

[!] この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは。経営企画本部AI推進室の鏡味、窪田です。先日のMicrosoftのGraphRAG紹介記事は多くの方に読んでいただいているようで嬉しく思います。当社のテックブログは他にも、プロジェクト開発などの現場に寄り添った面白い記事がありますので、是非ご参照ください。
今回もGraphRAGの記事です。当社はシステム開発を生業とするため、まず我々の仕事に役立てたいという思いから、
「システム開発プロジェクトにおいて、日本語の設計書と、さまざまな言語からなるコードを、外部知識としてRAGで扱いたい」
というユースケースにGraphRAGが適用できないかを検討中です。RAGの性能を決める要因は体感7割がインデクシング方法(残り3割がクエリ方法)であり、GraphRAGも例外ではありません。今回は「インデクシング≒ナレッジグラフの構築」に焦点を当てています。
なお、本記事のGraphRAGは、Microsoftが発表したGraphRAG (https://www.microsoft.com/en-us/research/project/graphrag/ ⧉) を示します。一般的なナレッジグラフとRAGを組み合わせた技術はGraph RAG技術と書いて区別します。
ユースケース
システム開発プロジェクトでドキュメントを扱うユースケースについてお話します。
現状と課題
システム開発プロジェクト、特に大規模や息の長い既存プロジェクトでは様々なドキュメントがあります。多種多様な設計書、複数の言語によるコード、テストコード、イシュー、テスト計画書、プロジェクト計画書、議事録や品質評価、運用マニュアルなど……。これらは相互に明示的・暗黙的な結びつきを持っており、理想的には全体を関連付けての効果的な活用が期待されます。そのためプロジェクトが堅牢であればあるほど、目的や様式の異なるドキュメント同士をどのように関連づけるかという、いわゆるドキュメントのトレーサビリティの重要性が高まります。実際には、トレーサビリティ情報が不足しているか、あっても万能ではないため、知りたいことを人間がキーワードを頼りに関連を探していくことになります。それでも「本質は何か」の情報が足りず、有識者の暗黙知の力を借りることになりがちです。
ドキュメント同士の関連にまつわる課題は、「目的が異なるためコンテキスト(文脈)がまちまちなもの同士を、どのように結びつけるか」という点にあります。一例として意外と見過ごせない日本人ならではの悩みは、日本語とプログラミング言語(英語ベースのアルファベットの識別子)の言語間のギャップです1。ドメイン特化の専門用語について、わざわざ日本語とアルファベット表記の対応表を管理することも多いでしょう。このようなトレーサビリティを阻害するギャップが積み重なり、全体把握を難しくしています。
ゴール:ドキュメント全体を把握したうえで新たな価値を生む
これらの課題を生成AIで克服し、特に暗黙知や属人性に依存したエンハンス開発において、すべての既存ドキュメントを関連付けたうえで新たなコード生成などの価値を生むことができたら素晴らしいことです。(GitHub Copilot Workspaceなど使える環境であれば良いですが、既存プロジェクトですぐに適用できる環境にないプロジェクトも多いでしょう)具体例としては、以下の問いに回答できるRAGです。
- 例:「既にある検索処理と仕様を参考にして、新たなデータの検索処理のコードを作ってください」
人間が行う場合、以下のような思考を繰り返して進めることになります。
- 既存の検索処理のドキュメントを横断的に調査し共通項を見出す
- 新たな設計を分析しコードへの適用方法を考える
- 上記を行き来しながらコードを生成する
同じような探索や推論をLLMにさせていくことを考えます。図にすると以下です。
本記事はこの中の「探索や共通項の抽出ができるようなGraphRAGのインデックス作成の検討」を範囲としています。
graph TB;
L(((LLM)))
C[検索実装の共通項]
C1[検索1コード]
C2[検索2コード]
D1(検索1設計書)
D2(検索2設計書)
D(検索設計の共通項)
C3[新たな検索処理のコード]
D3(新たな検索処理の設計書)
D3 ..->|同種を探す|D1
D3 ..->|同種を探す|D2
D1 ..->|共通項を見出す|D
D2 ..->|共通項を見出す|D
D3 ..->|共通項を見出す|D
D ..->|関連|C
C ..->|探す| C1
C ..->|探す| C2
C1 -->|Few-Shot|L
C2 -->|Few-Shot|L
D3 -->|推論|L
L ==>|生成|C3
subgraph コード
C1
C2
C3
C
end
subgraph 設計書
D1
D2
D3
D
end
サンプルプロジェクト
私たちは自社システムのドキュメントで検証を進めていますが、このブログには公開できないため、ブログ用の架空のシステムとして「いきもの情報」を管理する「いきもの管理システム」を例にあげて説明します。さらに、なるべくLLMが学習しない専門用語にするため、名称をLLMにもじらせて、「意希物(Yikimon)」という特殊な名称のシステムにしています。語呂を変えただけで一気に危険物っぽくなりました😅。
この「意希物管理システム」は、「意希物」というリソース(情報)を、よくあるCRUD処理で管理します。フロントエンドはVue.js、バックエンドはNode.js、設計書はMarkdown形式で書かれているものとします。
このブログでは簡単のため、以下の仕様の設計書・コードをデータセットにして検証します。
- 画面:メニュー、意希物登録、意希物検索
- 機能:意希物登録、と意希物検索
ファイルやフォルダ構成は以下です。
graph LR;
%% フォルダスタイル(docs以下)
style B fill:#ffea94,stroke:#333;
style B1 fill:#ffea94,stroke:#333;
style B2 fill:#ffea94,stroke:#333;
style B4 fill:#ffea94,stroke:#333;
style B6 fill:#ffea94,stroke:#333;
%% フォルダスタイル(src以下)
style C fill:#ffd700,stroke:#333;
style C1 fill:#ffd700,stroke:#333;
style C2 fill:#ffd700,stroke:#333;
style C3 fill:#ffd700,stroke:#333;
style C5 fill:#ffd700,stroke:#333;
style C7 fill:#ffd700,stroke:#333;
style D fill:#ffd700,stroke:#333;
style D1 fill:#ffd700,stroke:#333;
style D2 fill:#ffd700,stroke:#333;
style D4 fill:#ffd700,stroke:#333;
%% markdownファイルスタイル
style B3 fill:#bbf,stroke:#333,stroke-width:2px;
style B5 fill:#bbf,stroke:#333,stroke-width:2px;
style B7 fill:#bbf,stroke:#333,stroke-width:2px;
%% Vueファイルスタイル
style C4 fill:#bfb,stroke:#333,stroke-width:2px;
style C6 fill:#bfb,stroke:#333,stroke-width:2px;
style C8 fill:#bfb,stroke:#333,stroke-width:2px;
%% JSファイルスタイル
style D3 fill:#bff,stroke:#333,stroke-width:2px;
style D5 fill:#bff,stroke:#333,stroke-width:2px;
A[project/] --> C[src/];
C --> C1[client/];
C1 --> C2[yikimon/];
C2 --> C3[menu/];
C3 --> C4[Menu.vue];
C2 --> C5[register/];
C5 --> C6[Register.vue];
C2 --> C7[search/];
C7 --> C8[Search.vue];
C --> D[server/];
D --> D1[yikimon/];
D1 --> D2[register/];
D2 --> D3[register.js];
D1 --> D4[search/];
D4 --> D5[search.js];
A -->B[docs/];
B --> B1[yikimon/];
B1 --> B2[menu/];
B2 --> B3[menu.md];
B1 --> B4[register/];
B4 --> B5[register.md];
B1 --> B6[search/];
B6 --> B7[search.md];
課題解決への取り組み
GraphRAGをそのまま適用はうまくいかず
まず、単純に設計書とコードをそのままGraphRAGに読み込ませてナレッジグラフを作ります。グラフ作成には、エンティティと関係を抽出するプロンプト prompts/entity_extraction.txt が重要です。ここではGraphRAGのオートチューニング機能を使い、設計書とコードに即したプロンプトを自動生成してから、グラフを取り込みます。検証環境は、DEVELOPING.md ⧉ を元にpoetryベースで構築、実行します。
# graphrag リポジトリをcloneし、プロジェクトフォルダにて実行poetry install
# ドキュメントの格納mkdir -p ./ragtest/inputcp -r {プロジェクトドキュメント類} ./ragtest/input
# インデクシング環境初期化poetry run poe index --init --root ./ragtest/
# インデクシングの設定ファイルの編集vi ./ragtest/settings.yamlvi ./ragtest/.env
# プロンプトチューニングpoetry run poe prompt_tune --root ./ragtest/ --config ./ragtest/settings.yaml --language JAPANESE
# インデクシングの実行poetry run poe index --root ./ragtest/結果を可視化します。GraphRAGのリポジトリにある、yfilesを使った可視化ツール graph-visualization.ipynb ⧉のこのあたり ⧉に手を加え、./ragtest/output フォルダを指すようにします。
outputフォルダ内に時系列フォルダが作成される設定の場合は INPUT_DIRを以下のようにして最新が取れるようにすると楽です。
base_dir = "../../../ragtest/output"folders = [f for f in os.listdir(base_dir) if Path.is_dir(Path(base_dir) / f)]latest_folder = max(folders, key=lambda f: datetime.datetime.strptime(f, "%Y%m%d-%H%M%S").astimezone(datetime.timezone.utc))INPUT_DIR = Path(base_dir) / latest_folder / "artifacts"私たちは、もう少しコードに手を加え、GraphRAGのコミュニティの内容を四角い枠で出力できるようにしています。このブログの最後に変更ポイントを書いておきます。
以下は可視化した結果です。全体像です。
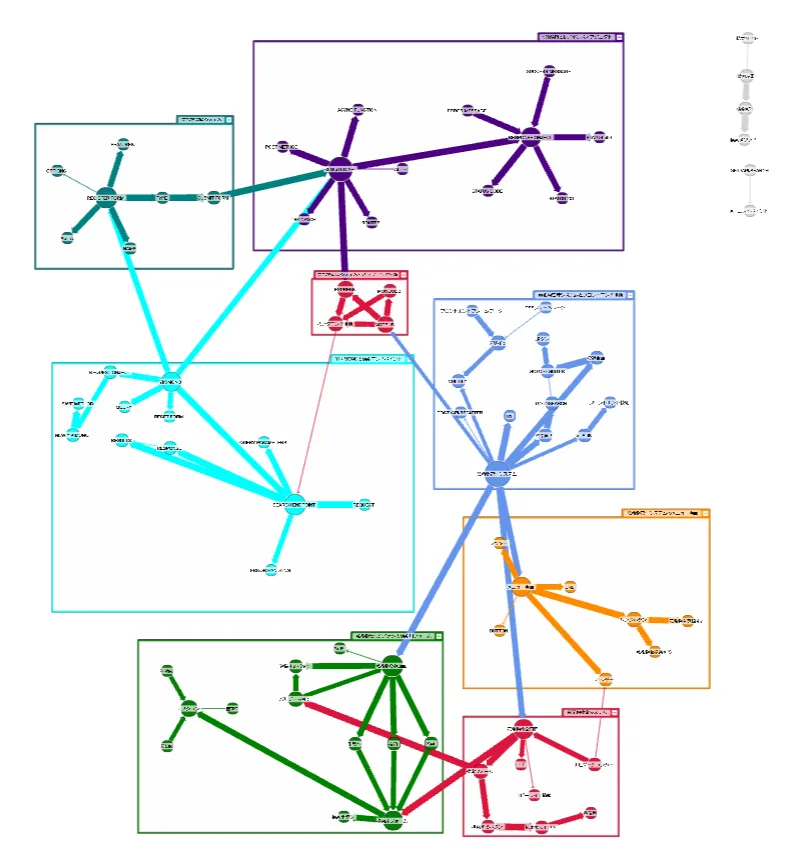
グラフ上部の拡大です。アルファベットが多いのでコードが中心のグラフです。
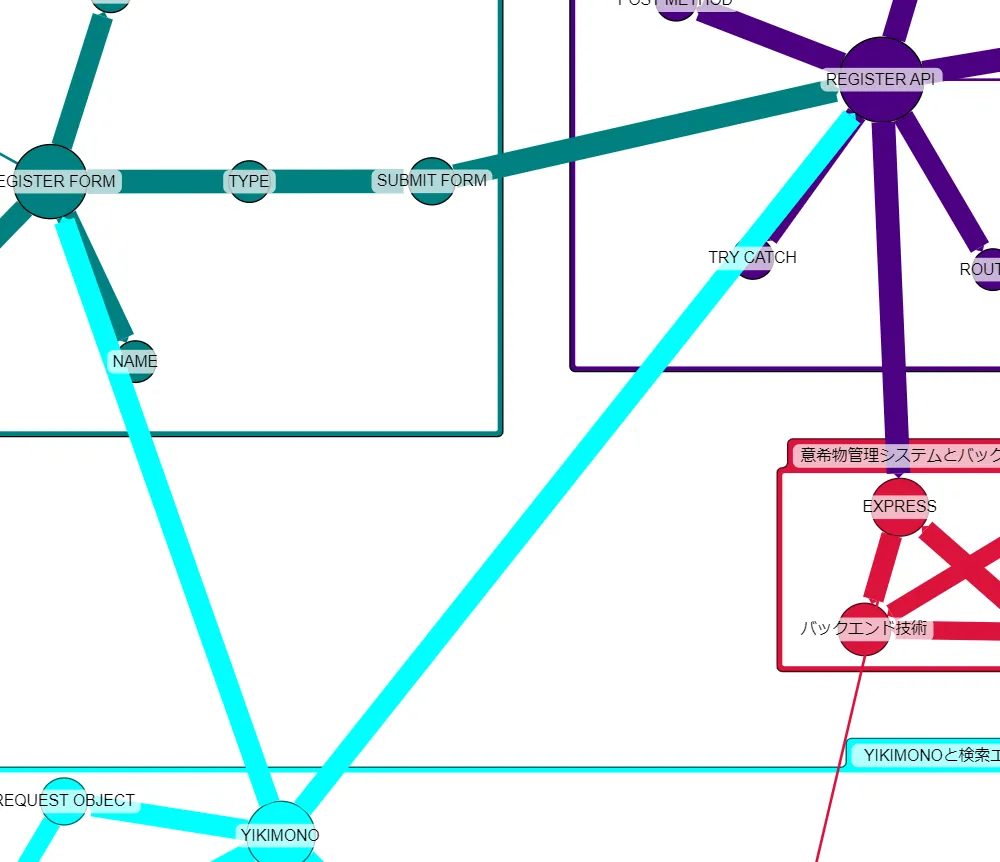
グラフ下部の拡大です。日本語が多く設計書が中心のグラフです。
一見よくできたグラフに見えるのですが、これはドキュメント上に頻出する単語を中心にグラフが作成されているのと、ファイルごとにコミュニティができている結果です。一方でドキュメント間の連携を目的としてみると「システムが本来もつ機能中心で描いてほしい」「設計書とコード、日本語と英語のつながりを持たせてほしい」点において改善が欲しいところです。
理由は以下が考えられます。
- 「設計書とコードにつながりを持たせたい」という意図を、プロンプトで伝えきれていない
- さらに、設計書とコードでは表現方法が違うので、単一のプロンプトによる抽出では厳しい
前者の、エンティティの抽出を意図したとおりにするにはどのようにすればよいか、について考えを整理していきます。なお後者は「文書種別(.md, .js, .vue)ごとにプロンプトをより分ける」というGraphRAGライブラリの機能追加の話となり詳細は割愛します2。
オントロジーの定義による解決
ナレッジグラフでエンティティの抽出をどのように行うかはGraphRAG特有のものではなく、従来からあるナレッジグラフ技術に基づくさまざまな理論やノウハウに依存しています。そのうちの一つが、オントロジー3 と呼ばれる、グラフで表現されるドメインの方針・定義・スキーマを示すものです。
graph TB
subgraph Instances[インスタンス]
H[太郎]
I[「ハリーポッター」]
H -- 読んだ --> I
end
subgraph Ontology[オントロジー]
A[人]
B[本]
A -- 読んだ --> B
end
いわゆるJavaなどのプログラミング言語でいうインスタンスに対するクラス定義や型定義です。解決したい課題についてオントロジーを定義し、LLMにはエンティティや関係をオントロジーにしたがって抽出するよう依頼することで、課題解決に向けた統一されたグラフ構造になることが期待できます。
システム開発ドキュメントのユースケースにおけるオントロジーの定義
今回の課題の解決に適したオントロジーの定義を考えます。
- 開発者が押さえるべきシステムの構造を軸とすること。プロジェクト参画したらまず何から理解しようとするか?
- それらが階層化された分類がなされていること
- 加えて、設計書(主に日本語)とコード(主にアルファベットの識別子)の対応付けがされていること
-
- については、よくある「RESTfulなインターフェースを持つCRUDのWebアプリ」を想像し、「リソース(情報のまとまりの意味をもつもの)」と、それに対する「操作」という構造を軸にします。たいていのシステムはこの抽象化による理解がスタートとなるでしょう。
-
- は、大量のドキュメント類は何かしらの整理がされているはずですので「カテゴリ」の概念を入れます。フォルダ階層やパッケージの階層などが該当します。
-
- については、日⇔英の「同義語」の存在を入れます。
オントロジーの定義は、LLMにグラフの形を伝えられれば自然言語でも伝わるかもしれませんが、LLMが理解できる明確な定義として RDF (Resource Description Framework) や、Turtle (Terse RDF Triple Language) という、定義を記述するためのテキスト形式を使います。以下が Turtle 形式のオントロジーの定義です。
# エンティティの定義ex:リソース a rdfs:Class . # 情報の主体(例: データ構造、データクラス、引数、戻り値)ex:操作 a rdfs:Class . # 主に登録、照会、更新、削除、検索などのリソースに対する操作 (例: API、関数、メソッド)ex:カテゴリ a rdfs:Class . # リソースの分類 (例: フォルダ要素、ファイル、クラス、モジュール)
# プロパティの定義ex:操作を持つ a rdf:Property; rdfs:domain ex:リソース; rdfs:range ex:操作 .
ex:操作タイプ a rdf:Property; rdfs:domain ex:操作; rdfs:range rdfs:Literal .
ex:カテゴリを持つ a rdf:Property; rdfs:domain ex:リソース; rdfs:range ex:カテゴリ .
ex:親カテゴリ a rdf:Property; rdfs:domain ex:カテゴリ; rdfs:range ex:カテゴリ .
# 同義語の定義。エンティティそれぞれについて日本語名⇔英語名の関連づけ。ex:同義語 a rdf:Property; rdfs:domain rdfs:Class; rdfs:range rdfs:Class .文字にするとと分かりにくいですね。mermaidのgraph形式にしてみました。
graph TB
subgraph オントロジー[オントロジー]
A[リソース]
B[操作]
C[カテゴリ]
A -- 操作を持つ --> B
A -- カテゴリを持つ --> C
C -- カテゴリを持つ --> C
A <-.-> |同義語| A
B <-.-> |同義語| B
C <-.-> |同義語| C
end
実際にオントロジーの定義に沿って「意希物管理システム」のグラフ構造の骨子を書いてみます。同義語の存在を取り除けば、単純な「リソース」「操作」「カテゴリ」の関係であることがわかるでしょう。これは「理想的にはこうあってほしいというグラフ構造」になります。
graph TD;
subgraph リソース[リソース]
リソース_意希物[意希物]
Resource_Yikimon[Yikimon]
end
subgraph 操作[操作]
操作_登録[登録]
操作_検索[検索]
Operation_Register[Register]
Operation_Search[Search]
end
subgraph カテゴリ[カテゴリ]
カテゴリ_生物種[生物種]
カテゴリ_ルート[ルート]
Category_Species[Species]
Category_Root[Root]
end
リソース_意希物 --> |操作を持つ| 操作_登録
リソース_意希物 --> |操作を持つ| 操作_検索
リソース_意希物 --> |カテゴリを持つ| カテゴリ_生物種
カテゴリ_生物種 --> |親カテゴリ| カテゴリ_ルート
%% 同義語のリンク
リソース_意希物 <-.-> |同義語| Resource_Yikimon
操作_登録 <-.-> |同義語| Operation_Register
操作_検索 <-.-> |同義語| Operation_Search
カテゴリ_生物種 <-.-> |同義語| Category_Species
カテゴリ_ルート <-.-> |同義語| Category_Root
エンティティと関係抽出プロンプトの作成
以上の情報をプロンプトに記載し「オントロジーに従って、エンティティと関係を抽出して」と指示します。実際にはこれに加えてFew-shotという具体例の提示も大切です4。Few-shotでは、同義語として何を抽出するかを例示したり、オントロジーの定義の主旨にそって関連を強くしたいところは relationship_strength に高めのスコアをつけたりしています。
例として、JavaScriptのコードにおけるエンティティと関係抽出のプロンプトを示します。(プロンプトは読みやすいように適宜改行しています)
-
目標 与えられたJavaScriptのソースコードから、以下のオントロジーの定義に従ってカテゴリ、リソース、操作を抽出し、各エンティティの情報を整理します。
-
オントロジーの定義
@prefix ex: <http://example.com/> .
# エンティティの定義ex:リソース a rdfs:Class . # 情報の主体(例: データ構造、データクラス、引数、戻り値)ex:操作 a rdfs:Class . # 主に登録、照会、更新、削除、検索などのリソースに対する操作 (例: API、関数、メソッド)ex:カテゴリ a rdfs:Class . # リソースの分類 (例: フォルダ要素、ファイル、クラス、モジュール)
# プロパティの定義ex:操作を持つ a rdf:Property; rdfs:domain ex:リソース; rdfs:range ex:操作 .
ex:操作タイプ a rdf:Property; rdfs:domain ex:操作; rdfs:range rdfs:Literal .
ex:カテゴリを持つ a rdf:Property; rdfs:domain ex:リソース; rdfs:range ex:カテゴリ .
ex:親カテゴリ a rdf:Property; rdfs:domain ex:カテゴリ; rdfs:range ex:カテゴリ .
# 同義語の定義。エンティティそれぞれについて日本語名⇔名英語の関連づけ。ex:同義語 a rdf:Property; rdfs:domain rdfs:Class; rdfs:range rdfs:Class .- ステップ
-
全エンティティの特定 各特定したエンティティに対して、以下の情報を抽出します:
- entity_name: エンティティの名前。
- entity_type: 次のタイプのいずれか: [カテゴリ, リソース, 操作]
- entity_description: エンティティの属性と活動の詳細な説明
entity_typeに記載以外のタイプは抽出しないこと 各エンティティを次の形式でフォーマットします:
("entity"|<entity_name>|<entity_type>|<entity_description>)
- 専門用語によるリソース一覧: [意希物, yikimon]
-
エンティティ間の関係の特定 ステップ1で特定したエンティティから、明確に関連するエンティティのペアをすべて特定します。 各関連するエンティティのペアについて、以下の情報を抽出します:
- source_entity: ステップ1で特定されたソースエンティティの名前
- target_entity: ステップ1で特定されたターゲットエンティティの名前
- relationship_description: ソースエンティティとターゲットエンティティが関連している理由の説明
- relationship_strength: ソースエンティティとターゲットエンティティ間の関係の強さを示す1から10の整数スコア
各関係を次の形式でフォーマットします:
("relationship"|<source_entity>|<target_entity>|<relationship_description>|<relationship_strength>)
- 専門用語による関係一覧: 以下は同義語です[意希物, yikimon]
-
ステップ1およびステップ2で特定したすべてのエンティティと関係のリストを1つのリストにして「日本語で」返してください。リスト区切りは ## を使用します。
-
日本語への翻訳を行う時には、説明のみを翻訳し、他の部分はそのままとしてください。
-
完了時は <|COMPLETE|> を出力してください。
-
例 ######################
-
例1
entity_types: [カテゴリ, リソース, 操作]text:Filepath: src/calc/utils.js/** @module calc-utils *//** * 座標データ * @typedef {Object} Point * @property {number} x - X座標 * @property {number} y - Y座標 */
const Point = { x: 0, y: 0};
/** * 2つの座標を加算する * @function addPoints * @param {Point} point1 最初の座標 * @param {Point} point2 2番目の座標 * @returns {Point} 加算結果の座標 */function addPoints(point1, point2) { return { x: point1.x + point2.x, y: point1.y + point2.y };}
// 計算を行うクラスclass Calculator { // 2つの数値を乗算する multiply(a, b) { return a * b; }}
------------------------output:("entity"|"src"|"カテゴリ"|"ソースコードのルートディレクトリを示すフォルダ")##("entity"|"calc"|"カテゴリ"|"計算関連の処理をまとめたフォルダ")##("entity"|"utils.js"|"カテゴリ"|"補助的なユーティリティ操作を収めたファイル")##("entity"|"Calculator"|"カテゴリ"|"計算を実行するためのクラス")##("entity"|"addPoints"|"操作"|"2つの座標を加算するための関数")##("entity"|"multiply"|"操作"|"2つの数値を乗算するためのメソッド")##("entity"|"Point"|"リソース"|"座標データ")##("entity"|"座標"|"リソース"|"座標データを表す")##("entity"|"加算"|"操作"|"加算の目的を説明するためのコメント")##("entity"|"乗算"|"操作"|"乗算の目的を説明するためのコメント")##("entity"|"計算"|"カテゴリ"|"計算処理全体を表す概念")##("relationship"|"addPoints"|"ポイントの加算"|"同義語としての関係"|10)##("relationship"|"multiply"|"乗算"|"同義語としての関係"|10)##("relationship"|"Calculator"|"計算"|"同義語としての関係"|10)##("relationship"|"Point"|"座標"|"同義語としての関係"|10)##("relationship"|"Point"|"addPoints"|"PointリソースをaddPointsにより操作"|10)##("relationship"|"addPoints"|"utils"|"utils.jsで定義されているaddPoints関数"|7)##("relationship"|"multiply"|"Calculator"|"Calculatorクラスで提供される乗算メソッド"|7)##("relationship"|"Calculator"|"utils"|"utils内に存在するCalculatorクラス"|7)##("relationship"|"utils.js"|"calc"|"calcフォルダ内に配置されたutils.js"|7)##("relationship"|"calc"|"src"|"srcフォルダ内にあるcalcディレクトリ"|7)##("relationship"|"Point"|"utils"|"utils.js内に定義されているPointリソース"|7)##<|COMPLETE|>#############################
- 例2
entity_types: [カテゴリ, リソース, 操作]text:Filepath: src/utils/stringOperations.js/** @module utils-stringOperations */
/** * 文字列データを表すリソース * @typedef {Object} StringData * @property {string} value - 文字列の値 */
const StringData = { value: ""};
// 文字列を逆さにしますfunction reverseString(str) { return str.split('').reverse().join('');}
/** * 文字列操作を行うクラス */class StringManipulator { /** * 大文字に変換するメソッド * @param {string} str - 小文字の文字列 * @returns {string} - 大文字に変換された文字列 */ toUpperCase(str) { return str.toUpperCase(); }}
------------------------("entity"|"src"|"カテゴリ"|"ソースコードのルートディレクトリを示すフォルダ")##("entity"|"utils"|"カテゴリ"|"ユーティリティ操作を収めたフォルダ")##("entity"|"stringOperations"|"カテゴリ"|"文字列操作を行うファイル")##("entity"|"StringManipulator"|"カテゴリ"|"文字列操作を行うためのクラス")##("entity"|"reverseString"|"操作"|"文字列を逆さにする関数")##("entity"|"toUpperCase"|"操作"|"文字列を大文字に変換するメソッド")##("entity"|"StringData"|"リソース"|"文字列データを表すリソース")##("entity"|"文字列データ"|"リソース"|"文字列データを表す")##("entity"|"文字列を逆さに"|"操作"|"文字列を逆さにする目的を示すコメント")##("entity"|"文字列操作"|"カテゴリ"|"文字列操作全般を表す概念")##("entity"|"大文字に変換"|"操作"|"大文字に変換する目的を示すコメント")##("relationship"|"StringData"|"文字列データ"|"同義語としての関係"|10)##("relationship"|"toUpperCase"|"大文字に変換"|"同義語としての関係"|10)##("relationship"|"StringManipulator"|"文字列操作"|"同義語としての関係明"|10)##("relationship"|"reverseString"|"文字列を逆さに"|"同義語としての関係"|10)##("relationship"|"reverseString"|"stringOperations"|"stringOperations.jsで定義された関数"|7)##("relationship"|"toUpperCase"|"StringManipulator"|"StringManipulatorクラスで提供されるメソッド"|7)##("relationship"|"StringManipulator"|"stringOperations"|"stringOperations.js内に存在するクラス"|7)##("relationship"|"stringOperations"|"utils"|"utilsフォルダ内に配置されたstringOperations.js"|7)##("relationship"|"StringData"|"stringOperations"|"stringOperations.js内に定義されているリソース"|7)##<|COMPLETE|>#############################
- 実データ
######################entity_types: [カテゴリ, リソース, 操作]text: {input_text}######################output:その他、プロンプト作成時に考慮した点がいくつかあります。
考慮1: 異なるコンテキスト同士のドキュメントを結びつける
コードにおけるエンティティ抽出は、実装の中身よりも、コードコメントも含めてインターフェース等の宣言部分に注目するよう、プロンプトで指示しています。これはGraph RAG技術やナレッジグラフの話というよりも、開発プロセスのトレーサビリティの話になります。システム開発の工程間の情報伝達は、いわゆる「ドキュメントを使った伝言ゲーム」であり、例えば設計書とコードを結びつけるには、設計工程のどの情報を根拠として後続工程のコードを作成したかを辿れることが大切です。同様に「要件定義書」と「設計書」なら、設計書が根拠となる要件定義の参照先を示せることが求められます。堅牢なプロジェクトでは「IDを付与」などしてドキュメント同士のトレーサビリティを確保しています。
コードのどの部分がより設計書と結びつくかについては「インターフェースと実装の分離」というコードの役割に注目します。インターフェースの方が設計書の仕様とより太い結びつきをもつため、そこに着目してエンティティ抽出します。
graph TD;
style B1 fill:#bfb,stroke:#333,stroke-width:2px;
style A2 fill:#bfb,stroke:#333,stroke-width:2px;
subgraph 要件定義書
Y[要件]
end
subgraph 設計書
A1[機能インターフェース]
A2[機能仕様]
end
subgraph コード
B1[インターフェース]
B2[実装]
end
A1 <-->|関連| Y
B1 <-->|関連| A2
なお今回は対象外としましたが、コードの「実装」の役割に着目した細かい粒度でのエンティティ抽出も、解決したい課題によっては有効です。コードの言語のパーサーを用いて構文解析し、そこからノードとエッジを抽出する方法もあります。究極的には、LLMによる抽出や言語パーサーによる抽出といった異なる方法を用いることでより広く細かいグラフを作成する、という考え方もあるでしょう5。
考慮2: ドキュメントの階層構造もグラフの材料とする
ドキュメントが配置されるフォルダ階層構造自体に「カテゴリ」に関する情報があります。そこには作り手の分類したい意図があり有益な情報ですので、グラフに組み込むようプロンプトに指示します。
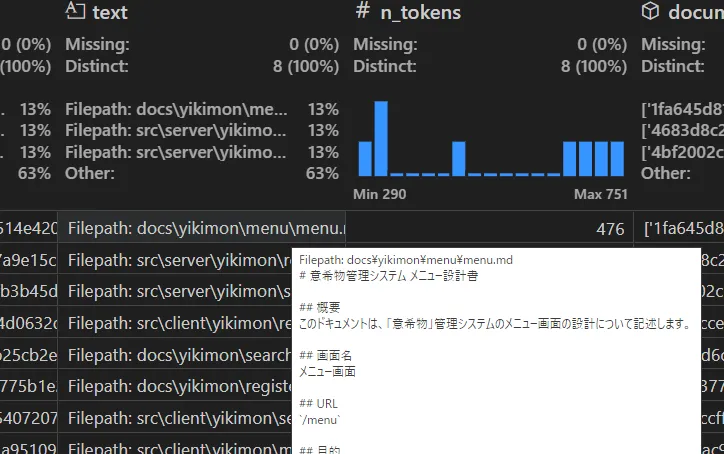
GraphRAGの構造の話となりますが、ドキュメントのメタ情報、例えばファイル名やパス、時刻や作成者などの情報をインデックスに組み込む仕組みは、デフォルトのGraphRAGには具備されていません。今回メタ情報の対応方法はGraphRAGのDiscussionで議論 ⧉されていたものを参考にしました。GraphRAGのコードを直接編集し、チャンク化されたテキストにすべてファイルパスを書くことで、最終的にグラフにカテゴリ情報を反映させています。
parquetファイルは以下のようになります。
create_final_documents.parquet:
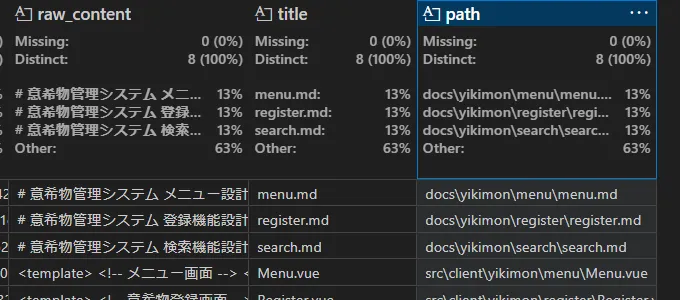
create_final_text_units.parquet:
考慮3: LLMに苦手な専門用語を理解させる
例えば「商品情報」や「搬入処理」など、LLMが既に持っていそうな普遍的な知識はLLMが文脈からそれを「リソース」や「処理」と認識することはできそうですが、いわゆる専門用語、ドメイン固有の名称を「リソース」や「処理」としてLLMに正しく認識させるのは課題です6 。対処法としてはプロンプトの中に専門用語を含める、In-context Learning や、ファインチューニング等で学習させる方法もあります。今回は前者を採用しています。
1. **全エンティティの特定** - 専門用語によるリソース一覧: [意希物, yikimon]
2. **エンティティ間の関係の特定** - 専門用語による関係一覧: 以下は同義語です[意希物, yikimon]結果の確認
グラフの構築を確認する
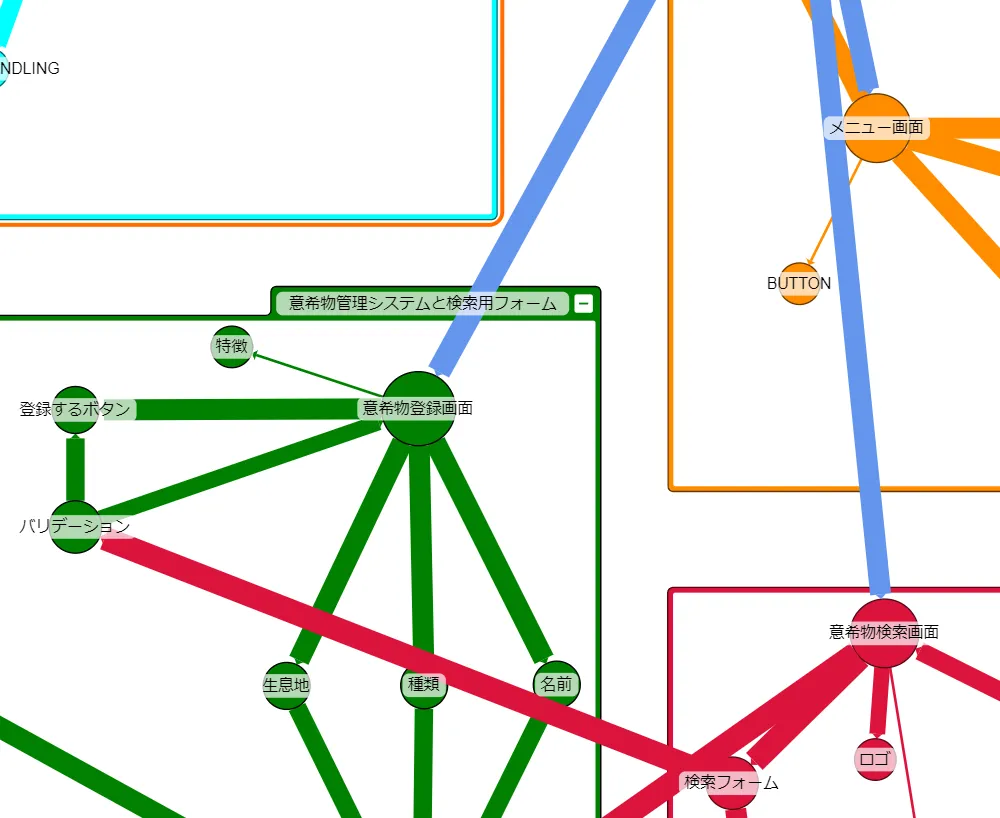
改善したプロンプトで構築したナレッジグラフが以下です。
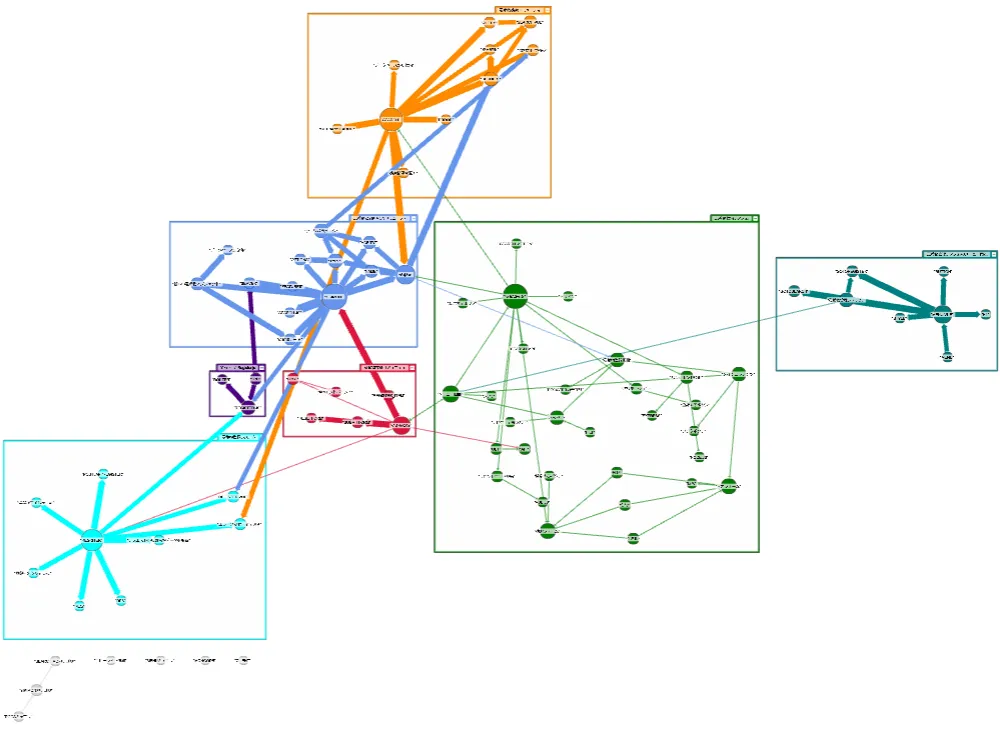
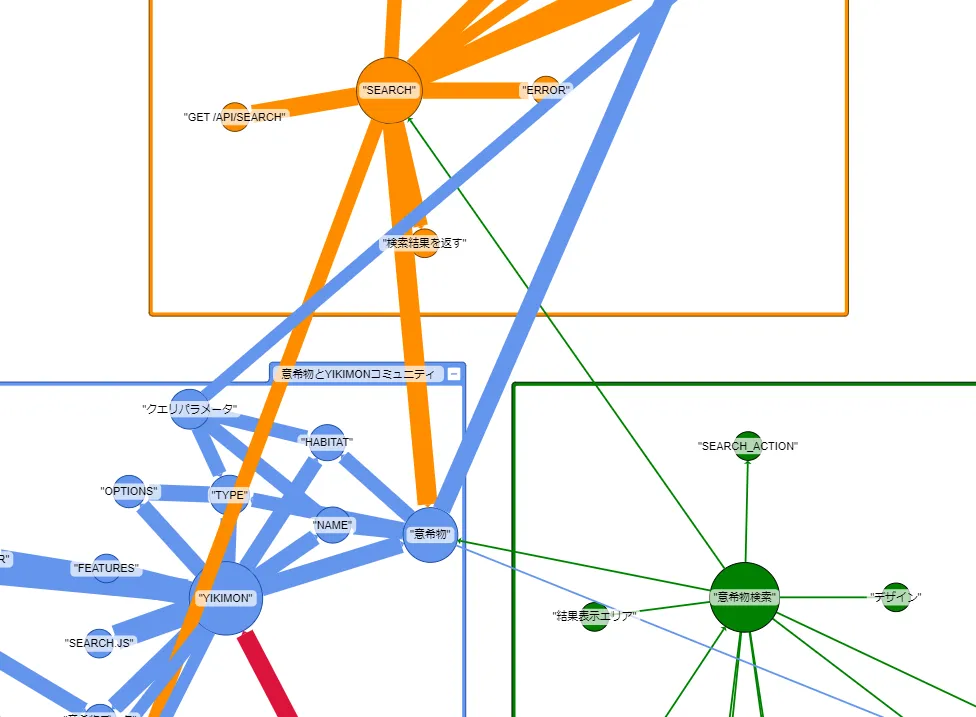
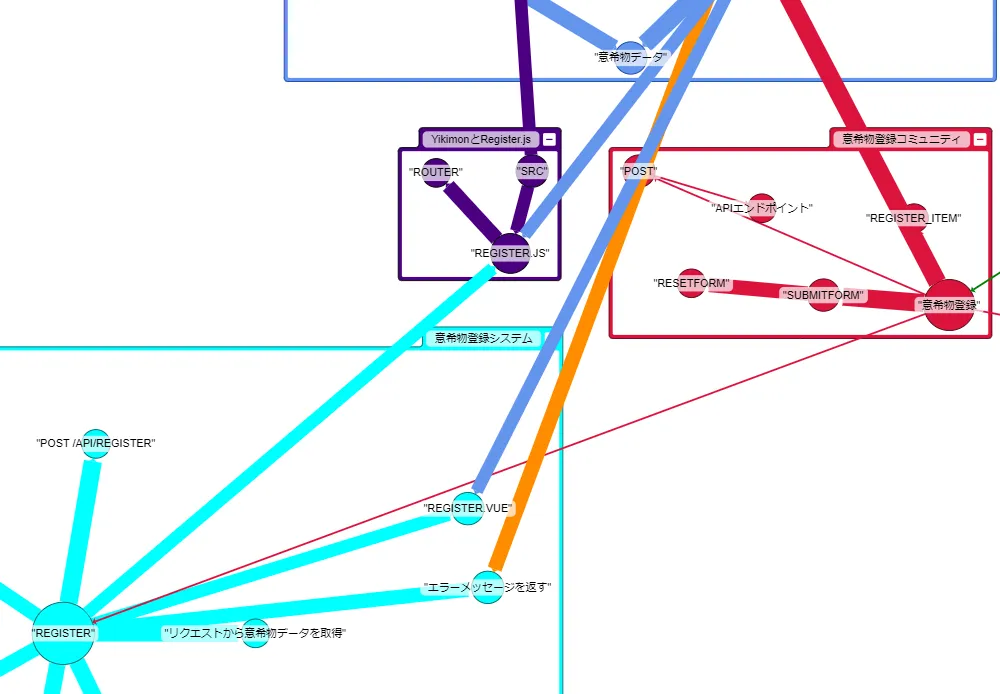
オントロジーの定義にそって作成されている傾向が見られます。
- システムの主要素である、リソースや処理を中心としたノードを中心として、グラフが構築できている
- 日本語とコードの英語(識別子)による同義語による結びつきできている
人間が情報を辿るときの思考の流れに沿ったグラフ構造になっているため、今後のグラフの探索方法にも依存しますが、知りたい情報へたどり着く土台はできています。
ドキュメント同士の関連付けができていることを確認する
ドキュメントの結びつきが、意図した通りにできているかを確認するため、別の視点でグラフを構築してみます。ドキュメントそれぞれをグラフ上のノードに見立て、関連の強さを可視化します。ドキュメントとドキュメントの関連の強さについて、ドキュメントに共通に存在するエンティティとそれをグラフにした時の degree(関連するノードの数の多さ)の加重和で示してみます。なおグラフを見やすくするために、「意希物」リソースなど全てのドキュメントとつながりを持つものはあえて省いています。
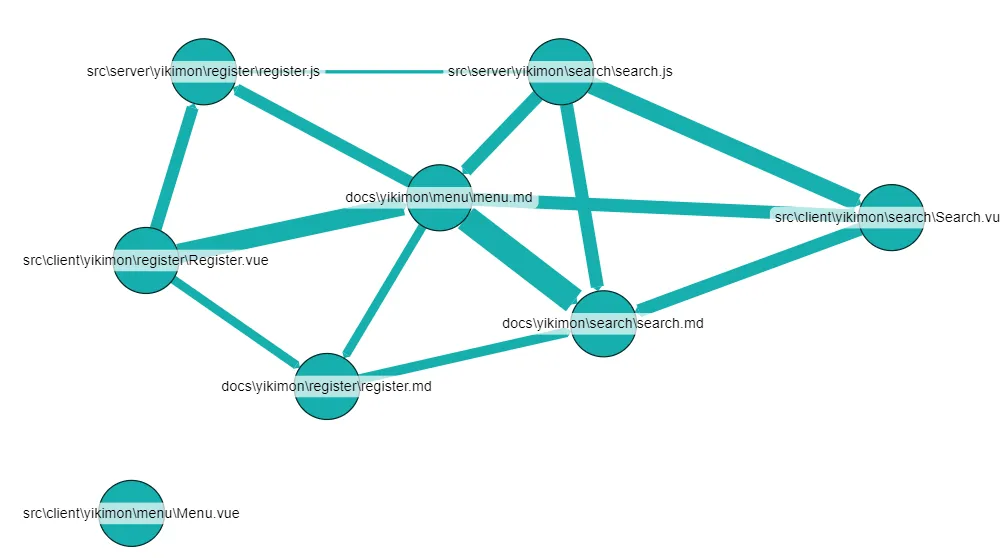
改善前はほとんどつながりは無かったのですが、改善後は登録や検索などのオントロジーの定義にそって、md, js, vue ファイルとつながりがあることが見て取れます。
クエリを出して確認する
自社システムのドキュメントを使って、ローカルサーチで、以下の問い合わせを行いました。
「検索処理の実装時に参考となる設計書やソースコードのファイルパス」
python -m graphrag.query --root . --data ./output_before_/artifacts --method local "検索処理の実装時に参考となる設計書やソースコードのファイルパス"直接の回答はここには書けませんが、GPT-4o による LLM-as-a-Judge させた結果を示します。回答①が改善前、回答②が改善後のものです。
回答①と回答②を比較すると、以下の点で回答②がより有効な回答と考えられます。
内容の具体性と詳細さ
- 回答①:
- 設計書とソースコードのファイルパスのみの提示。
- 各ファイルの具体的な内容やそれがどのように役立つのかについての詳細が少ない。
- 回答②:
- 各ファイルの具体的な内容と目的が明確に記載されている。
- 特に、設計書やソースコードがどのような処理や機能に関連しているのか、具体的な機能や実装についての詳細な説明がある。
構造と可読性
- 回答②は、段階的かつ体系的に情報を提供しており、ユーザーがどのファイルを参照すべきかを容易に判断できる。
有用性
- 回答②は、各ファイルがどのような場面で役立つか、また具体的な機能についての記述があるため、利用価値が高い。
これらの点から、回答②の方が実用的で、質問者が求める情報をより効果的に提供していると判断できます。
さいごに
GraphRAGを用いて、システム開発のドキュメント活用のユースケースで、効果的なインデックス作成について検討しました。GraphRAGの性能を上げる要因の一つとして対象領域や利用目的に沿ったグラフの存在が大切であり、そのためにオントロジー定義などの手段を用いてグラフ構築をコントロールするというものです。
今回やりきれなかった課題としては以下があります。
- ドメイン特化させるカスタマイズコストを減らせないか
- オントロジーの定義やFew-shotを含めたプロンプトをいかに人の手を排除してLLMに効率的に作成させるか
- 作成グラフに対しての評価をいかに定量的に行うか
- 推論ロジックをどのように組みたてて総合的な性能向上に結び付けるか
- 前回のブログでも述べたドキュメント更新など運用時の課題
我々と同じようにGraphRAGやGraph RAG技術の実用化に向けて検討されている方に向け、お役に立てれば幸いです。
付録
可視化ツールの変更ポイント
コミュニティの可視化
graph-visualization.ipynb ⧉ に以下を追加します。
from yfiles_jupyter_graphs import GraphWidget
# read community reportscommunity_report_df = pd.read_parquet(f"{INPUT_DIR}/{COMMUNITY_REPORT_TABLE}.parquet")
# converts the entities dataframe to a list of dicts for yfiles-jupyter-graphsdef convert_entities_to_dicts(df): """Convert the entities dataframe to a list of dicts for yfiles-jupyter-graphs.""" nodes_dict = {} communities_dict = {} for _, row in df.iterrows(): # Create a dictionary for each row and collect unique nodes node_id = row["title"] community_id = row["community"] level = row["level"] if level == COMMUNITY_LEVEL and node_id not in nodes_dict: nodes_dict[node_id] = { "id": node_id, "properties": row.to_dict(), } if community_id is not None and community_id not in communities_dict: for _, c_row in community_report_df.iterrows(): if c_row["community"] == community_id and c_row["level"] == COMMUNITY_LEVEL: communities_dict[community_id] = { "id": community_id, "properties": { "title": c_row["title"], "label": community_id, "summary": c_row["summary"], "full_content": c_row["full_content"], "level": c_row["level"], "community": int(community_id), "size": 3 } } return list(nodes_dict.values()) + list(communities_dict.values())
# converts the relationships dataframe to a list of dicts for yfiles-jupyter-graphsdef convert_relationships_to_dicts(df): """Convert the relationships dataframe to a list of dicts for yfiles-jupyter-graphs.""" relationships = [] for _, row in df.iterrows(): # Create a dictionary for each row relationships.append({ "start": row["source"], "end": row["target"], "properties": row.to_dict(), }) return relationships
w = GraphWidget()w.directed = True
## test for groupingw.node_parent_mapping = "community"##
w.nodes = convert_entities_to_dicts(entity_df)w.edges = convert_relationships_to_dicts(relationship_df)ドキュメントの連携の可視化
graph-visualization.ipynb ⧉ をコピーし'Load tables to dataframes' 以降を書き換えていきます。
import datetimefrom pathlib import Pathfrom yfiles_jupyter_graphs import GraphWidget
base_dir = "../../../ragtest/output"folders = [f for f in os.listdir(base_dir) if Path.is_dir(Path(base_dir) / f)]latest_folder = max(folders, key=lambda f: datetime.datetime.strptime(f, "%Y%m%d-%H%M%S").astimezone(datetime.timezone.utc))INPUT_DIR = Path(base_dir) / latest_folder / "artifacts"print(INPUT_DIR)LANCEDB_URI = f"{INPUT_DIR}/lancedb"
COMMUNITY_REPORT_TABLE = "create_final_community_reports"ENTITY_TABLE = "create_final_nodes"ENTITY_EMBEDDING_TABLE = "create_final_entities"RELATIONSHIP_TABLE = "create_final_relationships"COVARIATE_TABLE = "create_final_covariates"TEXT_UNIT_TABLE = "create_final_text_units"COMMUNITY_LEVEL = 0
# read nodes table to get community and degree dataentity_df = pd.read_parquet(f"{INPUT_DIR}/{ENTITY_TABLE}.parquet")entity_embedding_df = pd.read_parquet(f"{INPUT_DIR}/{ENTITY_EMBEDDING_TABLE}.parquet")
relationship_df = pd.read_parquet(f"{INPUT_DIR}/{RELATIONSHIP_TABLE}.parquet")relationships = read_indexer_relationships(relationship_df)
documents_df = pd.read_parquet(f"{INPUT_DIR}/create_final_documents.parquet")text_units_df = pd.read_parquet(f"{INPUT_DIR}/create_final_text_units.parquet")
# Map Text Units to Documentstext_unit_to_doc = {}for _, row in text_units_df.iterrows(): for doc_id in row['document_ids']: text_unit_to_doc[row['id']] = doc_id
# Find document connections via entitiesdoc_connections = {}for _, row in entity_embedding_df.iterrows(): for tu_id in row["text_unit_ids"]: if tu_id in text_unit_to_doc: source_doc = text_unit_to_doc[tu_id] for target_id in row["text_unit_ids"]: if target_id in text_unit_to_doc: target_doc = text_unit_to_doc[target_id] if source_doc != target_doc: if (source_doc, target_doc) not in doc_connections and (target_doc, source_doc) not in doc_connections: doc_connections[(source_doc, target_doc)] = {"entities": [], "weight": 0} for e_, e_row in entity_df.iterrows(): if row["name"] == e_row["title"]: if (source_doc, target_doc) not in doc_connections: if e_row["title"] not in doc_connections[(target_doc, source_doc)]["entities"]: doc_connections[(target_doc, source_doc)]["entities"].append(e_row["title"]) doc_connections[(target_doc, source_doc)]["weight"] += e_row["degree"] else: if e_row["title"] not in doc_connections[(source_doc, target_doc)]["entities"]: doc_connections[(source_doc, target_doc)]["entities"].append(e_row["title"]) doc_connections[(source_doc, target_doc)]["weight"] += e_row["degree"]
# converts the entities dataframe to a list of dicts for yfiles-jupyter-graphsdef convert_entities_to_dicts(df): """Convert the entities dataframe to a list of dicts for yfiles-jupyter-graphs.""" nodes_dict = {} for _, row in df.iterrows(): # Create a dictionary for each row and collect unique nodes node_id = row["id"] if node_id not in nodes_dict: nodes_dict[node_id] = { "id": node_id, "properties": row.to_dict(), } return list(nodes_dict.values())
# converts the relationships dataframe to a list of dicts for yfiles-jupyter-graphsdef convert_doc_conn_to_dicts(doc_conn): """Convert the relationships dataframe to a list of dicts for yfiles-jupyter-graphs.""" relationships = [] for key in doc_conn.keys(): # Create a dictionary for each row relationships.append({ "start": key[0], "end": key[1], "properties": { "entities": doc_conn[key]["entities"], "weight": doc_conn[key]["weight"], } }) return relationships
w = GraphWidget()w.directed = True
w.nodes = convert_entities_to_dicts(documents_df)w.edges = convert_doc_conn_to_dicts(doc_connections)
w.node_scale_factor_mapping = lambda node: 1w.edge_thickness_factor_mapping = lambda edge: 0.5 + edge["properties"]["weight"] * 1.5 / 20
w.organic_layout()
display(w)参考情報
検討、執筆にあたり、参考にさせていただきました情報です。
- ナレッジグラフに関する書籍
- マイナビブックス - はじめての知識グラフ構築ガイド ⧉
- やはり基礎技術が大事です。Neo4jの中の人が書いており、分かりやすいです。
- マイナビブックス - はじめての知識グラフ構築ガイド ⧉
- GraphRAGに関する情報
- Microsoft GraphRAG でこれまでの RAG にはできなかった質問に回答させるメモ ⧉
- クエリやクラスタリング、コミュニティについて詳しく言及されており、参考になります。
- Microsoft GraphRAG でこれまでの RAG にはできなかった質問に回答させるメモ ⧉
- Graph RAG技術に関する情報
- Neo4j Developer Blog tagged: graphrag ⧉
- Neo4jサイトにある情報はさすがの本家本元。重要な情報がてんこ盛りです。
- GraphRAG Field Guide: Navigating the World of Advanced RAG Patterns ⧉
- RAGに効果があるナレッジグラフの構築のパターンを網羅しています。特に、テキストチャンク、エンティティ、LLMによって導出されたテキスト(要約やコミュニティ、質問など)の組み合わせはこんなにパターンがあるのかと驚きです。
- ナレッジセンス - AI知見共有ブログ - RAGで人間の脳を再現。「HippoRAG」を理解する ⧉ で紹介されました、HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models ⧉
- ナレッジグラフと人間の思考の流れが同じであることに共感する内容でした。
- Neo4j Developer Blog tagged: graphrag ⧉
- オントロジーに関する情報
- Ontologies in Neo4j: Semantics and Knowledge Graphs ⧉
- Going Meta – S02 Ep01: Using Ontologies to Guide Knowledge Graph Creation from Unstructured Data ⧉, Going Meta – S02 Ep02: Using Ontologies to Guide Knowledge Graph Creation Part 2 ⧉
- RAG on Graph using Fixed Entity Architecture: make you retrieval work for you ⧉
Ontological Fishboneと呼ばれるオントロジーの定義を骨組み(魚の骨)とし実際にグラフに体現し、その周辺に関連エンティティを紐づけてナレッジグラフを構築する手法です。
Footnotes
-
度々議論に挙がるほぼプログラムと一対一である詳細設計書は、英語ネイティブにとっては存在意義があまりないと思われるほど、英語に対するコンプレックスは根深い問題です。一説によると、英語ネイティブな人はプログラムを見ると、あたかもそこに文章が書かれているように見えるとのこと。うらやましい限りですね。 ↩
-
現状のgraphragモジュールはそれらのカスタマイズができないため、今回はファイルの拡張子で判別してプロンプトを選択するよう、モジュールのコードを直接書き換えて対応しています。 ↩
-
オントロジーを始めとしてナレッジグラフについてはNeo4jのサイトの記事や動画が参考になります。参考情報をご参照ください。 ↩
-
こう書きましたが正直このあたりは試行錯誤です。正確にはFew-shotだけでは期待したグラフが構築できず、オントロジーで改善傾向が見られた、という流れです。 ↩
-
ナレッジグラフでは、枝の先の方へ階層化して細分化していくことを、タクソノミーと呼びます。 ↩
-
固有表現抽出(NER: Named Entity Recognition)という話題に属します。 ↩
記事の執筆にあたっては情報の正確性に努めておりますが、掲載されている文章やソースコード、設定ファイル等の内容について、完全な正確性や安全性を保証するものではありません。活用される際は、必ず公式ドキュメント等をご自身で確認のうえご判断ください。
