない要素です。こちらもDRIFTサーチの内容と比較すると、さまざまな武将について挙げられていますが、豊臣秀吉の内容をみると日本の政治的安定について何をして寄与した具体的な取り組みが記載されていないなど、具体的な内容が不足している部分が目立ちます。
このように、DRIFTサーチはローカルサーチの具体的な情報まで収集できる特性と、グローバルサーチの網羅的な情報を収集できる特性を兼ね備えており、さらにPRIMERでは検索対象とするコミュニティレポートをHyDEを利用して絞り込むことで、品質を担保しつつ検索コストを削減しています。そして、PRIMER処理で生成されたフォローアップ質問をもとにローカルサーチを用いて網羅的に回答することで、文書内の詳細な情報を参照して回答することができるようになっています。
差分更新機能
プレリリース版(v0.2)のGraphRAGでは、文章をインデックス化した文書データに追加しようとすると、すべての文書を対象に再インデックス化を行う必要がありました。 正式リリース版では、追加した文章のみをインデックス化し、差分を更新する機能が追加されました。 前回の記事の課題でもあり、システム開発プロジェクトでは文書の追加は必ず発生するため、この機能の追加は非常に嬉しいものです。
プレリリース版のGraphRAGのインデックス処理では、毎回入力された文章をもとにナレッジグラフを構築していました。そのため、新たな文章を追加した後にインデックス処理を実施すると、すべての文章を対象にグラフの再構築が実施されていました。これにより、文章が追加されるたびにグラフの再構築が必要となり、コストがかかっていました。 今回の差分更新機能では、新規追加された文章のみを対象にインデックス処理を実行し、追加された文章のみで作成したグラフと既存のグラフをマージすることでコストを抑えようという方針となっています。
差分更新機能の処理の流れを図にまとめると以下のようになります。
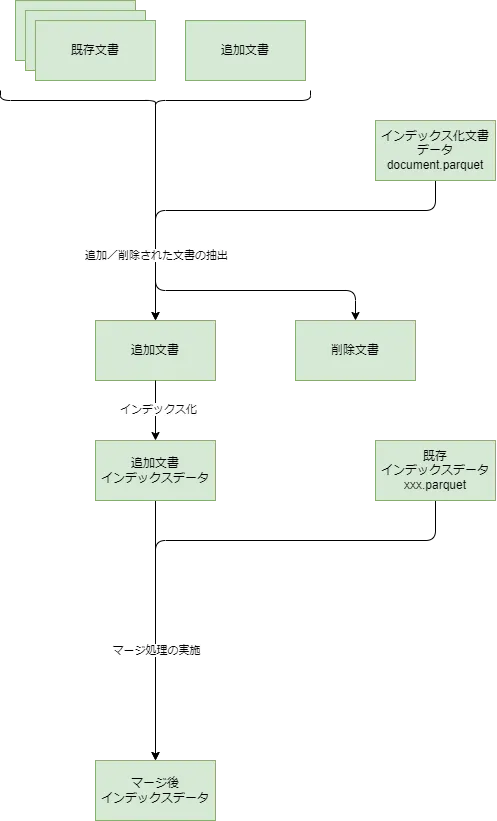
追加された文章群は、インデックス化した文章のリストの情報を保存したdocument.parquetファイルと、フォルダ内に格納されているファイル名を突き合わせることで検出されています。
get_delta_docs関数 ⧉にて追加された文章群(new_docs)と削除された文書群(deleted_docs)を検出していますが、削除された文書群については、その後の処理では使われていないようです。
その後、追加された文章群のみを対象にインデックス処理が実行され、Pandas DataFrameの形式に変換されたデータと、既存の文書をインデックス化したデータが格納されている各種parquetファイルをマージすることで差分の更新を実現しています。
マージの処理はupdate_dataframe_outputs関数 ⧉にて実施されており、追加文書をインデックス化したデータと既存のデータを単純に連結しています。連結時には、主キー相当であるhuman_readable_idについて重複がないように調整しています。
ただし、エンティティの連結時には、エンティティの名前を比較し、既存のインデックスデータに同名のエンティティが存在する場合、既存のエンティティに集約するという工夫が_group_and_resolve_entities関数 ⧉で行われています。
まとめると、既存のデータをもとに追加された文書を抽出し、その文書に対してのみインデックス化を実行することで、インデックスのコストを最小限に抑える仕組みとなっています。 マージに関しては、同一のエンティティのマージ以外は追加分のデータをそのまま連結しているのみで、シンプルなつくりとなっています。 また、追加された文書のほかに削除された文書についても抽出していましたが、差分追加機能について議論されているissue ⧉を見ると、削除分についてはスコープ外となっているため、その後の処理では使用されていません。
データモデルの簡素化
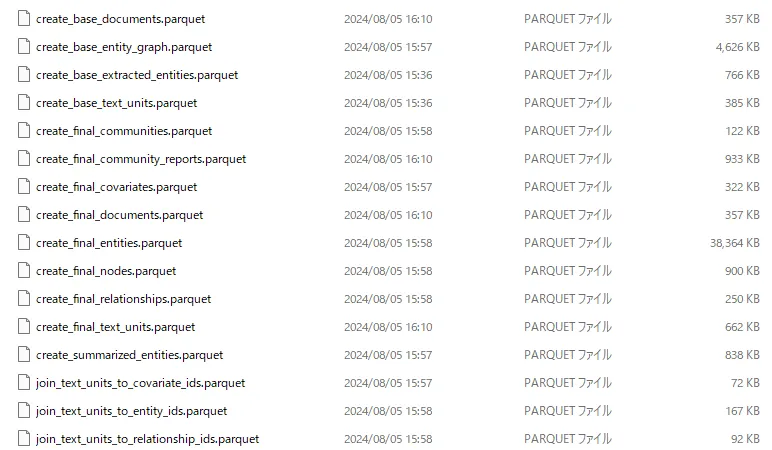
データモデルの簡素化では、プレリリース版では出力されていた中間ファイルなどが廃止され、最終的なファイルのみ出力されるようになったとブログに記載されています。 そのため、実際にプレリリース版と公式リリース版の出力内容を比較してみました。
プレリリース版(v0.2)
公式リリース版(v1.2)
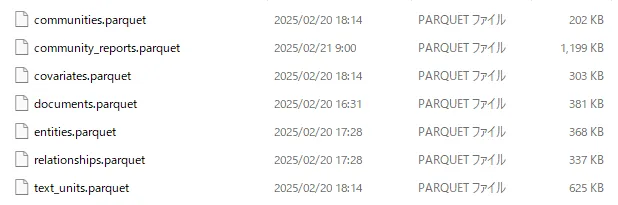
一目瞭然ですね。プレリリース版の中間ファイルに相当するcreate_base_xxx.parquetやjoin_text_xxx.parquetファイルが出力されなくなり、公式リリース版ではプレリリース版の最終的なファイルに相当するcreate_final_xxx.parquet相当のファイルのみが出力されています。
また、類似のファイルが存在しなくなったためか、ファイル名に付与されていた余分な接頭辞も削除されています。
中間ファイルが廃止された背景についてもブログ ⧉に記載されており、プレリリース版で出力されていた中間ファイルはデバッグの目的が強く、ユーザ目線では最終的なファイルと混同する原因となっていたためです。 また、正式リリースのタイミングで冗長または未使用のフィールドについて見直しが行われ、整理されて削除されたことも挙げられます。
差分についてさらに細かく見ていくと、以下の2点の違いに気付くことができます。
create_final_nodes.parquetファイルに相当するファイルが公式リリース版には存在しないcreate_final_entities.parquetファイルに対応するentities.parquetファイルのサイズを比較すると大きく異なる
この2点については、どちらともentities.parquetファイルの中身を見ると解決します。
entities.parquet
1点目については、create_final_nodes.parquetが持っていたグラフの描画に関連する情報(degree、x、y)がentities.parquetに追加されており、統合されたことがわかります。
2点目については、entities.parquetからgraph_embedding、description_embeddingのカラムが削除され、ローカルのDB(lanceDB)に格納されるようになったためです。
1536次元の埋め込みデータは大きいため、かなりの削減がなされたようです(プレリリース版のparquetファイルについては前回記事に記載しています)。
さいごに
公式リリースされたGraphRAGについて、特徴や改善点についてまとめました。プレリリース版と比べて、開発プロジェクトへの導入が考慮された機能や改善点が多く盛り込まれていると感じました。さらに、公式リリースの記事では今後の方向性として、インデックス時のLLMの利用を最小限としたLazyGraphRAG ⧉の適用や、ユーザー独自のモデルAPI、ストレージ、ベクターストアが利用できるようなアーキテクチャの変更といったさらなる機能追加や改良について記載されています。
また、本記事の執筆中にv2.0のメジャーアップデートも発表 ⧉されました。v2.0では更なる機能の追加や改善が盛り込まれていると思いますので、今後も引き続きGraphRAGの動向を追っていこうと考えています。
参考文献
- Moving to GraphRAG 1.0 – Streamlining ergonomics for developers and users ⧉: GraphRAG v1.0の発表記事。特徴や改良点についてまとめられています。
- GrpahRAGのドキュメントサイト ⧉: ブログや論文やGitHubはここから辿れます。
- Microsoft GraphRAG でこれまでの RAG にはできなかった質問に回答させるメモ ⧉: GraphRAGの機能や実装方法について詳しく解説されています。
